


在 Scrapy 中要抓取和解析一些邏輯內容和提取網站的鏈接,其實都是需要在 Spider 中完成的。在上一篇文章中我們介紹了Scarpy框架的簡單使用,后面一些文章我們要陸續介紹框架里面的Spider、配置、管道、中間件等。scrapy 框架分為spider爬蟲和CrawlSpider(規則爬蟲),本篇文章主要介紹Spider爬蟲的使用。
spider
在實現 Scrapy 爬蟲項目時,最核心的類就是 Spider 類了,它定義了如何爬取某個網站的流程和解析方式。簡單來講,Spider 要做的事就是如下兩件。
• 定義爬取網站的動作
• 分析爬取下來的網頁
對于 Spider 類來說,整個爬取循環如下所述。
• 以初始的 URL 初始化 Request,并設置回調函數。 當該 Request 成功請求并返回時,將生成 Response,并作為參數傳給該回調函數。
• 在回調函數內分析返回的網頁內容。返回結果可以有兩種形式,一種是解析到的有效結果返回字典或 Item 對象。下一步可經過處理后(或直接)保存,另一種是解析得下一個(如下一頁)鏈接,可以利用此鏈接構造 Request 并設置新的回調函數,返回 Request。
• 如果返回的是字典或 Item 對象,可通過 Feed Exports 等形式存入到文件,如果設置了 Pipeline 的話,可以經由 Pipeline 處理(如過濾、修正等)并保存。
• 如果返回的是 Reqeust,那么 Request 執行成功得到 Response 之后會再次傳遞給 Request 中定義的回調函數,可以再次使用選擇器來分析新得到的網頁內容,并根據分析的數據生成 Item。
通過以上幾步循環往復進行,便完成了站點的爬取。
我們以星巴克網站為例,為大家介紹Spider類,首先創建項目和創建爬蟲,具體步驟如下:
scrapy startproject starbuckspro
進入starbuckspro中,執行scrapy genspider starbucks https://www.starbucks.com.cn
此時我們就可以看到,有爬蟲文件產生如圖:
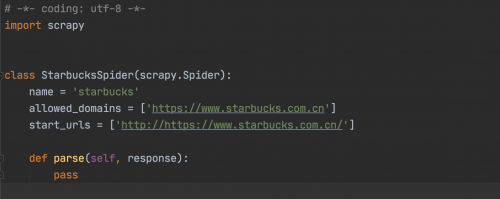
此時大家看到類:StarbucksSpider繼承自scrapy.Spider,這個類是最簡單最基本的 Spider 類,任何其他的 Spider 必須繼承這個類,包括后文要說明的一些特殊 Spider 類也都是繼承自它。這個類里提供了 startrequests () 方法的默認實現,讀取并請求 starturls 屬性,并根據返回的結果調用 parse () 方法解析結果。另外它還有一些基礎屬性,下面對其進行講解:
name: 爬蟲名稱,是定義 Spider 名字的字符串。Spider 的名字定義了 Scrapy 如何定位并初始化 Spider,所以其必須是唯一的。如果該 Spider 爬取單個網站,一個常見的做法是以該網站的域名名稱來命名 Spider。
allowed_domains:允許爬取的域名,是可選配置,不在此范圍的鏈接不會被跟進爬取。
start_urls:起始 URL 列表,當我們沒有實現 start_requests () 方法時,默認會從這個列表開始抓取。
當然還有custom_settings和settings,可以進行一些設置或者獲取一些全局的設置。而crawler屬性是由 from_crawler () 方法設置的,代表的是本 Spider 類對應的 Crawler 對象。
除了一些基礎屬性,Spider 還有一些常用的方法:
start_requests ():此方法用于生成初始請求,它必須返回一個可迭代對象,此方法會默認使用 start_urls 里面的 URL 來構造 Request,而且 Request 是 GET 請求方式。如果我們想在啟動時以 POST 方式訪問某個站點,可以直接重寫這個方法,發送 POST 請求時我們使用 FormRequest 即可。
