


要想做反爬蟲,我們首先需要知道如何寫個簡單的爬蟲。
通常編寫爬蟲需要經過這么幾個過程:
• 分析頁面請求格式
• 創建合適的http請求
• 批量發送http請求,獲取數據
舉個例子,直接查看攜程生產url。在詳情頁點擊“確定”按鈕,會加載價格。假設價格是你想要的,那么抓出網絡請求之后,哪個請求才是你想要的結果呢? 你只需要用根據網絡傳輸數據量進行倒序排列即可。因為其他的迷惑性的url再多再復雜,開發人員也不會舍得加數據量給他。

代碼:
import requests
def download_page(url):
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url,headers=headers)
return data
if __name__ == '__main__':
url = 'https://m.ctrip.com/restapi/soa2/21881/json/HotelSearch?testab=5b9a651b08c1069815c5af78f8b2bf6df9dd42a6129be5784bb096315494619a'
download_page(url)
高級爬蟲
那么爬蟲進階應該如何做呢?通常所謂的進階有以下幾種:
分布式爬蟲
Python默認情況下,我們使用scrapy框架進行爬蟲時使用的是單機爬蟲,就是說它只能在一臺電腦上運行,因為爬蟲調度器當中的隊列queue去重和set集合都只能在本機上創建的,其他電腦無法訪問另外一臺電腦上的內存和內容。
分布式爬蟲實現了多臺電腦使用一個共同的爬蟲程序,它可以同時將爬蟲任務部署到多臺電腦上運行,這樣可以提高爬蟲速度,實現分布式爬蟲。
首先就需要配置安裝redis和scrapy-redis,而scrapy-redis是一個基于redis數據庫的scrapy組件,它提供了四種組件,通過它,可以快速實現簡單分布式爬蟲程序。
四種scrapy-redis組件:
Scheduler(調度):Scrapy改造了python本來的collection.deque(雙向隊列)形成了自己Scrapy queue,而scrapy-redis 的解決是把這個Scrapy queue換成redis數據庫,從同一個redis-server存放要爬取的request,便能讓多個spider去同一個數據庫里讀取。Scheduler負責對新的request進行入列操作(加入Scrapy queue),取出下一個要爬取的request(從Scrapy queue中取出)等操作。
Duplication Filter(去重):Scrapy中用集合實現這個request去重功能,Scrapy中把已經發送的request指紋放入到一個集合中,把下一個request的指紋拿到集合中比對,如果該指紋存在于集合中,說明這個request發送過了,如果沒有則繼續操作。
Item Pipline(管道):引擎將(Spider返回的)爬取到的Item給Item Pipeline,scrapy-redis 的Item Pipeline將爬取到的 Item 存?redis的 items queue
Base Spider(爬蟲):不再使用scrapy原有的Spider類,重寫的RedisSpider繼承了Spider和RedisMixin這兩個類,RedisMixin是用來從redis讀取url的類。
工作原理:
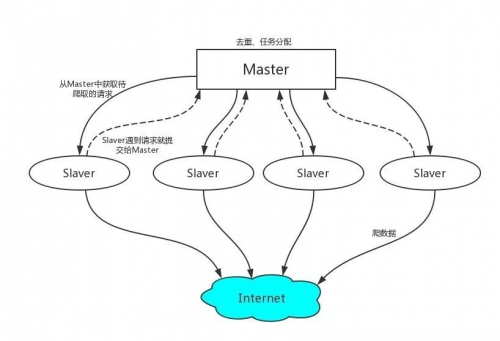
1、首先Slaver端從Master端拿任務(Request、url)進行數據抓取,Slaver抓取數據的同時,產生新任務的Request便提交給 Master 處理;
2、Master端只有一個Redis數據庫,負責將未處理的Request去重和任務分配,將處理后的Request加入待爬隊列,并且存儲爬取的數據。
模擬JavaScript
模擬javascript,抓取動態網頁,是進階技巧。但是其實這只是個很簡單的功能。因為,如果對方沒有反爬蟲,你完全可以直接抓ajax本身,而無需關心js怎么處理的。如果對方有反爬蟲,那么javascript必然十分復雜,重點在于分析,而不僅僅是簡單的模擬。
PhantomJs或者selenium
以上的用來做自動測試的,結果因為效果很好,很多人拿來做爬蟲。但是這個東西有個硬傷,就是:效率。占用資源比較多,但是爬取效果很好。
總結:越是低級的爬蟲,越容易被封鎖,但是性能好,成本低。越是高級的爬蟲,越難被封鎖,但是性能低,成本也越高。
當成本高到一定程度,我們就可以無需再對爬蟲進行封鎖。經濟學上有個詞叫邊際效應。付出成本高到一定程度,收益就不是很多了。














 京公網安備 11010802030320號
京公網安備 11010802030320號