


在以前,商業分析對應的英文單詞是Business Analysis,大家用的分析工具是Excel,后來數據量大了,Excel應付不過來了(Excel最大支持行數為1048576行),人們開始轉向python和R這樣的分析工具了,這時候商業分析對應的單詞是Business Analytics。
其實python和Excel的使用準則一樣,都是[We don't repeat ourselves],都是盡可能用更方便的操作替代機械操作和純體力勞動。
用python做數據分析,離不開著名的pandas包,經過了很多版本的迭代優化,pandas現在的生態圈已經相當完整了,官網還給出了它和其他分析工具的對比:

本文用的主要也是pandas,繪圖用的庫是plotly,實現的Excel的常用功能有:
Python和Excel的交互
vlookup函數
數據透視表
繪圖
以后如果發掘了更多Excel的功能,會回來繼續更新和補充。開始之前,首先按照慣例加載pandas包:
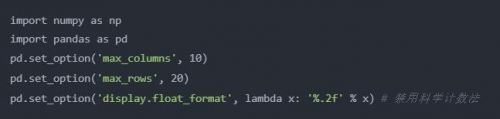
import numpy as npimport pandas as pdpd.set_option('max_columns', 10)pd.set_option('max_rows', 20)pd.set_option('display.float_format', lambda x: '%.2f' % x) # 禁用科學計數法
Python和Excel的交互
pandas里最常用的和Excel I/O有關的四個函數是read_csv/ read_excel/ to_csv/ to_excel,它們都有特定的參數設置,可以定制想要的讀取和導出效果。
比如說想要讀取這樣一張表的左上部分:
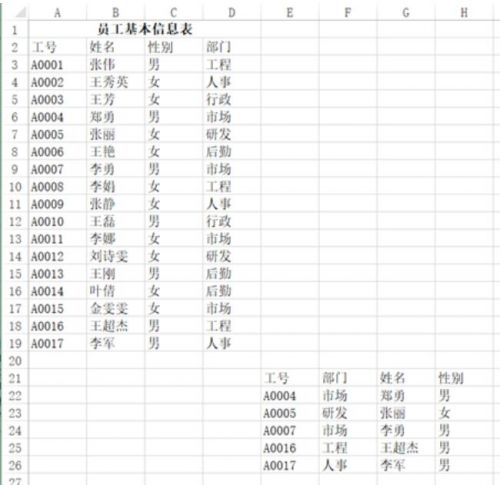
可以用pd.read_excel("test.xlsx", header=1, nrows=17, usecols=3),返回結果:
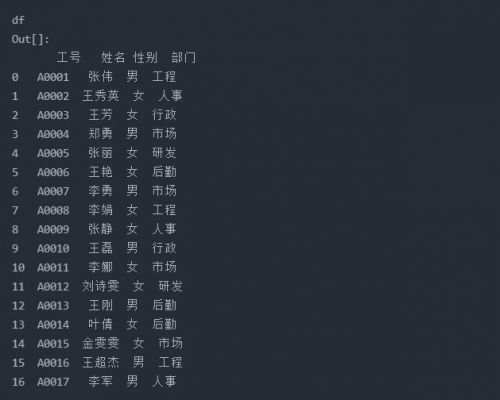
輸出函數也同理,使用多少列,要不要index,標題怎么放,都可以控制。
vlookup函數
vlookup號稱是Excel里的神器之一,用途很廣泛,下面的例子來自豆瓣,VLOOKUP函數最常用的10種用法,你會幾種?
