


本文將引入一個思路:“在 Kubernetes 集群發生網絡異常時如何排查”。文章將引入 Kubernetes 集群中網絡排查的思路,包含網絡異常模型,常用工具,并且提出一些案例以供學習。
Pod 常見網絡異常分類
網絡排查工具
Pod 網絡異常排查思路及流程模型
CNI 網絡異常排查步驟
案例學習
Pod 網絡異常
網絡異常大概分為如下幾類:
網絡不可達:主要現象為 ping 不通,其可能原因為:
源端和目的端防火墻(iptables, selinux)限制
網絡路由配置不正確
源端和目的端的系統負載過高,網絡連接數滿,網卡隊列滿
網絡鏈路故障
端口不可達:主要現象為可以 ping 通,但 telnet 端口不通,其可能原因為:
源端和目的端防火墻限制
源端和目的端的系統負載過高,網絡連接數滿,網卡隊列滿,端口耗盡
目的端應用未正常監聽導致(應用未啟動,或監聽為 127.0.0.1 等)
DNS 解析異常:主要現象為基礎網絡可以連通,訪問域名報錯無法解析,訪問 IP 可以正常連通。其可能原因為
Pod 的 DNS 配置不正確
DNS 服務異常
pod 與 DNS 服務通訊異常
大數據包丟包:主要現象為基礎網絡和端口均可以連通,小數據包收發無異常,大數據包丟包。可能原因為:
可使用 ping -s 指定數據包大小進行測試
數據包的大小超過了 docker、CNI 插件、或者宿主機網卡的 MTU 值。
CNI 異常:主要現象為 Node 可以通,但 Pod 無法訪問集群地址,可能原因有:
kube-proxy 服務異常,沒有生成 iptables 策略或者 ipvs 規則導致無法訪問
CIDR 耗盡,無法為 Node 注入 PodCIDR 導致 CNI 插件異常
其他 CNI 插件問題
那么整個 Pod 網絡異常分類可以如下圖所示:
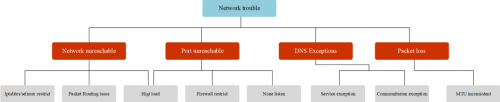
總結一下,Pod 最常見的網絡故障有,網絡不可達(ping 不通);端口不可達(telnet 不通);DNS 解析異常(域名不通)與大數據包丟失(大包不通)。
常用網絡排查工具
在了解到常見的網絡異常后,在排查時就需要使用到一些網絡工具才可以很有效的定位到網絡故障原因,下面會介紹一些網絡排查工具。
tcpdump
tcpdump 網絡嗅探器,將強大和簡單結合到一個單一的命令行界面中,能夠將網絡中的報文抓取,輸出到屏幕或者記錄到文件中。
各系統下的安裝
Ubuntu/Debian: tcpdump ;apt-get install -y tcpdump
Centos/Fedora: tcpdump ;yum install -y tcpdump
Apline:tcpdump ;apk add tcpdump --no-cache
查看指定接口上的所有通訊
語法
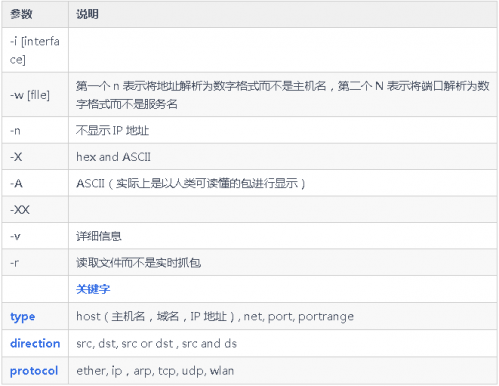
捕獲所有網絡接口
tcpdump -D
按 IP 查找流量
最常見的查詢之一 host,可以看到來往于 1.1.1.1 的流量。
tcpdump host 1.1.1.1
按源 / 目的 地址過濾
如果只想查看來自 / 向某方向流量,可以使用 src 和 dst。
tcpdump src|dst 1.1.1.1
通過網絡查找數據包
使用 net 選項,來要查找出 / 入某個網絡或子網的數據包。
tcpdump net 1.2.3.0/24
使用十六進制輸出數據包內容
hex 可以以 16 進制輸出包的內容
tcpdump -c 1 -X icmp
查看特定端口的流量
使用 port 選項來查找特定的端口流量。
tcpdump port 3389tcpdump src port 1025
查找端口范圍的流量
tcpdump portrange 21-23
過濾包的大小
如果需要查找特定大小的數據包,可以使用以下選項。你可以使用 less,greater。
tcpdump less 32tcpdump greater 64tcpdump <= 128
捕獲流量輸出為文件
-w 可以將數據包捕獲保存到一個文件中以便將來進行分析。這些文件稱為 PCAP(PEE-cap)文件,它們可以由不同的工具處理,包括 Wireshark 。
tcpdump port 80 -w capture_file
組合條件
tcpdump 也可以結合邏輯運算符進行組合條件查詢
ANDand or &&
ORor or ||
EXCEPTnot or !
