


ConcurrentHashMap 和 Hashtable 的區(qū)別主要體現(xiàn)在實現(xiàn)線程安全的方式上不同。
1. 底層數(shù)據(jù)結(jié)構(gòu): JDK1.7的 ConcurrentHashMap 底層采用 分段的數(shù)組+鏈表 實現(xiàn),JDK1.8 采用的數(shù)據(jù)結(jié)構(gòu)跟HashMap1.8的結(jié)構(gòu)一樣,數(shù)組+鏈表/紅黑二叉樹。Hashtable 和 JDK1.8 之前的 HashMap 的底層數(shù)據(jù)結(jié)構(gòu)類似都是采用 數(shù)組+鏈表 的形式,數(shù)組是 HashMap 的主體,鏈表則是主要為了解決哈希沖突而存在的;
2. 實現(xiàn)線程安全的方式:
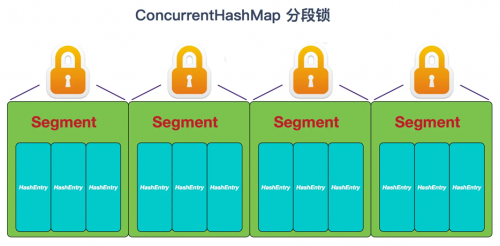
① 在JDK1.7的時候,ConcurrentHashMap(分段鎖) 對整個桶數(shù)組進(jìn)行了分割分段(Segment),每一把鎖只鎖容器其中一部分?jǐn)?shù)據(jù),多線程訪問容器里不同數(shù)據(jù)段的數(shù)據(jù),就不會存在鎖競爭,提高并發(fā)訪問率。(默認(rèn)分配16個Segment,比Hashtable效率提高16倍。) 到了 JDK1.8 的時候已經(jīng)摒棄了Segment的概念,而是直接用 Node 數(shù)組+鏈表+紅黑樹的數(shù)據(jù)結(jié)構(gòu)來實現(xiàn),并發(fā)控制使用 synchronized 和 CAS 來操作。(JDK1.6以后 對 synchronized鎖做了很多優(yōu)化) 整個看起來就像是優(yōu)化過且線程安全的 HashMap,雖然在JDK1.8中還能看到 Segment 的數(shù)據(jù)結(jié)構(gòu),但是已經(jīng)簡化了屬性,只是為了兼容舊版本;
② Hashtable(同一把鎖) :使用 synchronized 來保證線程安全,效率非常低下。當(dāng)一個線程訪問同步方法時,其他線程也訪問同步方法,可能會進(jìn)入阻塞或輪詢狀態(tài),如使用 put 添加元素,另一個線程不能使用 put 添加元素,也不能使用 get,競爭會越來越激烈效率越低。
3. 兩者的對比圖:
①HashTable:
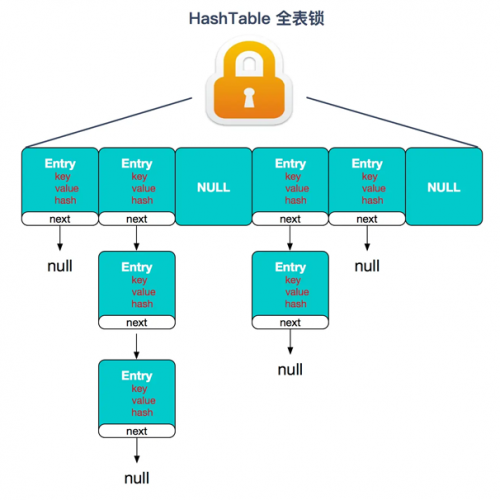
② JDK1.7的ConcurrentHashMap:
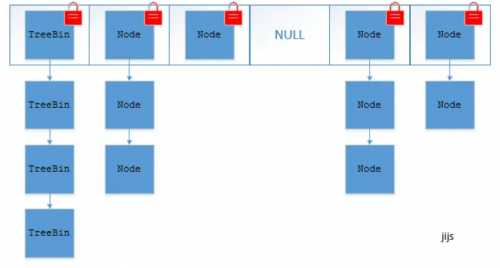
③ JDK1.8的ConcurrentHashMap(TreeBin: 紅黑二叉樹節(jié)點(diǎn) Node: 鏈表節(jié)點(diǎn)):
ConcurrentHashMap 結(jié)合了 HashMap 和 HashTable 二者的優(yōu)勢。HashMap 沒有考慮同步,HashTable 考慮了同步的問題使用了synchronized 關(guān)鍵字,所以 HashTable 在每次同步執(zhí)行時都要鎖住整個結(jié)構(gòu)。 ConcurrentHashMap 鎖的方式是稍微細(xì)粒度的。















 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號