


Spider是什么?
• Spider是一個Scrapy提供的基本類,Scrapy中包含的其他基本類(例如CrawlSpider)以及自定義的spider都必須繼承這個類。
• Spider是定義如何抓取某個網站的類,包括如何執行抓取以及如何從其網頁中提取結構化數據。
源碼如下:
所有爬蟲的基類,用戶定義的爬蟲必須從這個類繼承
class Spider(object_ref):
#name是spider最重要的屬性,而且是必須的。一般做法是以該網站(domain)(加或不加 后綴 )來命名spider。 例如,如果spider爬取 mywebsite.com ,該spider通常會被命名為 mywebsite
name = None
#初始化,提取爬蟲名字,start_ruls
def __init__(self, name=None, **kwargs):
#判斷是否存在爬蟲名字name,沒有則會報錯
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python對象或類型通過內置成員__dict__來存儲成員信息
self.__dict__.update(kwargs)
#判斷是否存在start_urls列表,從列表中獲取到頁面的URL開始請求,后續的URL將會從獲取到的數據中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# Scrapy執行后的日志信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判斷對象object的屬性是否存在,不存在則做斷言處理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#該方法將讀取start_urls內的地址,并為每一個地址生成一個Request對象,交給Scrapy下載并返回Response
#注意:該方法僅調用一次
def start_requests(self):
for url in self.start_urls:
# 生成Request對象的函數
yield self.make_requests_from_url(url)
#Request對象默認的回調函數為parse(),提交的方式為get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默認的Request對象回調函數,處理返回的response。
#生成Item或者Request對象。用戶需要自己重寫該方法中的內容
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
因此可以總結出Scrapy爬取數據的過程如下:
Spider的入口方法(start_requests())請求start_urls列表中定義的url,返回Request對象(同時默認傳給它一個名為parse的回調函數)。
下載器獲取Respose后,回調函數會解析Reponse,返回(yield)的結果可能是字典、Item或是Request對象,亦或是這些對象組成的可迭代類型。其中,返回的Request也會包含一個回調函數,并在被下載之后被回調函數處理(即重復第2步)。
解析數據可以使用Scrapy自帶的Selectors工具或者lxml、BeautifulSoup等模塊。
最后Scrapy將返回的數據字典(或是Item對象)保存為文件或者保存在數據庫中。
scrapy.spider.Spider類介紹
常用類屬性
• name:是字符串。標識了每一個spider的名字,必須定義且唯一。實際中我們一般為每個獨立網站創建一個spider。
• starturl:是包含初始請求頁面url的列表,必須定義。`startrequests()方法會引用該屬性,發出初始的Request`。
• custom_settings:是一個字典,每一條鍵值對表示一個配置,可用于覆寫SETTINGS(Scrapy的全局配置模塊,位于settings.py文件中)。
•
– 例1:custom_settings = {'COOKIES_ENABLED': True,'ROBOTSTXT_OBEY': False}。覆蓋了全局屬性COOKIES_ENABLED。
– 擴展:設置settings中的值的幾種方法,優先級從高到低如下:
命令行選項
custom_settings
settings.py文件
命令行的默認設置,每一個命令行都有它自己的默認設置
默認的全局設置,被定義在 scrapy.settings.default_settings 中
• allowed_domains:是一個字符串列表。規定了允許爬取的網站域名,非域名下的網頁將被自動過濾。
•
– 例1:allowed_domains = cnblogs.com,start_url = 'https://www.zhihu.com'。在這個例子中,知乎不屬于CSDN的域名,因此爬取過程中會被過濾。
• crawler:是一個Crawler對象。可以通過它訪問Scrapy的一些組件(例如:extensions, middlewares, settings)。
•
– 例1:spider.crawler.settings.getbool('xxx')。這個例子中我們通過crawler訪問到了全局屬性。
• settings:是一個Settings對象。它包含運行中時的Spider的配置。這和我們使用spider.crawler.settings訪問是一樣的。
• logger:是一個Logger對象。根據Spider的name創建的,它記錄了事件日志。
常用方法
• start_requests:該方法是Spider的入口方法。默認下,該方法會請求start_url中定義的url,返回對應的Request,如果該方法被重寫,可以返回包含Request(作為第一個請求)的可迭代對象或者是FormRequest對象,一般POST請求重寫該方法。
• parse:當其他的Request沒有指定回調函數時,用于處理下載響應的默認回調,主要作用:負責解析返回的網頁數據(response.body),提取結構化數據(生成item)生成需要下一頁的URL請求。。該方法用于編寫解析網頁的具體邏輯(包含解析數據,或是解析出新的頁面),所以此方法非常重要哦!。
Spider案例:披荊斬棘的哥哥評論
最近被披荊斬棘的哥哥所吸引,但是還是要為大家做好服務,每天更新文章啊!介紹下這個綜藝節目哈。
《披荊斬棘的哥哥》是芒果TV推出的全景音樂競演綜藝。節目嘉賓們彼此挑戰,披荊斬棘,通過男人之間的彼此探索、家族建立的進程,詮釋“滾燙的人生永遠發光”,見證永不隕落的精神力。
我們本次使用Scrapy爬取哥哥們的評論。