tcpdump -i eth0 -nn host 220.181.57.216 and 10.0.0.1 # 主機之間的通訊tcpdump -i eth0 -nn host 220.181.57.216 or 10.0.0.1# 獲取10.0.0.1與 10.0.0.9或 10.0.0.1 與10.0.0.3之間的通訊tcpdump -i eth0 -nn host 10.0.0.1 and \(10.0.0.9 or 10.0.0.3\)
原始輸出
并顯示人類可讀的內容進行輸出包(不包含內容)。
tcpdump -ttnnvvS -i eth0tcpdump -ttnnvvS -i eth0
IP 到端口
讓我們查找從某個 IP 到端口任何主機的某個端口所有流量。
tcpdump -nnvvS src 10.5.2.3 and dst port 3389
去除特定流量
可以將指定的流量排除,如這顯示所有到 192.168.0.2 的 非 ICMP 的流量。
tcpdump dst 192.168.0.2 and src net and not icmp
來自非指定端口的流量,如,顯示來自不是 SSH 流量的主機的所有流量。
tcpdump -vv src mars and not dst port 22
選項分組
在構建復雜查詢時,必須使用單引號 '。單引號用于忽略特殊符號 () ,以便于使用其他表達式(如 host, port, net 等)進行分組。
tcpdump 'src 10.0.2.4 and (dst port 3389 or 22)'
過濾 TCP 標記位
tcpdump 'tcp[13] & 4!=0'tcpdump 'tcp[tcpflags] == tcp-rst'
TCP SYN
tcpdump 'tcp[13] & 2!=0'tcpdump 'tcp[tcpflags] == tcp-syn'
同時忽略 SYN 和 ACK 標志的數據包
tcpdump 'tcp[13]=18'
TCP URG
tcpdump 'tcp[13] & 32!=0'tcpdump 'tcp[tcpflags] == tcp-urg'
TCP ACK
tcpdump 'tcp[13] & 16!=0'tcpdump 'tcp[tcpflags] == tcp-ack'
TCP PSH
tcpdump 'tcp[13] & 8!=0'tcpdump 'tcp[tcpflags] == tcp-push'
TCP FIN
tcpdump 'tcp[13] & 1!=0'tcpdump 'tcp[tcpflags] == tcp-fin'
查找 http 包
查找 user-agent 信息
tcpdump -vvAls0 | grep 'User-Agent:'
查找只是 GET 請求的流量
tcpdump -vvAls0 | grep 'GET'
查找 http 客戶端 IP
tcpdump -vvAls0 | grep 'Host:'
查詢客戶端 cookie
tcpdump -vvAls0 | grep 'Set-Cookie|Host:|Cookie:'
查找 DNS 流量
tcpdump -vvAs0 port 53
查找對應流量的明文密碼