parse ():當 Response 沒有指定回調函數時,該方法會默認被調用,它負責處理 Response,處理返回結果,并從中提取出想要的數據和下一步的請求,然后返回。該方法需要返回一個包含 Request 或 Item 的可迭代對象。
closed ():當 Spider 關閉時,該方法會被調用,在這里一般會定義釋放資源的一些操作或其他收尾操作。
當前星巴克的菜單頁面如上圖,我們要爬取里面的所有菜單名稱和圖片。parse()方法在 Response 沒有指定回調函數時,會默認被調用。所以里面的參數response就是我們獲取的頁面結果,我們要從頁面中提取想要的菜單名稱和圖片鏈接地址進行保存。于是我們要重寫parse()方法和定義Item.py文件
Item
在抓取數據的過程中,主要要做的事就是從雜亂的數據中提取出結構化的數據。Scrapy的Spider可以把數據提取為一個Python中的字典,雖然字典使用起來非常方便,對我們來說也很熟悉,但是字典有一個缺點:缺少固定結構。在一個擁有許多爬蟲的大項目中,字典非常容易造成字段名稱上的語法錯誤,或者是返回不一致的數據。
所以Scrapy中,定義了一個專門的通用數據結構:Item。這個Item對象提供了跟字典相似的API,并且有一個非常方便的語法來聲明可用的字段。
我們的Item的代碼內容如下(因為只需要保存名稱和圖片鏈接即可):
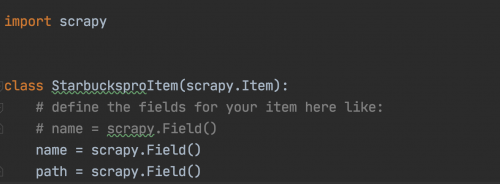
構建items.py文件完成后,還需要進一步處理爬取的數據,這就需要修改該項目中的pipelines.py文件。
Pipeline
Item Pipeline 是項目管道。也是保存結構數據的地。它的調用發生在 Spider 產生 Item 之后。當 Spider 解析完 Response 之后,Item 就會傳遞到 Item Pipeline,被定義的 Item Pipeline 組件會順次調用,完成一連串的處理過程,比如數據清洗、存儲等。 它的主要功能有:
• 清洗 HTML 數據
• 驗證爬取數據,檢查爬取字段
• 查重并丟棄重復內容
• 將爬取結果儲存到數據庫
定義Item非常簡單,只需要繼承scrapy.Item類,并將所有字段都定義為scrapy.Field類型即可。Field對象可用來對每個字段指定元數據。
其中經常使用的方法就是processitem () ,被定義的 Item Pipeline 會默認調用這個方法對 Item 進行處理。比如,我們可以進行數據處理或者將數據寫入到數據庫等操作。它必須返回 Item 類型的值或者拋出一個 DropItem 異常。 processitem () 方法的參數有如下兩個。
• item,是 Item 對象,即被處理的 Item
• spider,是 Spider 對象,即生成該 Item 的 Spider
所以我們的Pipeline代碼如下(將數據存儲到數據庫中):
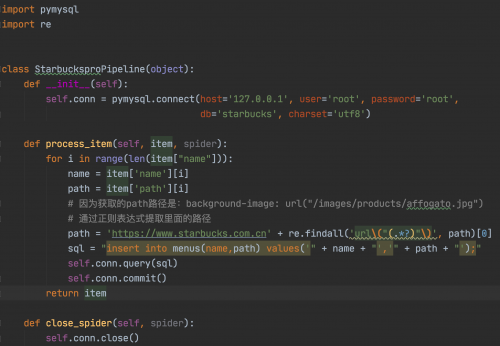
注意在settings.py中設置當前的Pipeline。

為了避免被發現爬蟲我們還可以在settings.py中,如下設置:


準備活動完成后,我們開始編寫我們的爬蟲文件,爬取頁面的分析如下圖
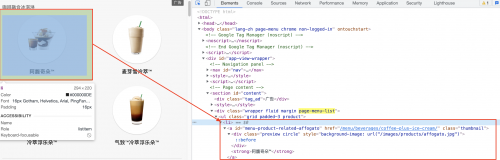
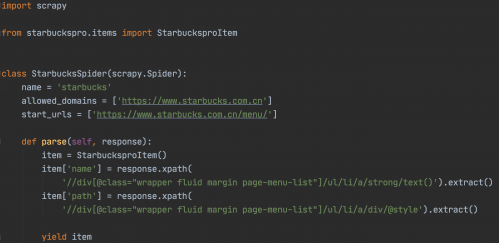
執行爬蟲通過命令:scrapy crawl starbucks,則最后的下載數據結果如下:
















 京公網安備 11010802030320號
京公網安備 11010802030320號