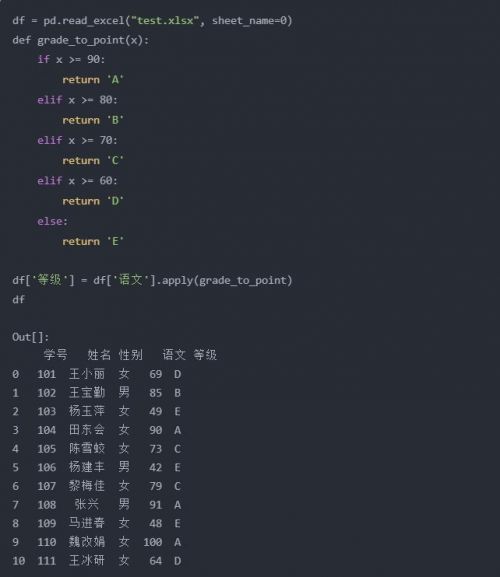
案例一
問題:A3:B7單元格區域為字母等級查詢表,表示60分以下為E級、60~69分為D級、70~79分為C級、80~89分為B級、90分以上為A級。D:G列為初二年級1班語文測驗成績表,如何根據語文成績返回其字母等級?
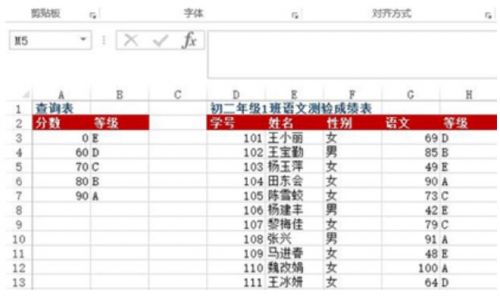
方法:在H3:H13單元格區域中輸入=VLOOKUP(G3, 3:7, 2)
python實現:
案例二
問題:在Sheet1里面如何查找折舊明細表中對應編號下的月折舊額?(跨表查詢)
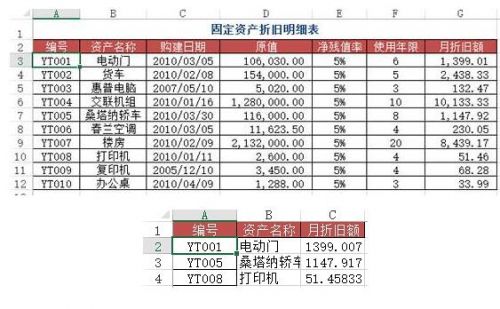
方法:在Sheet1里面的C2:C4單元格輸入 =VLOOKUP(A2, 折舊明細表!AG$12, 7, 0)
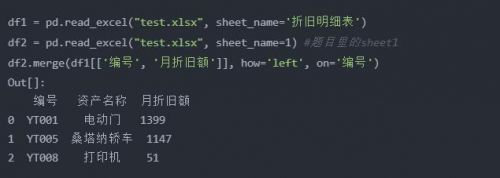
python實現:使用merge將兩個表按照編號連接起來就行
案例三
問題:類似于案例二,但此時需要使用近似查找
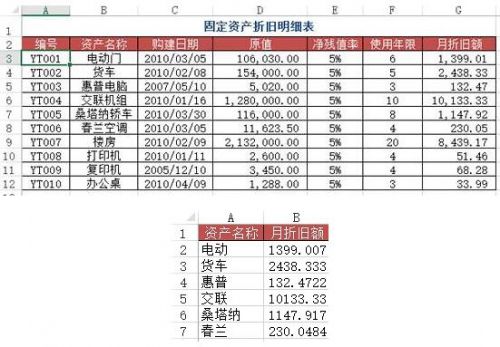
方法:在B2:B7區域中輸入公式=VLOOKUP(A2&"*", 折舊明細表!2:12, 6, 0)
python實現:這個比起上一個要麻煩一些,需要用到一些pandas的使用技巧
df1 = pd.read_excel("test.xlsx", sheet_name='折舊明細表')
df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有資產名稱簡寫的表
df3['月折舊額'] = 0
for i in range(len(df3['資產名稱'])):
df3['月折舊額'][i] = df1[df1['資產名稱'].map(lambda x:df3['資產名稱'][i] in x)]['月折舊額']
df3
Out[]:
資產名稱 月折舊額
0 電動 1399
1 貨車 2438
2 惠普 132
3 交聯 10133
4 桑塔納 1147
5 春蘭 230
案例四
問題:在Excel中錄入數據信息時,為了提高工作效率,用戶希望通過輸入數據的關鍵字后,自動顯示該記錄的其余信息,例如,輸入員工工號自動顯示該員工的信命,輸入物料號就能自動顯示該物料的品名、單價等。
如圖所示為某單位所有員工基本信息的數據源表,在“2010年3月員工請假統計表”工作表中,當在A列輸入員工工號時,如何實現對應員工的姓名、身份證號、部門、職務、入職日期等信息的自動錄入?