tcpdump port http or port ftp or port smtp or port imap or port pop3 or port telnet -lA | egrep -i -B5 'pass=|pwd=|log=|login=|user=|username=|pw=|passw=|passwd= |password=|pass:|user:|username:|password:|login:|pass |user '
wireshark 追蹤流
wireshare 追蹤流可以很好的了解出在一次交互過程中都發生了那些問題。
wireshare 選中包,右鍵選擇 “追蹤流“ 如果該包是允許的協議是可以打開該選項的
關于抓包節點和抓包設備
如何抓取有用的包,以及如何找到對應的接口,有以下建議
抓包節點:
通常情況下會在源端和目的端兩端同時抓包,觀察數據包是否從源端正常發出,目的端是否接收到數據包并給源端回包,以及源端是否正常接收到回包。如果有丟包現象,則沿網絡鏈路上各節點抓包排查。例如,A 節點經過 c 節點到 B 節點,先在 AB 兩端同時抓包,如果 B 節點未收到 A 節點的包,則在 c 節點同時抓包。
抓包設備:
對于 Kubernetes 集群中的 Pod,由于容器內不便于抓包,通常視情況在 Pod 數據包經過的 veth 設備,docker0 網橋,CNI 插件設備(如 cni0,flannel.1 etc..)及 Pod 所在節點的網卡設備上指定 Pod IP 進行抓包。選取的設備根據懷疑導致網絡問題的原因而定,比如范圍由大縮小,從源端逐漸靠近目的端,比如懷疑是 CNI 插件導致,則在 CNI 插件設備上抓包。從 pod 發出的包逐一經過 veth 設備,cni0 設備,flannel0,宿主機網卡,到達對端,抓包時可按順序逐一抓包,定位問題節點。
需要注意在不同設備上抓包時指定的源目 IP 地址需要轉換,如抓取某 Pod 時,ping {host} 的包,在 veth 和 cni0 上可以指定 Pod IP 抓包,而在宿主機網卡上如果仍然指定 Pod IP 會發現抓不到包,因為此時 Pod IP 已被轉換為宿主機網卡 IP。
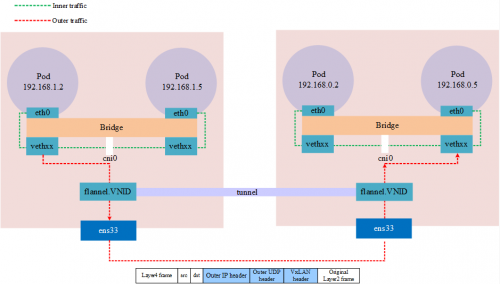
下圖是一個使用 VxLAN 模式的 flannel 的跨界點通訊的網絡模型,在抓包時需要注意對應的網絡接口
nsenter
nsenter 是一款可以進入進程的名稱空間中。例如,如果一個容器以非 root 用戶身份運行,而使用 docker exec 進入其中后,但該容器沒有安裝 sudo 或未 netstat ,并且您想查看其當前的網絡屬性,如開放端口,這種場景下將如何做到這一點?nsenter 就是用來解決這個問題的。
nsenter (namespace enter) 可以在容器的宿主機上使用 nsenter 命令進入容器的命名空間,以容器視角使用宿主機上的相應網絡命令進行操作。當然需要擁有 root 權限
各系統下的安裝
Ubuntu/Debian: util-linux ;apt-get install -y util-linux
Centos/Fedora: util-linux ;yum install -y util-linux
Apline:util-linux ;apk add util-linux --no-cache
