


從幾個方面回答,比如:
插件式存儲引擎架構
實現了Server層和存儲引擎層的解耦,可以支持多種存儲引擎,如MySQL既可以支持B-Tree結構的InnoDB存儲引擎,還可以支持LSM結構的RocksDB存儲引擎。
B-Tree + Page
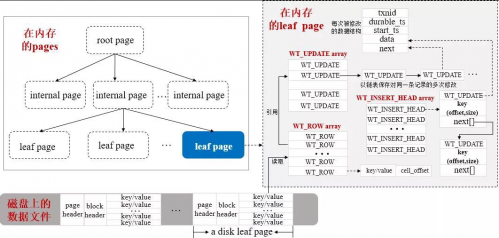
上圖是WiredTiger在內存里面的大概布局圖,通過它我們可梳理清楚存儲引擎是如何將數據加載到內存,然后如何通過相應數據結構來支持查詢、插入、修改操作的。
內存里面B-Tree包含三種類型的page,即rootpage、internal page和leaf page,前兩者包含指向其子頁的page index指針,不包含集合中的真正數據,leaf page包含集合中的真正數據即keys/values和指向父頁的home指針;
為什么是Page?
數據以page為單位加載到cache、cache里面又會生成各種不同類型的page及為不同類型的page分配不同大小的內存、eviction觸發機制和reconcile動作都發生在page上、page大小持續增加時會被分割成多個小page,所有這些操作都是圍繞一個page來完成的。
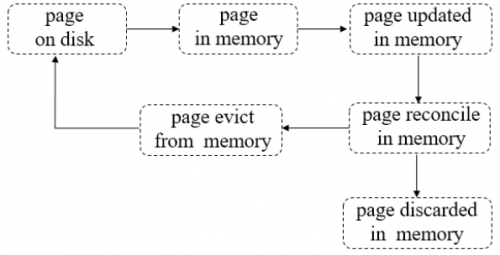
Page的典型生命周期如下圖所示:
什么是CheckPoint?
本質上來說,Checkpoint相當于一個日志,記錄了上次Checkpoint后相關數據文件的變化。作用: 一是將內存里面發生修改的數據寫到數據文件進行持久化保存,確保數據一致性; 二是實現數據庫在某個時刻意外發生故障,再次啟動時,縮短數據庫的恢復時間,WiredTiger存儲引擎中的Checkpoint模塊就是來實現這個功能的。
一個Checkpoint包含關鍵信息如下圖所示:
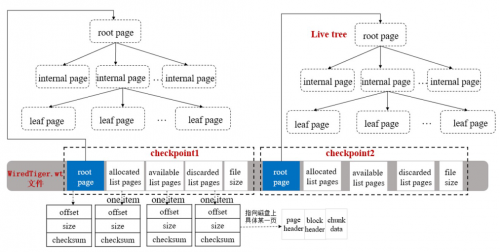
每個checkpoint包含一個root page、三個指向磁盤具體位置上pages的列表以及磁盤上文件的大小。
如何理解WT事務機制?
要了解實現先要知道它的事務的構造和使用相關的技術,WT在實現事務的時使用主要是使用了三個技術:snapshot(事務快照)、MVCC (多版本并發控制)和redo log(重做日志),為了實現這三個技術,它還定義了一個基于這三個技術的事務對象和全局事務管理器。
如何理解WT緩存淘汰?
eviction cache是一個LRU cache,即頁面置換算法緩沖區,它對數據頁采用的是分段局部掃描和淘汰,而不是對內存中所有的數據頁做全局管理。基本思路是一個線程階段性的去掃描各個btree,并把btree可以進行淘汰的數據頁添加到一個lru queue中,當queue填滿了后記錄下這個過程當前的btree對象和btree的位置(這個位置是為了作為下次階段性掃描位置),然后對queue中的數據頁按照訪問熱度排序,最后各個淘汰線程按照淘汰優先級淘汰queue中的數據頁,整個過程是周期性重復。WT的這個evict過程涉及到多個eviction thread和hazard pointer技術。
WT的evict過程都是以page為單位做淘汰,而不是以K/V。這一點和memcache、redis等常用的緩存LRU不太一樣,因為在磁盤上數據的最小描述單位是page block,而不是記錄。















 京公網安備 11010802030320號
京公網安備 11010802030320號