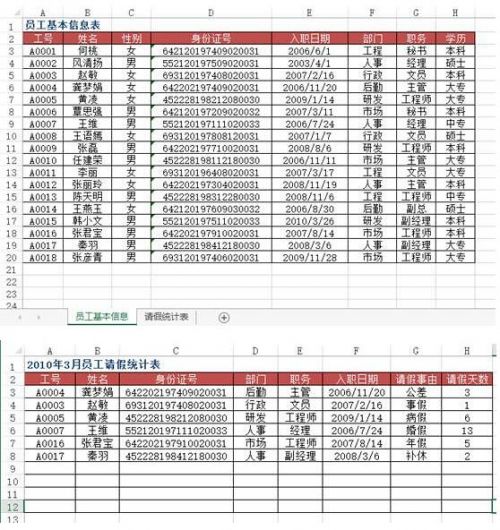
方法:使用VLOOKUP+MATCH函數,在“2010年3月員工請假統計表”工作表中選擇B3:F8單元格區域,輸入下列公式=IF(A3,員工基本信息!H,MATCH(B員工基本信息2:$2,0),0)),按下【Ctrl+Enter】組合鍵結束。
python實現:上面的Excel的方法用得很靈活,但是pandas的想法和操作更簡單方便些

案例五
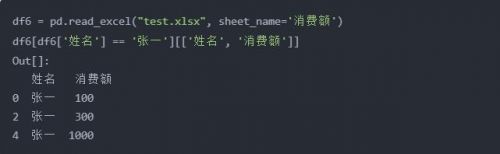
問題:用VLOOKUP函數實現批量查找,VLOOKUP函數一般情況下只能查找一個,那么多項應該怎么查找呢?如下圖,如何把張一的消費額全部列出?
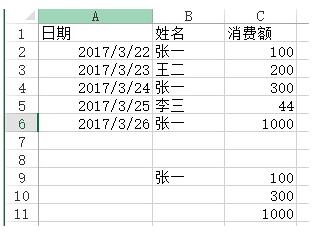
方法:在C9:C11單元格里面輸入公式=VLOOKUP(B$9&ROW(A1),IF({1,0},$B$2:$B$6&COUNTIF(INDIRECT("b2:b"&ROW($2:$6)),B$9),$C$2:$C$6),2,),按SHIFT+CTRL+ENTER鍵結束。
python實現:vlookup函數有兩個不足(或者算是特點吧),一個是被查找的值一定要在區域里的第一列,另一個是只能查找一個值,剩余的即便能匹配也不去查找了,這兩點都能通過靈活應用if和indirect函數來解決,不過pandas能做得更直白一些。
數據透視表
數據透視表是Excel的另一個神器,本質上是一系列的表格重組整合的過程。
問題:需要匯總各個區域,每個月的銷售額與成本總計,并同時算出利潤
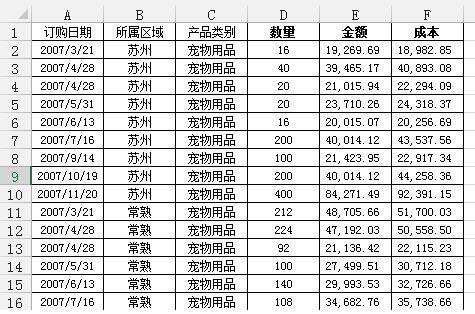
通過Excel的數據透視表的操作最終實現了下面這樣的效果:
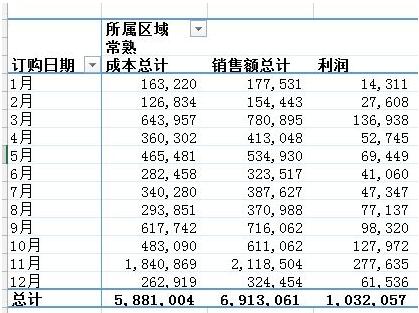
python實現:對于這樣的分組的任務,首先想到的就是pandas的groupby,代碼寫起來也簡單,思路就是把剛才Excel的點鼠標的操作反映到代碼命令上:

也可以使用pandas里的pivot_table函數來實現:
df3 = pd.pivot_table(df, values=['銷售額', '成本'], index=['訂購月份', '所屬區域'] , aggfunc='sum')
df3['利潤'] = df3['銷售額'] - df3['成本']
df3
Out[]:
成本 銷售額 利潤
訂購月份 所屬區域
1 南京 94967.84 134313.61 39345.77
常熟 163220.07 177531.47 14311.40
無錫 231822.28 316418.09 84595.81
昆山 145403.32 159183.35 13780.03
蘇州 238812.03 287253.99 48441.96
2 南京 138530.42 187129.13 48598.71
常熟 126834.37 154442.74 27608.37
無錫 376134.98 464012.20 87877.22
昆山 86244.52 102324.46 16079.94
蘇州 91419.54 105940.34 14520.80
... ... ...
11 南京 221687.11 286329.88 64642.77
常熟 1840868.53 2118503.54 277635.01
無錫 536866.77 633915.41 97048.64
昆山 342420.18 351023.24 8603.06
蘇州 1144809.83 1269351.39 124541.56
12 南京 808959.32 894522.06 85562.74
常熟 262918.81 324454.49 61535.68
無錫 856816.72 1040127.19 183310.48
昆山 951652.87 1096212.75 144559.87
蘇州 302154.25 347939.30 45785.05
[60 rows x 3 columns]
pandas的pivot_table的參數index/ columns/ values和Excel里的參數是對應上的(當然,我這話說了等于沒說,數據透視表里不就是行/列/值嗎還能有啥。)
但是我個人還是更喜歡用groupby,因為它運算速度非常快。我在打kaggle比賽的時候,有一張表是貸款人的行為信息,大概有2700萬行,用groupby算了幾個聚合函數,幾秒鐘就完成了。