nsenter 的 c 使用語法為,nsenter -t pid -n,-t 接 進程 ID 號,-n 表示進入名稱空間內,為執行的命令。
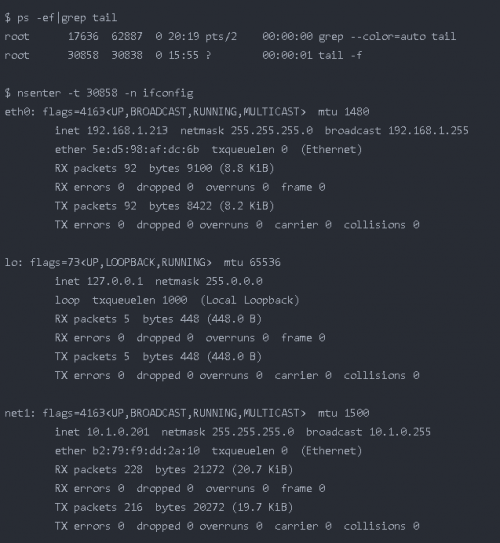
實例:如我們有一個 Pod 進程 ID 為 30858,進入該 Pod 名稱空間內執行 ifconfig ,如下列所示
如何定位 Pod 名稱空間
首先需要確定 Pod 所在的節點名稱
$ kubectl get pods -owide |awk '{print $1,$7}'NAME NODEnetbox-85865d5556-hfg6v master-machinenetbox-85865d5556-vlgr4 node01
如果 Pod 不在當前節點還需要用 IP 登錄則還需要查看 IP(可選)
$ kubectl get pods -owide |awk '{print $1,$6,$7}'NAME IP NODEnetbox-85865d5556-hfg6v 192.168.1.213 master-machinenetbox-85865d5556-vlgr4 192.168.0.4 node01
接下來,登錄節點,獲取容器 lD,如下列所示,每個 pod 默認有一個 pause 容器,其他為用戶 yaml 文件中定義的容器,理論上所有容器共享相同的網絡命名空間,排查時可任選一個容器。
$ docker ps |grep netbox-85865d5556-hfg6v6f8c58377aae f78dd05f11ff "tail -f" 45 hours ago Up 45 hours k8s_netbox_netbox-85865d5556-hfg6v_default_4a8e2da8-05d1-4c81-97a7-3d76343a323a_0b9c732ee457e registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 "/pause" 45 hours ago Up 45 hours k8s_POD_netbox-85865d5556-hfg6v_default_4a8e2da8-05d1-4c81-97a7-3d76343a323a_0
接下來獲得獲取容器在節點系統中對應的進程號,如下所示
$ docker inspect --format "{{ .State.Pid }}" 6f8c58377aae30858
最后就可以通過 nsenter 進入容器網絡空間執行命令了
paping
paping 命令可對目標地址指定端口以 TCP 協議進行連續 ping,通過這種特性可以彌補 ping ICMP 協議,以及 nmap , telnet 只能進行一次操作的的不足;通常情況下會用于測試端口連通性和丟包率
paping download:paping
paping 還需要安裝以下依賴,這取決于你安裝的 paping 版本
RedHat/CentOS:yum install -y libstdc++.i686 glibc.i686
Ubuntu/Debian:最小化安裝無需依賴
mtr
mtr 是一個跨平臺的網絡診斷工具,將 traceroute 和 ping 的功能結合到一個工具。與 traceroute 不同的是 mtr 顯示的信息比起 traceroute 更加豐富:通過 mtr 可以確定網絡的條數,并且可以同時打印響應百分比以及網絡中各跳躍點的響應時間。
