


了解常見驗證碼
在日常生活與工作中,在進行各類設計個人賬戶安全的操作時,往往需要填寫各種驗證碼來進行驗證,短信、語音、文字、問答、圖片、拖拽、旋轉騰挪、拼圖接圖.......千奇百怪,各種各樣,種類繁多,花樣迭起!就拿奇葩驗證碼鼻祖的12306來說,如今我們在12306中可以碰到各種有趣,各種類型的驗證碼的原因,要歸功于為搶票事業做出巨大貢獻的——黃牛們,它的“進化史”就是一部不斷與黃牛和搶票軟件“斗智斗勇”的歷史。
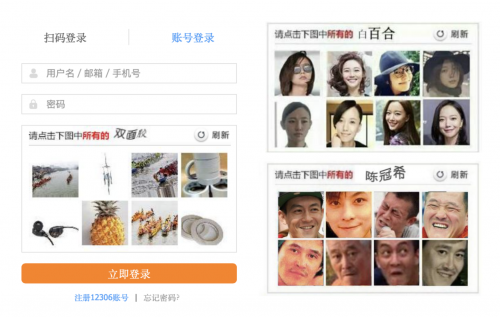
目前我們常見的驗證碼,無非就是文本、圖像以及音頻這三大類。
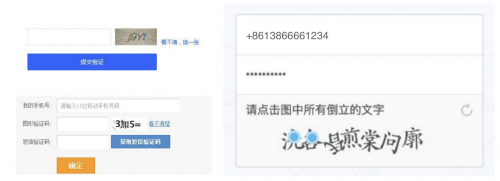
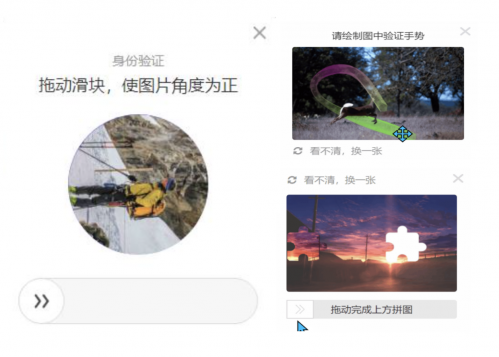
而當文本驗證碼仍容易被機器“擊破”時,圖像驗證碼就應運而生了。通常是會提供一些物體、動物、植物、人、風景之類的圖像,讓我們選擇正確的圖像進行標記。這就是以12306為首的圖像驗證碼了,但是這個還不算后來圖像驗證碼又增加了新的玩法,比如旋轉圖片,比如拼圖以及宮格,目的還是為了對抗爬蟲這些機器。
接下來是音頻驗證碼,這種相比前兩種數量相對要小一些,主要是會給我們一段錄音,里面有隨機的單詞或數字,有的會加一些噪音,我們基于錄音輸入其中聽到的單詞或數字,或者把它讀出來。從安全性上來說,聲音驗證碼比文本和圖像等級要提升一個層級,因為機器想要聽錄音并分辨,這個難度會非常大。
驗證碼的處理方案
• 手動輸入(input) 這種方法僅限于登錄一次就可持續使用的情況
• 圖像識別引擎解析 使用光學識別引擎處理圖片中的數據,目前常用于圖片數據提取,較少用于驗證碼處理
• 打碼平臺 爬蟲常用的驗證碼解決方案
圖像識別引擎
OCR,即Optical Character Recognition,光學字符識別,是指通過掃描字符,然后通過其形狀將其翻譯成電子文本的過程,對應圖形驗證碼來說,它們都是一些不規則的字符,這些字符是由字符稍加扭曲變換得到的內容,我們可以使用OCR技術來講其轉化為電子文本,然后將結果提取交給服務器,便可以達到自動識別驗證碼的過程
tesserocr與pytesseract是Python的一個OCR識別庫,但其實是對tesseract做的一層Python API封裝,pytesseract是Google的Tesseract-OCR引擎包裝器;所以它們的核心是tesseract,因此在安裝tesserocr之前,我們需要先安裝tesseract。
圖片識別引擎環境的安裝
1 引擎的安裝
• mac環境下直接執行命令
brew install --with-training-tools tesseract
• windows環境下的安裝 可以通過exe安裝包安裝,下載地址可以從GitHub項目中的wiki找到。安裝完成后記得將Tesseract 執行文件的目錄加入到PATH中,方便后續調用。
• linux環境下的安裝
sudo apt-get install tesseract-ocr
2 Python庫的安裝
# PIL用于打開圖片文件
pip/pip3 install pillow
# pytesseract模塊用于從圖片中解析數據
pip/pip3 install pytesseract
本次案例我們使用圖片識別引擎識別驗證碼登陸古詩文網
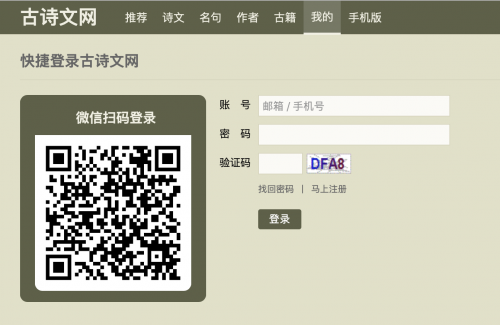
通過分析我們發現驗證碼點擊刷新的鏈接是:
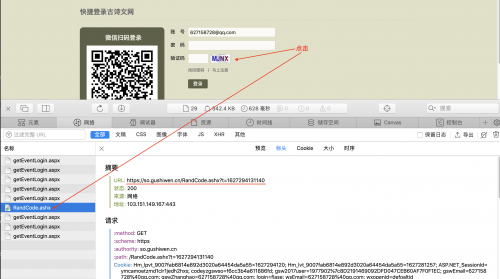
所以我們請求10次本鏈接獲取10張圖片,進行圖片識別
import time
from PIL import Image
import pytesseract