groupby的功能很全面,內置了很多aggregate函數,能夠滿足大部分的基本需求,如果你需要一些其他的函數,可以搭配使用apply和lambda。
不過pandas的官方文檔說了,groupby之后用apply速度非常慢,aggregate內部做過優化,所以很快,apply是沒有優化的,所以建議有問題先想想別的方法,實在不行的時候再用apply。
我打比賽的時候,為了生成一個新變量,用了groupby的apply,寫了這么一句:ins['weight'] = ins[['SK_ID_PREV', 'DAYS_ENTRY_PAYMENT']].groupby('SK_ID_PREV').apply(lambda x: 1-abs(x)/x.sum().abs()).iloc[:,1],1000萬行的數據,足足算了十多分鐘,等得我心力交瘁。
繪圖
因為Excel畫出來的圖能夠交互,能夠在圖上進行一些簡單操作,所以這里用的python的可視化庫是plotly,案例就用我這個學期發展經濟學課上的作業吧,當時的圖都是用Excel畫的,現在用python再畫一遍。開始之前,首先加載plotly包。

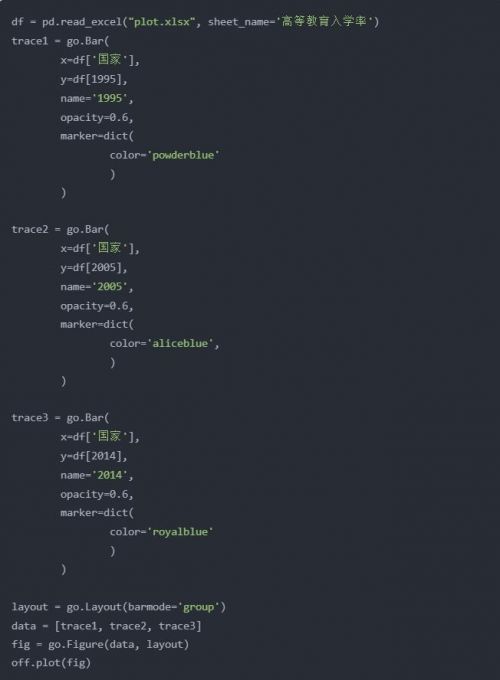
柱狀圖
當時用Excel畫了很多的柱狀圖,其中的一幅圖是
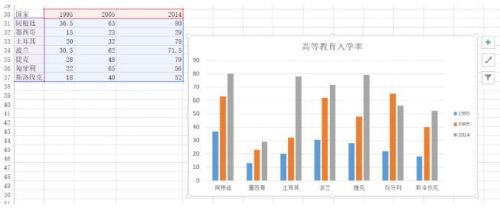
下面用plotly來畫一下
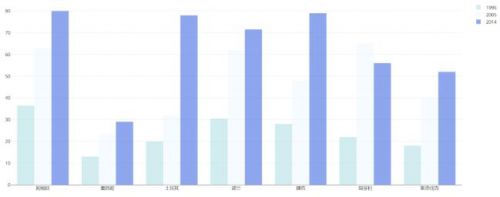
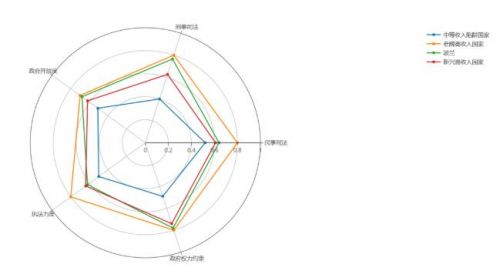
雷達圖
用Excel畫的:

用python畫的:
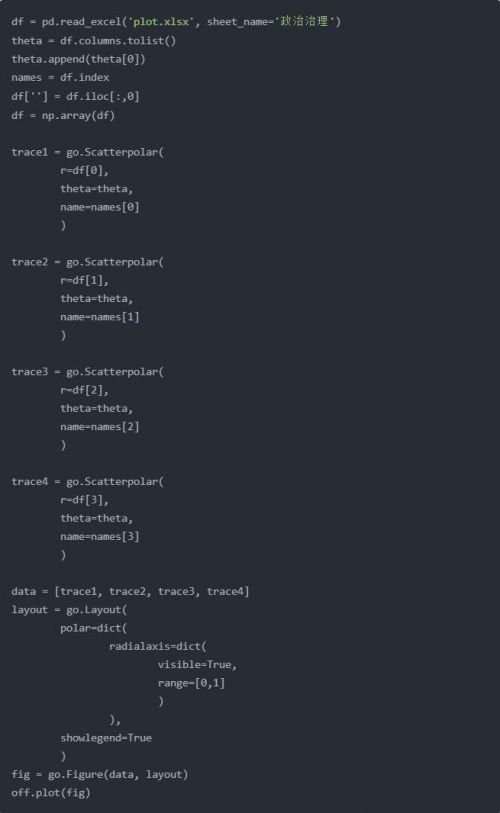
畫起來比Excel要麻煩得多。
總體而言,如果畫簡單基本的圖形,用Excel是最方便的,如果要畫高級一些的或者是需要更多定制化的圖形,使用python更合適。














 京公網安備 11010802030320號
京公網安備 11010802030320號