分析思路:
打開谷歌瀏覽器,訪問第01期的鏈接(https://www.mgtv.com/b/367750/13107580.html),把JavaScript加載關掉,刷新,發現底下的評論數據沒有了,說明這數據是異步加載的,在這個網頁鏈接的源代碼里是找不到評論數據的;
既然是異步加載,那么就要抓包了。把剛剛關掉的JavaScript打開,重新加載網頁,右鍵檢查,Network, 數據一般都在XHR或者JS里面,所以先把這兩項勾選了,這時候點擊評論的下一頁,發現數據就在JS里面:
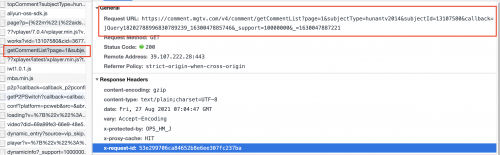
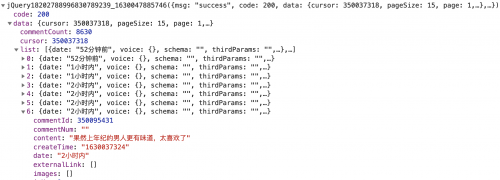
由上面評論的真實鏈接可以知道,評論真實的請求網址是:“https://comment.mgtv.com/v4/comment/getCommentList?”,后面跟著一系列的參數(callback, _support, subjectType, subjectId, page, _),可見:
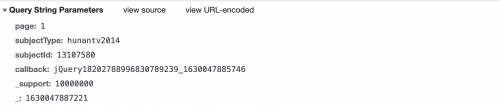
我們知道page是頁碼數,subjectId是s每個視頻對應的id,callback回調函數,最后一個大膽猜測下就是unix時間戳后面再加上3位隨機數(或者unix時間戳乘以1000再取整),應該只起一個占位的作用,可能是一個完全沒用的參數,只是用來嚇唬我們的。
但是不確定,我們來看一下,于是我去掉最后一個參數在瀏覽器發出了一下請求,結果如下:
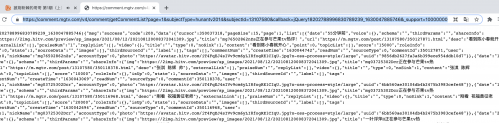
說明就是一個完全沒用的參數,哈哈哈用來嚇唬我們的,不要怕!我們不用它。
鏈接有了之后我們就開始創建爬蟲項目啦!
首先打開命令行,輸入:
scrapy startproject mongotv_comments_crawler
生成新的mongotvcommentscrawler項目,再輸入:
cd mongotv_comments_crawler
scrapy genspider mgtv_crawl mgtv.com
生成爬蟲名。
然后,用PyCharm打開項目。由于最后爬取到的是json數據,我們直接解析Json數據,并返回到Items中。
因此在爬蟲文件mgtv_crawl.py的MgtvCrawlSpider類中,進行如下定義:
class MgtvCrawlSpider(scrapy.Spider):
name = 'mgtv_crawl'
allowed_domains = ['mgtv.com']
# start_urls = ['http://mgtv.com/'] 因為我們每次都需要構建芒果TV的請求,所以我們重寫start_requests方法
subject_id = 4327535 # 視頻的id
pages = list(range(1, 100)) # 需要爬取的評論頁數比如100頁
因為我們要爬取多頁的內容,所以我們要不斷修改page參數,所以我們重寫start_requests方法
def start_requests(self): # 重寫start_requests
start_urls = [f'https://comment.mgtv.com/v4/comment/getCommentList?page={page}&subjectType=hunantv2014&subjectId={self.subject_id}&callback=jQuery18204988030991528978_1630030396693&_support=10000000&_=1630030399968' for page in self.pages]
# 生成所有需要爬取的url保存進start_urls
for url in start_urls: # 遍歷start_urls發出請求
yield Request(url)
然后重寫parse()函數,獲取json結果。但是json結果前面有下圖一樣的前綴內容,我們要去掉
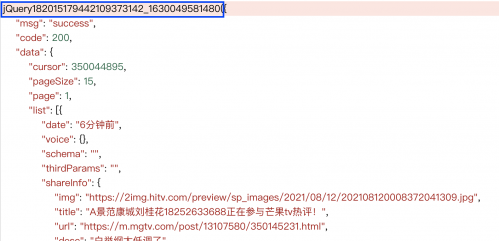
def parse(self, response):
text = response.text[response.text.find('{'):-1] # 通過字符串選取的方式把"jQuery...()去掉"
json_data = json.loads(text) # 轉換成json格式
for i in json_data['data']['list']: # 遍歷每頁的評論列表
item = MongotvCommentsCrawlerItem()
item['content'] = i['content']
item['commentId'] = i['commentId']
item['createTime'] = i['createTime']
item['nickName'] = i['user']['nickName']
yield item
編寫item,獲取評論的:內容、創建時間、用戶名和評論ID
class MongotvCommentsCrawlerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
createTime = scrapy.Field()
nickName = scrapy.Field()
commentId = scrapy.Field()
然后便是寫pipelines.py文件,把爬取回來的items入庫
import pymysql
class MongotvCommentsCrawlerPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='127.0.0.1', user='root', password='root',
db='mgtv', charset='utf8')
def process_item(self, item, spider):
commentId = item["commentId"]
content = item['content']
createTime = item['createTime']
nickName = item["nickName"]
sql = "insert into comments(commentId,content,createTime,nickName) values(" + str(commentId) + ",'" + content + "','" + createTime + "','" + nickName + "');"
self.conn.query(sql)
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
在settings.py中開啟對應的設置項:



開啟爬蟲進行爬取:
scrapy crawl mgtv_crawl
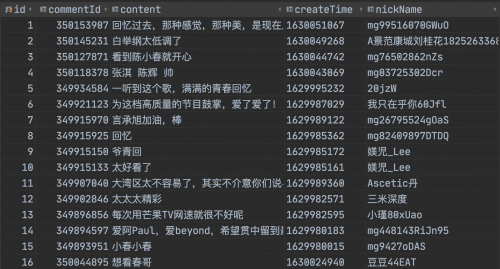
爬取到的結果如下:















 京公網安備 11010802030320號
京公網安備 11010802030320號