import requests
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
}
image_url = 'https://so.gushiwen.org/RandCode.ashx'
# 下載驗證碼圖片
session = requests.Session() # 使用session是為了保證驗證碼的請求和登陸請求信息一致
for i in range(10):
r = session.get(image_url, headers=headers)
with open('images/code'+str(i)+'.jpg', 'wb') as fp:
fp.write(r.content)
time.sleep(10)
print('下載完成第'+str(i)+'張!')
# 依次識別并保存到文件中
# 進行二值處理
def erzhihua(image, threshold):
''':type image:Image.Image'''
image = image.convert('L')
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
return image.point(table, '1')
# 對剛才保存的10張圖片進行識別
for i in range(10):
im = Image.open('images/code' + str(i) + '.jpg')
im = erzhihua(im, 127)
im.show()
result = pytesseract.image_to_string(im, lang='eng')
print(result)
但是很遺憾10次或者更多次數才能打碼成功一次。
打碼平臺
此時我們就要尋求專業的打碼平臺,申請第三方的平臺,宋宋試了一下阿里提供的各種免費的打碼平臺。鏈接:https://market.aliyun.com/products/?keywords=圖片識別驗證碼,但是識別效果不是很佳(哈哈因為是免費的緣故吧!只有標記優品的那個還不錯其他的也可以自行試一試)。
為了測試它的識別效果,我們嘗試申請成交次數最多的那個,查看官方API說明如下:
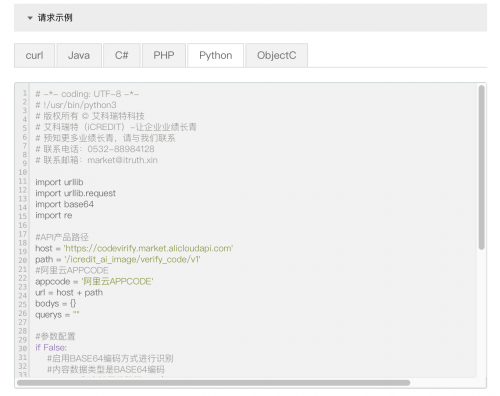
因此我們使用驗證碼打碼平臺獲取驗證碼并登錄
實現思路:
使用requests.session獲取圖片并進行本地保存
使用打碼平臺識別圖片
獲取登錄鏈接,登陸鏈接是一個post請求,并攜帶了你的表單中填入的用戶名和密碼
登陸獲取cookies, 才能去訪問用戶的個人頁
import json
from PIL import Image
import pytesseract
import requests
import urllib.request
import base64
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 1. 使用requests.session獲取圖片并進行本地保存
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
, 'Host': 'www.xqb5200.com'
, 'Referer': 'https://www.xqb5200.com/login.php'
}
session = requests.Session() # 使用session是為了保證驗證碼的請求和登陸請求信息一致
code_image_url = "https://www.xqb5200.com/checkcode.php"
r = session.get(code_image_url, headers=headers)