各系統下的安裝
Ubuntu/Debian: mtr ;apt-get install -y mtr
Centos/Fedora: mtr ;yum install -y mtr
Apline:mtr ;apk add mtr --no-cache
簡單的使用示例
最簡單的示例,就是后接域名或 IP,這將跟蹤整個路由
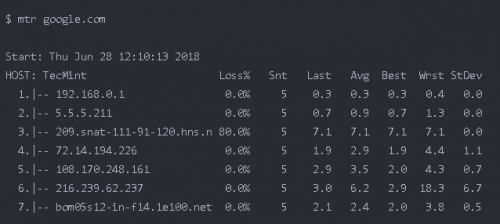
-n 強制 mtr 打印 IP 地址而不是主機名
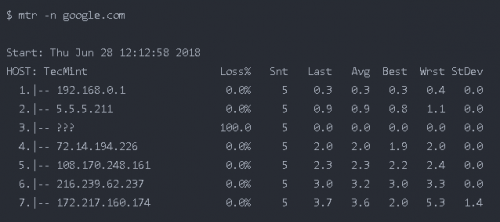
-b 同時顯示 IP 地址與主機名
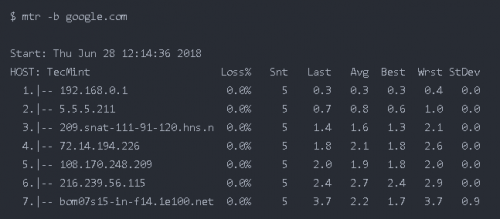
-c 跟一個具體的值,這將限制 mtr ping 的次數,到達次數后會退出
$ mtr -c5 google.com
如果需要指定次數,并且在退出后保存這些數據,使用 -r flag
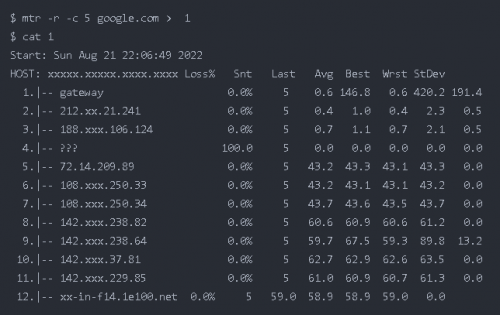
默認使用的是 ICMP 協議 -i ,可以指定 -u, -t 使用其他協議
mtr --tcp google.com
-m 指定最大的跳數
mtr -m 35 216.58.223.78
-s 指定包的大小
mtr 輸出的數據
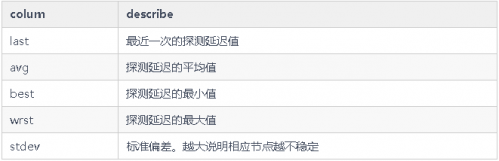
丟包判斷
任一節點的 Loss%(丟包率)如果不為零,則說明這一跳網絡可能存在問題。導致相應節點丟包的原因通常有兩種。
運營商基于安全或性能需求,人為限制了節點的 ICMP 發送速率,導致丟包。
節點確實存在異常,導致丟包。可以結合異常節點及其后續節點的丟包情況,來判定丟包原因。
Notes:
如果隨后節點均沒有丟包,則通常說明異常節點丟包是由于運營商策略限制所致。可以忽略相關丟包。
如果隨后節點也出現丟包,則通常說明節點確實存在網絡異常,導致丟包。對于這種情況,如果異常節點及其后續節點連續出現丟包,而且各節點的丟包率不同,則通常以最后幾跳的丟包率為準。如鏈路測試在第 5、6、7 跳均出現了丟包。最終丟包情況以第 7 跳作為參考。
延遲判斷
由于鏈路抖動或其它因素的影響,節點的 Best 和 Worst 值可能相差很大。而 Avg(平均值)統計了自鏈路測試以來所有探測的平均值,所以能更好的反應出相應節點的網絡質量。而 StDev(標準偏差值)越高,則說明數據包在相應節點的延時值越不相同(越離散)。所以標準偏差值可用于協助判斷 Avg 是否真實反應了相應節點的網絡質量。例如,如果標準偏差很大,說明數據包的延遲是不確定的。可能某些數據包延遲很小(例如:25ms),而另一些延遲卻很大(例如:350ms),但最終得到的平均延遲反而可能是正常的。所以此時 Avg 并不能很好的反應出實際的網絡質量情況。
這就需要結合如下情況進行判斷:
如果 StDev 很高,則同步觀察相應節點的 Best 和 wrst,來判斷相應節點是否存在異常。
如果 StDev 不高,則通過 Avg 來判斷相應節點是否存在異常。
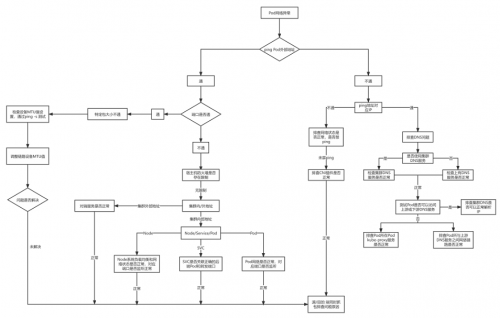
Pod 網絡排查流程
Pod 網絡異常時排查思路,可以按照下圖所示
