


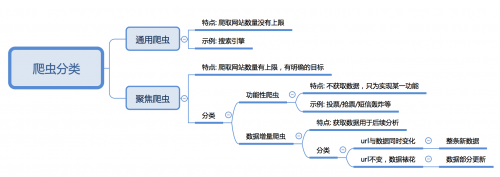
通用爬蟲:
通用網(wǎng)絡(luò)爬蟲從互聯(lián)網(wǎng)中搜集網(wǎng)頁,采集信息,這些網(wǎng)頁信息決定著整個(gè)引擎系統(tǒng)的內(nèi)容是否豐富,信息是否即時(shí),因此其性能的優(yōu)劣直接影響著搜索引擎的效果
大家要注意哦,通用爬蟲雖然簡單,方便,但是缺點(diǎn)也是顯而易見的,小助手給大家列舉了幾點(diǎn),大家可以了解一下:
a.通用搜索引擎所返回的結(jié)果都是網(wǎng)頁,而大多情況下,網(wǎng)頁里90%的內(nèi)容對用戶來說都是無用的。
b.不同領(lǐng)域、不同背景的用戶往往具有不同的檢索目的和需求,搜索引擎無法提供針對具體某個(gè)用戶的搜索結(jié)果。
c.萬維網(wǎng)數(shù)據(jù)形式的豐富和網(wǎng)絡(luò)技術(shù)的不斷發(fā)展,圖片、數(shù)據(jù)庫、音頻、視頻多媒體等不同數(shù)據(jù)大量出現(xiàn),通用搜索引擎對這些文件無能為力,不能很好地發(fā)現(xiàn)和獲取。
d.通用搜索引擎大多提供基于關(guān)鍵字的檢索,難以支持根據(jù)語義信息提出的查詢,無法準(zhǔn)確理解用戶的具體需求。
聚焦爬蟲:
聚焦爬蟲,是"面向特定主題需求"的一種網(wǎng)絡(luò)爬蟲程序,它與通用搜索引擎爬蟲的區(qū)別在于: 聚焦爬蟲在實(shí)施網(wǎng)頁抓取時(shí)會對內(nèi)容進(jìn)行處理篩選,盡量保證只抓取與需求相關(guān)的網(wǎng)頁信息, 如12306搶票,或?qū)iT抓取某一個(gè)(某一類)網(wǎng)站數(shù)據(jù)
根據(jù)是否以獲取數(shù)據(jù)為目的,可以分為:
• 功能性爬蟲,給你喜歡的明星投票、點(diǎn)贊
• 數(shù)據(jù)增量爬蟲,比如招聘信息
根據(jù)url地址和對應(yīng)的頁面內(nèi)容是否改變,數(shù)據(jù)增量爬蟲可以分為:
• 基于url地址變化、內(nèi)容也隨之變化的數(shù)據(jù)增量爬蟲
• url地址不變、內(nèi)容變化的數(shù)據(jù)增量爬蟲














 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號