


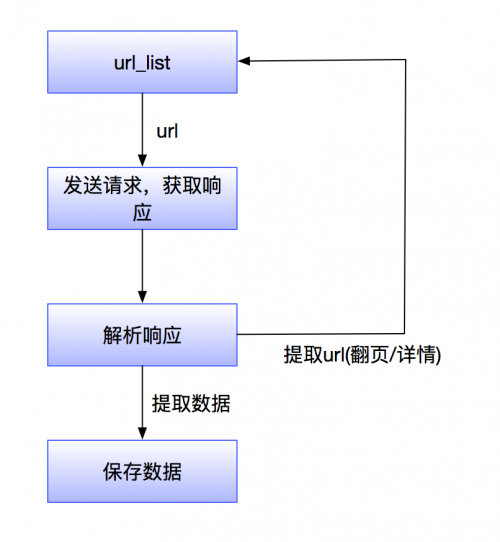
第一步:爬取數(shù)據(jù),實際上就是根據(jù)一個網(wǎng)址向服務器發(fā)起網(wǎng)絡請求,獲取到服務器返回的數(shù)據(jù)
第二步:解析數(shù)據(jù),將服務器返回的數(shù)據(jù)轉(zhuǎn)換為人容易理解的樣式
第三步:篩選數(shù)據(jù),從大量的數(shù)據(jù)中篩選出需要的數(shù)據(jù)
第四步:存儲數(shù)據(jù),將篩選出來的有用的數(shù)據(jù)存儲起來,如:數(shù)據(jù)庫,CSV文件,Excel文件,JSON文件等
只要小伙伴們按照這四個步驟操作,實現(xiàn)一個爬蟲任務還是很簡單的














 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號