with open('code.jpg', 'wb') as fp:
fp.write(r.content)
# 2. 使用打碼平臺識別圖片
# 修改API說明修改接口地址
url = 'https://imgurlocr.market.alicloudapi.com/urlimages'
method = 'POST'
appcode = '你的APPCODE'
querys = ''
bodys = {}
f = open(r'code.jpg', 'rb')
contents = base64.b64encode(f.read())
f.close()
bodys['image'] = bytes("data:image/jpg;base64,", encoding="utf8")+contents
post_data = urllib.parse.urlencode(bodys).encode(encoding='UTF8')
request = urllib.request.Request(url, post_data)
# 根據API的要求,定義相對應的Content-Type
request.add_header('Content-Type', 'application/x-www-form-urlencoded; charset=UTF-8')
request.add_header('Authorization', 'APPCODE ' + appcode)
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
response = urllib.request.urlopen(request, context=ctx)
content = response.read()
if (content):
code = json.loads(content.decode('utf-8'))
print(code)
print(code['result']['words'])
# 3. 獲取登錄鏈接,登陸鏈接是一個post請求,并攜帶了你的表單中填入的用戶名和密碼
login_url = "https://www.xqb5200.com/login.php?do=submit"
# 用戶名和密碼大家可以注冊一個新的用戶
data = {
"username": "你的用戶名",
"password": "你的秘密",
"checkcode": code,
"action": "login",
"submit": "%26%23160%3B%B5%C7%26%23160%3B%26%23160%3B%C2%BC%26%23160%3B"
}
# 4. 登陸獲取cookies, 才能去訪問用戶的個人頁
response = session.post(url=login_url, headers=headers, data=data)
response.encoding = 'utf-8'
cookies = response.cookies
# 查看登陸是否成功了
with open('logsucess.html', 'wb') as fp:
response.encoding = response.apparent_encoding
fp.write(response.content)
這樣我們還是可以識別這個驗證碼的,如圖
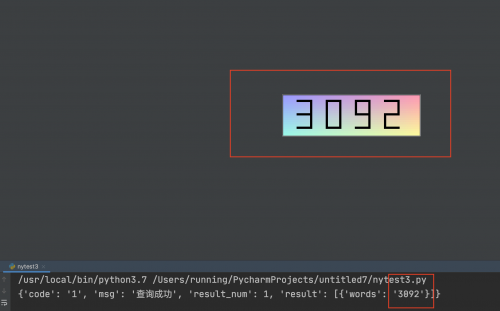
最后保存到本地的文件,顯示登陸成功
還有滑動驗證碼和點觸驗證碼的使用以及selenium+驗證碼登陸,期待下篇文章給大家分享...















 京公網安備 11010802030320號
京公網安備 11010802030320號