案例學習
擴容節點訪問 service 地址不通
測試環境 k8s 節點擴容后無法訪問集群 clusterlP 類型的 registry 服務
環境信息:
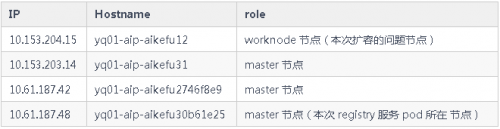
cni 插件:flannel vxlan
kube-proxy 工作模式為 iptables
registry 服務
單實例部署在 10.61.187.48:5000
Pod IP:10.233.65.46,
Cluster IP:10.233.0.100 現象:
所有節點之間的 pod 通信正常
任意節點和 Pod curl registry 的 Pod 的 IP:5000 均可以連通
新擴容節點 10.153.204.15 curl registry 服務的 Cluster lP 10.233.0.100:5000 不通,其他節點 curl 均可以連通
分析思路:
根據現象 1 可以初步判斷 CNI 插件無異常
根據現象 2 可以判斷 registry 的 Pod 無異常
根據現象 3 可以判斷 registry 的 service 異常的可能性不大,可能是新擴容節點訪問 registry 的 service 存在異常
懷疑方向:
問題節點的 kube-proxy 存在異常
問題節點的 iptables 規則存在異常
問題節點到 service 的網絡層面存在異常
排查過程:
排查問題節點的 kube-proxy
執行 kubectl get pod -owide -nkube-system l grep kube-proxy 查看 kube-proxy Pod 的狀態,問題節點上的 kube-proxy Pod 為 running 狀態
執行 kubecti logs-nkube-system 查看問題節點 kube-proxy 的 Pod 日志,沒有異常報錯
在問題節點操作系統上執行 iptables -S -t nat 查看 iptables 規則
排查過程:
確認存在到 registry 服務的 Cluster lP 10.233.0.100 的 KUBE-SERVICES 鏈,跳轉至 KUBE-SVC-* 鏈做負載均衡,再跳轉至 KUBE-SEP-* 鏈通過 DNAT 替換為服務后端 Pod 的 IP 10.233.65.46。因此判斷 iptables 規則無異常執行 route-n 查看問題節點存在訪問 10.233.65.46 所在網段的路由,如圖所示
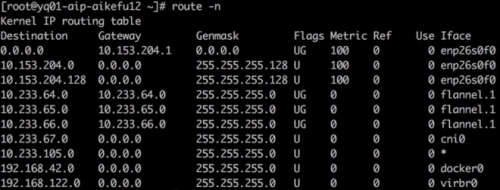
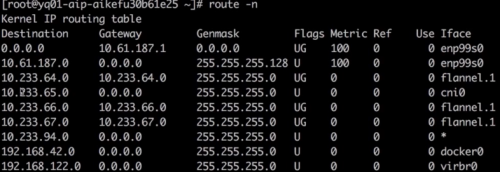
查看對端的回程路由
以上排查證明問題原因不是 cni 插件或者 kube-proxy 異常導致,因此需要在訪問鏈路上抓包,判斷問題原因、問題節點執行 curl 10.233.0.100:5000,在問題節點和后端 pod 所在節點的 flannel.1 上同時抓包發包節點一直在重傳,Cluster lP 已 DNAT 轉換為后端 Pod IP,如圖所示

后端 Pod( registry 服務)所在節點的 flannel.1 上未抓到任何數據包,如圖所示

請求 service 的 ClusterlP 時,在兩端物理機網卡抓包,發包端如圖所示,封裝的源端節點 IP 是 10.153.204.15,但一直在重傳

