


ApacheSpark與 Apache Hadoop數(shù)據(jù)科學(xué)工具有哪些區(qū)別?Apache Spark被設(shè)計(jì)為大規(guī)模處理的接口,而 Apache Hadoop 為大數(shù)據(jù)的分布式存儲(chǔ)和處理提供了更廣泛的軟件框架。兩者既可以一起使用也可以作為獨(dú)立服務(wù)使用。Apache Spark 和 Apache Hadoop 都是 Apache 軟件基金會(huì)提供的流行的開源數(shù)據(jù)科學(xué)工具,由社區(qū)開發(fā)和支持受歡迎程度和功能不斷增長。
1、Apache Spark是什么?
Apache Spark 是一個(gè)為高效、大規(guī)模數(shù)據(jù)分析而構(gòu)建的開源數(shù)據(jù)處理引擎。Apache Spark 是一個(gè)強(qiáng)大的統(tǒng)一分析引擎,數(shù)據(jù)科學(xué)家經(jīng)常使用它來支持機(jī)器學(xué)習(xí)算法和復(fù)雜的數(shù)據(jù)分析。Apache Spark 可以獨(dú)立運(yùn)行,也可以作為 Apache Hadoop 之上的軟件包運(yùn)行。
2、Apache Hadoop是什么?
Apache Hadoop 是一組開源模塊和實(shí)用程序,旨在簡化存儲(chǔ)、管理和分析大數(shù)據(jù)的過程。Apache Hadoop 的模塊包括 Hadoop YARN、HadoopMapReduce 和 Hadoop Ozone,但它支持許多可選的數(shù)據(jù)科學(xué)軟件包。Apache Hadoop 可以互換使用來指代 Apache Spark 和其他數(shù)據(jù)科學(xué)工具。
3、Apache Spark 與 Apache Hadoop有哪些區(qū)別
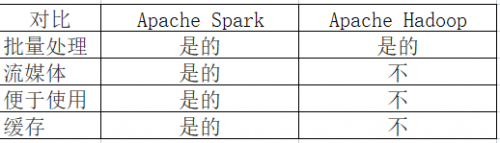
4、設(shè)計(jì)和架構(gòu)區(qū)別
Apache Spark 是一個(gè)離散的開源數(shù)據(jù)處理實(shí)用程序。通過 Spark,開發(fā)人員可以訪問用于數(shù)據(jù)處理集群編程的輕量級接口,具有內(nèi)置的容錯(cuò)和數(shù)據(jù)并行性。Apache Spark 是用 Scala 編寫的,主要用于機(jī)器學(xué)習(xí)應(yīng)用程序。
Apache Hadoop 是一個(gè)更大的框架,其中包括 Apache Spark、Apache Pig、ApacheHive和 Apache Phoenix 等實(shí)用程序。作為一種更通用的解決方案,Apache Hadoop 為數(shù)據(jù)科學(xué)家提供了一個(gè)完整且強(qiáng)大的軟件平臺(tái),然后他們可以根據(jù)個(gè)人需求進(jìn)行擴(kuò)展和定制。
5、使用范圍
Apache Spark 的范圍僅限于它自己的工具,包括 Spark Core、Spark SQL 和 Spark Streaming。Spark Core 提供了 Apache Spark 的大部分?jǐn)?shù)據(jù)處理。Spark SQL支持額外的數(shù)據(jù)抽象層,開發(fā)人員可以通過它構(gòu)建結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù)。Spark Streaming 利用 Spark Core 的調(diào)度服務(wù)來執(zhí)行流分析。
Apache Hadoop 的范圍要廣泛得多。除了 Apache Spark,Apache Hadoop 的開源實(shí)用程序還包括pache Phoenix。一個(gè)大規(guī)模并行的關(guān)系數(shù)據(jù)庫引擎。
(1)Apache Zookeeper.。用于云應(yīng)用程序的協(xié)調(diào)分布式服務(wù)器。
(2)pache Hive。用于數(shù)據(jù)查詢和分析的數(shù)據(jù)倉庫。
(3)Apache Flume。分布式日志數(shù)據(jù)的倉儲(chǔ)解決方案。
但是出于數(shù)據(jù)科學(xué)的目的,并非所有應(yīng)用程序都如此廣泛。速度、延遲和強(qiáng)大的處理能力在大數(shù)據(jù)處理和分析領(lǐng)域中至關(guān)重要——獨(dú)立安裝的 Apache Spark 可能更容易提供這些。
