


首先分庫分表分為垂直和水平兩個方式,一般來說我們拆分的順序是先垂直后水平。
垂直分庫
基于現在微服務拆分來說,都是已經做到了垂直分庫了
垂直分表
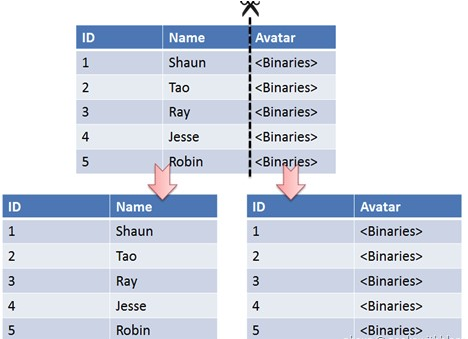
垂直切分是將一張表按列切分成多個表,通常是按照列的關系密集程度進行切分,也可以利用垂直切分將經常被使用的列和不經常被使用的列切分到不同的表中。
在數據庫的層面使用垂直切分將按數據庫中表的密集程度部署到不同的庫中,例如將原來的電商數據庫垂直切分成商品數據庫、用戶數據庫等。
水平分表
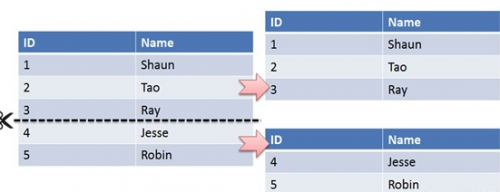
首先根據業務場景來決定使用什么字段作為分表字段(sharding_key),比如我們現在日訂單1000萬,我們大部分的場景來源于C端,我們可以用user_id作為sharding_key,數據查詢支持到最近3個月的訂單,超過3個月的做歸檔處理,那么3個月的數據量就是9億,可以分1024張表,那么每張表的數據大概就在100萬左右。
比如用戶id為100,那我們都經過hash(100),然后對1024取模,就可以落到對應的表上了。
那分表后的ID怎么保證唯一性的呢?
因為我們主鍵默認都是自增的,那么分表之后的主鍵在不同表就肯定會有沖突了。有幾個辦法考慮:
設定步長,比如1-1024張表我們分別設定1-1024的基礎步長,這樣主鍵落到不同的表就不會沖突了。
分布式ID,自己實現一套分布式ID生成算法或者使用開源的比如雪花算法這種
分表后不使用主鍵作為查詢依據,而是每張表單獨新增一個字段作為唯一主鍵使用,比如訂單表訂單號是唯一的,不管最終落在哪張表都基于訂單號作為查詢依據,更新也一樣。

















 京公網安備 11010802030320號
京公網安備 11010802030320號