收包端收到了包,但未回包,如圖所示

由此可以知道,NAT 的動作已經完成,而只是后端 Pod( registry 服務)沒有回包,接下來在問題節點執行 curl10.233.65.46:5000,在問題節點和后端( registry 服務)Pod 所在節點的 flannel.1 上同時抓包,兩節點收發正常,發包如圖所示


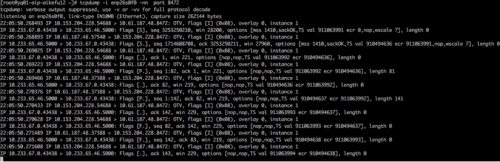
接下來在兩端物理機網卡接口抓包,因為數據包通過物理機網卡會進行 vxlan 封裝,需要抓 vxlan 設備的 8472 端口,發包端如圖所示
發現網絡鏈路連通,但封裝的 IP 不對,封裝的源端節點 IP 是 10.153.204.228,但是存在問題節點的 IP 是 10.153.204.15
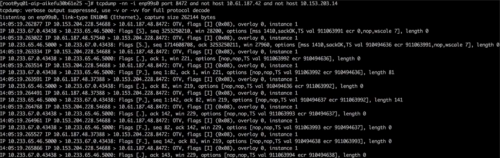
后端 Pod 所在節點的物理網卡上抓包,注意需要過濾其他正常節點的請求包,如圖所示;發現收到的數據包,源地址是 10.153.204.228,但是問題節點的 IP 是 10.153.204.15。
此時問題以及清楚了,是一個 Pod 存在兩個 IP,導致發包和回包時無法通過隧道設備找到對端的接口,所以發可以收到,但不能回。
問題節點執行 ip addr,發現網卡 enp26s0f0 上配置了兩個 IP,如圖所示
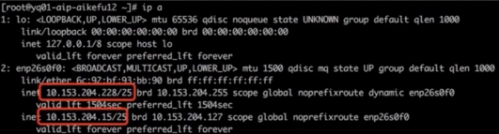
進一步查看網卡配置文件,發現網卡既配置了靜態 IP,又配置了 dhcp 動態獲取 IP。如圖所示
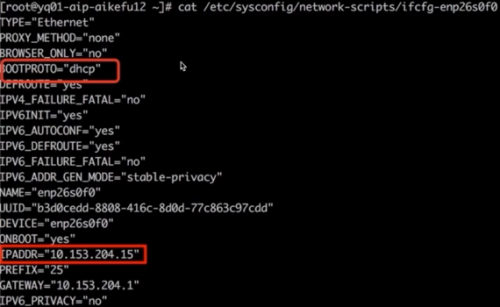
最終定位原因為問題節點既配置了 dhcp 獲取 IP,又配置了靜態 IP,導致 IP 沖突,引發網絡異常
解決方法:修改網卡配置文件 /etc/sysconfig/network-scripts/ifcfg-enp26s0f0 里 BOOTPROTO="dhcp"為 BOOTPROTO="none";重啟 docker 和 kubelet 問題解決。
集群外云主機調用集群內應用超時
問題現象:Kubernetes 集群外云主機以 http post 方式訪問 Kubernetes 集群應用接口超時
環境信息:Kubernetes 集群:calicoIP-IP 模式,應用接口以 nodeport 方式對外提供服務
客戶端:Kubernetes 集群之外的云主機
排查過程:
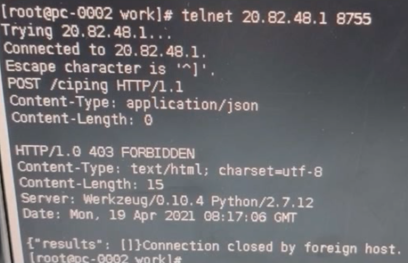
在云主機 telnet 應用接口地址和端口,可以連通,證明網絡連通正常,如圖所示
云主機上調用接口不通,在云主機和 Pod 所在 Kubernetes 節點同時抓包,使用 wireshark 分析數據包
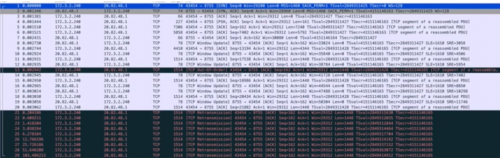
通過抓包結果分析結果為 TCP 鏈接建立沒有問題,但是在傳輸大數據的時候會一直重傳 1514 大小的第一個數據包直至超時。懷疑是鏈路兩端 MTU 大小不一致導致(現象:某一個固定大小的包一直超時的情況)。如圖所示,1514 大小的包一直在重傳。
報文 1-3 TCP 三次握手正常