6、速度
對于大多數(shù)實(shí)現(xiàn),Apache Spark 將比 Apache Hadoop 快得多。Apache Spark 專為速度而打造,其速度可能比 Apache Hadoop 快近 100 倍。然而,這是因?yàn)?Apache Spark 更簡單、更輕量級。
默認(rèn)情況下,Apache Hadoop 不會(huì)像 Apache Spark 一樣快。但是,其性能可能會(huì)因安裝的軟件包以及所涉及的數(shù)據(jù)存儲(chǔ)、維護(hù)和分析工作而異。
7、學(xué)習(xí)曲線
由于其關(guān)注點(diǎn)相對狹窄,Apache Spark 更容易學(xué)習(xí)。Apache Spark 有一些核心模塊,并為數(shù)據(jù)的操作和分析提供了一個(gè)干凈、簡單的界面。由于 Apache Spark 是一個(gè)相當(dāng)簡單的產(chǎn)品,因此學(xué)習(xí)曲線很短。
Apache Hadoop 要復(fù)雜得多。參與的難度將取決于開發(fā)人員如何安裝和配置 Apache Hadoop 以及開發(fā)人員選擇包含哪些軟件包。無論如何,即使開箱即用,Apache Hadoop 的學(xué)習(xí)曲線也更為顯著。
8、安全性和容錯(cuò)性
當(dāng)作為獨(dú)立產(chǎn)品安裝時(shí),Apache Spark 的開箱即用安全性和容錯(cuò)功能少于 Apache Hadoop。但是,Apache Spark 可以訪問許多與 Apache Hadoop 相同的安全實(shí)用程序,例如 Kerberos 身份驗(yàn)證——它們只需要安裝和配置即可。
Apache Hadoop 具有更廣泛的本機(jī)安全模型,并且在設(shè)計(jì)上具有廣泛的容錯(cuò)性。與 Apache Spark 一樣,它的安全性可以通過其他 Apache 實(shí)用程序進(jìn)一步提高。
9、編程語言
Apache Spark 支持 Scala、Java、SQL、Python、R、C# 和 F#。它最初是在 Scala 中開發(fā)的。Apache Spark 支持?jǐn)?shù)據(jù)科學(xué)家使用的幾乎所有流行語言。
Apache Hadoop 是用 Java 編寫的,部分是用 C 編寫的。Apache Hadoop 實(shí)用程序支持其他語言,使其適合所有技能的數(shù)據(jù)科學(xué)家。
10、在 Apache Spark 與 Hadoop 之間進(jìn)行選擇
如果您是主要從事機(jī)器學(xué)習(xí)算法和大規(guī)模數(shù)據(jù)處理的數(shù)據(jù)科學(xué)家,請選擇 Apache Spark。
Apache Spark:
(1)在沒有 Apache Hadoop 的情況下作為獨(dú)立實(shí)用程序運(yùn)行。
(2)提供分布式任務(wù)調(diào)度、I/O功能和調(diào)度。
(3)支持多種語言,包括 Java、Python 和 Scala。
(4)提供隱式數(shù)據(jù)并行性和容錯(cuò)性。
如果您是需要大量數(shù)據(jù)科學(xué)實(shí)用程序來存儲(chǔ)和處理大數(shù)據(jù)的數(shù)據(jù)科學(xué)家,請選擇 Apache Hadoop。
Apache Hadoop:
(1)為大數(shù)據(jù)的存儲(chǔ)和處理提供廣泛的框架。
(2)提供了一系列令人難以置信的軟件包,包括 Apache Spark。
(3)建立在分布式、可擴(kuò)展和可移植的文件系統(tǒng)之上。
(4)利用其他應(yīng)用程序進(jìn)行數(shù)據(jù)倉庫、機(jī)器學(xué)習(xí)和并行處理。
更多關(guān)于大數(shù)據(jù)培訓(xùn)的問題,歡迎咨詢千鋒教育在線名師。千鋒教育擁有多年IT培訓(xùn)服務(wù)經(jīng)驗(yàn),采用全程面授高品質(zhì)、高體驗(yàn)培養(yǎng)模式,擁有國內(nèi)一體化教學(xué)管理及學(xué)員服務(wù),助力更多學(xué)員實(shí)現(xiàn)高薪夢想。














 京公網(wǎng)安備 11010802030320號(hào)
京公網(wǎng)安備 11010802030320號(hào)