報文 1 info 中 MSS 字段可以看到 MSS 協商為 1460,MTU=1460+20bytes(IP 包頭)+20bytes(TCP 包頭)=1500
報文 7 k8s 主機確認了包 4 的數據包,但是后續再沒有對數據的 ACK
報文 21-29 可以看到云主機一直在發送后面的數據,但是沒有收到 k8s 節點的 ACK,結合 pod 未收到任何報文,表明是 k8s 節點和 POD 通信出現了問題。
在云主機上使用 ping -s 指定數據包大小,發現超過 1400 大小的數據包無法正常發送。結合以上情況,定位是云主機網卡配置的 MTU 是 1500,tunl0 配置的 MTU 是 1440,導致大數據包無法發送至 tunl0 ,因此 Pod 沒有收到報文,接口調用失敗。
解決方法:修改云主機網卡 MTU 值為 1440,或者修改 calico 的 MTU 值為 1500,保持鏈路兩端 MTU 值一致。
集群 pod 訪問對象存儲超時
環境信息:公有云環境,Kubernetes 集群節點和對象存儲在同一私有網絡下,網絡鏈路無防火墻限制 k8s 集群開啟了節點自動彈縮(CA)和 Pod 自動彈縮(HPA),通過域名訪問對象存儲,Pod 使用集群 DNS 服務,集群 DNS 服務配置了用戶自建上游 DNS 服務器
排查過程:
使用 nsenter 工具進入 pod 容器網絡命名空間測試,ping 對象存儲域名不通,報錯 unknown server name,ping 對象存儲 lP 可以連通。
telnet 對象存儲 80/443 端口可以連通。
paping 對象存儲 80/443 端口無丟包。
為了驗證 Pod 創建好以后的初始階段網絡連通性,將以上測試動作寫入 dockerfile,重新生成容器鏡像并創 pod,測試結果一致。
通過上述步驟,判斷 Pod 網絡連通性無異常,超時原因為域名解析失敗,懷疑問題如下:
集群 DNS 服務存在異常
上游 DNS 服務存在異常
集群 DNS 服務與上游 DNS 通訊異常
pod 訪問集群 DNS 服務異常
根據上述方向排查,集群 DNS 服務狀態正常,無報錯。測試 Pod 分別使用集群 DNS 服務和上游 DNS 服務解析域名,前者解析失敗,后者解析成功。至此,證明上游 DNS 服務正常,并且集群 DNS 服務日志中沒有與上游 DNS 通訊超時的報錯。定位到的問題:Pod 訪問集群 DNS 服務超時
此時發現,出現問題的 Pod 集中在新彈出的 Kubernetes 節點上。這些節點的 kube-proxy Pod 狀態全部為 pending,沒有正常調度到節點上。因此導致該節點上其他 Pod 無法訪問包括 dns 在內的所有 Kubernetes service。
再進一步排查發現 kube-proxy Pod 沒有配置 priorityclass 為最高優先級,導致節點資源緊張時為了將高優先級的應用 Pod 調度到該節點,將原本已運行在該節點的 kube-proxy 驅逐。
解決方法:將 kube-proxy 設置 priorityclass 值為 system-node-critical 最高優先級,同時建議應用 Pod 配置就緒探針,測試可以正常連通對象存儲域名后再分配任務。

















 京公網安備 11010802030320號
京公網安備 11010802030320號