


Item Pipline介紹
對于Item pipline我們前面已經簡單的使用過了,更加詳細的使用本文給大家一一道來。
在我們開始學習Item Pipline之前,我們還是來看一下下面這張圖。
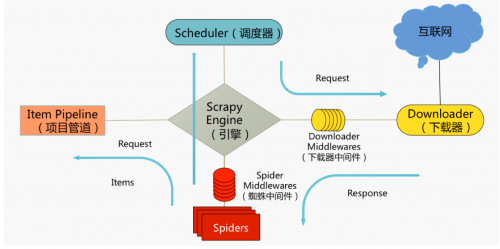
大家可以看到上圖最左側的就是Item Pipline。Item管道的主要任務就是負責處理有Spider從網頁中抽取的Item,因此Item Pipline的主要任務就是清洗、驗證和存儲數據。 當頁面被Spider解析后,將被發送到Item管道,Item Pipline獲取了Items中的數據并執行對應的方法,并決定是否需要在Item管道中繼續執行下一步或是直接丟棄掉不處理。
因此對于Item Pipline其主要的作用包括如下:
• 清理HTML數據。
• 驗證爬取數據,檢查爬取字段。
• 查重并丟棄重復內容。
• 將爬取結果保存到數據庫。
核心方法介紹
Item管道主要有4個方法,分別是:
(1)open_spider(spider)
(2)close_spider(spider)
(3)from_crawler(cls,crawler)
(4)process_item(item,spider)
open_spider(spider)【參數spider 即被開啟的Spider對象】
是在開啟spider的時候觸發的,常用于初始化操作(常見的有:開啟數據庫連接,打開文件等)。該方法非必需實現,可以根據需求定義。
close_spider(spider) 【參數spider 即被關閉的Spider對象】
是在 Spider 關閉的時候自動調用的,在這里我們可以做一些收尾工作,如關閉數據庫連接等,該方法非必需實現,可以根據需求定義。
from_crawler(cls,crawler)【參數一:Class類 參數二:crawler對象】
該方法Spider啟用時調用,比open_spider()方法調用還要早,是一個類方法,用@classmethod標識,是一種依賴注入的方式。它的參數有crawler,通過crawler對象,我們可以拿到Scrapy的所有核心組件,如全局配置的每個信息,然后創建一個Pipeline實例。參數cls就是Class,最后返回一個Class實例。
process_item(item,spider) 【參數一:被處理的Item對象 參數二:生成該Item的Spider對象】
該方法是必須要實現的方法,被定義的 Item Pipeline 會默認調用這個方法對 Item 進行處理。比如,我們可以進行數據處理或者將數據寫入到數據庫等操作。它必須返回 Item 類型的值或者拋出一個 DropItem 異常。
• 如果返回的是 Item 對象,那么此 Item 會接著被低優先級的 Item Pipeline 的 process_item () 方法進行處理,直到所有的方法被調用完畢。
• 如果拋出的是 DropItem 異常,那么此 Item 就會被丟棄,不再進行處理。
延伸擴展:ImagesPipline
爬蟲程序爬取的目標通常不僅僅是文字資源,經常也會爬取圖片資源。這就涉及如何高效下載圖片的問題。這里高效下載指的是既能把圖片完整下載到本地又不會對網站服務器造成壓力。此時你可以不在 pipeline 中自己實現下載圖片邏輯,可以通過 Scrapy 提供的圖片管道ImagesPipeline,這樣可以更加高效的操作下載圖片。
ImagesPipeline 具有以下特點:
• 將所有下載的圖片轉換成通用的格式(JPG)和模式(RGB)
• 避免重新下載最近已經下載過的圖片
• 縮略圖生成
• 檢測圖像的寬/高,確保它們滿足最小限制
使用說明:
在pipline.py中可以新定義一個類,比如:xxImagePipline,Scrapy 默認生成的類是繼承Object, 要將該類修改為繼承ImagesPipeline。然后實現get_media_requests和item_completed這兩個函數
其中,get_media_requests函數為每個 url 生成一個 Request。而item_completed(self, results, item, info)當一個單獨項目中的所有圖片請求完成時,該方法會被調用。
處理結果會以二元組的方式返回給 item_completed() 函數,即參數:results。
results參數二元組結果是:(success, imageinfoorfailure)
其中success表示圖片是否下載成功;imageinfoorfailure是一個字典,包含三個屬性:
url - 圖片下載的url。這是從 getmediarequests() 方法返回請求的url。
path - 圖片存儲的路徑(類似 IMAGES_STORE)
checksum - 圖片內容的 MD5 hash
如果需要file_path(request, response=None, info=None)
request表示當前下載對應的request對象(request.dict查看屬性),該方法用來返回文件名
response返回的是None
info一樣的返回是一個對象(info.dict查看)
同時需要結合settings.py的配置進行設置,比如設置配置存放圖片的路徑以及自定義下載的圖片管道。
# 可以避免下載最近已經下載的圖片,90天的圖片失效期限
IMAGES_EXPIRES = 90
IMAGES_STORE = '設置存放圖片的路徑'
# 如果需要也可以設置縮略圖
# IMAGES_THUMBS = {
# 'small': (50, 50), # (寬, 高)
# 'big': (270, 270),
# }
# 配置自定義下載的圖片管道, 默認是被注釋的
ITEM_PIPELINES = {
# yourproject.middlewares(文件名).middleware類
'項目名.pipelines.xxImagePipeline': 數值,
}
并且Scrapy 框架下載圖片會用到這個Python Imaging Library (PIL)圖片加載庫,所以也要提前安裝好這個庫。
pip install pillow
案例
本次我們爬取的網站是一個有很多治愈系圖片的網站,更加重要的是免費的。鏈接是:http://www.designerspics.com

我們要實現的在MongoDB中存儲,圖片的名字和下載地址,并將圖片下載到本地。因為我們前面存儲沒有使用過MongoDB或者Redis等非關系型數據庫,所以本次案例我們使用MongoDB存儲。
首先新建一個項目,命令如下:
scrapy startproject designerspics
接下來新建一個 Spider,命令如下:
scrapy genspider designer www.designerspics.com
這樣我們就成功創建了一個 Spider。
接下來使用PyCharm打開爬蟲項目,開始編寫爬蟲。
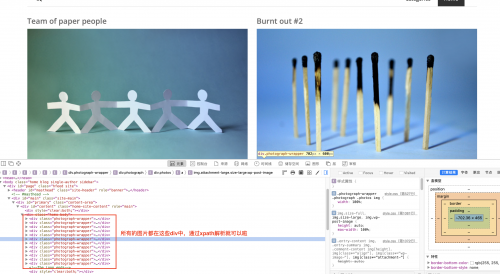
于是我們的爬蟲代碼就是(當然現在爬取的只是第一頁,如果是多頁爬取則需要重寫start_requests(self)方法):
import scrapy
from designerspics.items import DesignerspicsItem
class DesignerSpider(scrapy.Spider):
name = 'designer'
allowed_domains = ['www.designerspics.com']
start_urls = ['http://www.designerspics.com/']
def parse(self, response):
title = response.xpath('//div[@class="photograph-wrapper"]/div/h5[1]/text()').extract()
image_url = response.xpath('//div[@class="photograph-wrapper"]/div/div/a/img/@src').extract()
for index, t in enumerate(title):
item = DesignerspicsItem()
item['title'] = t[2:]
item['image_url'] = image_url[index]
yield item
如果多頁爬取則可以這樣寫,因為每一頁的地址是這樣的除了第一頁
第一頁:http://www.designerspics.com/
第二頁:http://www.designerspics.com/page/2/
第三頁:http://www.designerspics.com/page/3/
...
import scrapy
from scrapy import Request
from designerspics.items import DesignerspicsItem
class DesignerSpider(scrapy.Spider):
name = 'designer'
allowed_domains = ['www.designerspics.com']
# start_urls = ['http://www.designerspics.com/']
def start_requests(self):
# 爬取10頁內容
for i in range(1, 11):
if i == 1:
url = "http://www.designerspics.com/"
yield Request(url, self.parse)
else:
url = 'http://www.designerspics.com/page/' + str(i)+"/"
yield Request(url, self.parse)
def parse(self, response):
title = response.xpath('//div[@class="photograph-wrapper"]/div/h5[1]/text()').extract()
image_url = response.xpath('//div[@class="photograph-wrapper"]/div/div/a/img/@src').extract()
for index, t in enumerate(title):
item = DesignerspicsItem()
item['title'] = t[2:]
item['image_url'] = image_url[index]
yield item
其中DesignerspicsItem類的代碼如下:
import scrapy
class DesignerspicsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
collection = 'designerimages'
title = scrapy.Field()
image_url = scrapy.Field()
此時開始定義Item Pipline,打開piplines.py文件
import pymongo
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class DesignerspicsPipeline:
def __init__(self, mongo_uri, mongo_db, mongo_port):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.mongo_port = mongo_port
@classmethod
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB'),
mongo_port=crawler.settings.get('MONGO_PORT')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(host=self.mongo_uri, port=self.mongo_port)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
self.db[item.collection].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
class ImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item
def get_media_requests(self, item, info):
yield Request(item['image_url'])
此時需要在settings.py中配置:
MONGO_URI = '127.0.0.1'
MONGO_DB = 'designerimages'
MONGO_PORT = 27017
# 需要設置存儲圖片的路徑
IMAGES_STORE = './images'
啟動爬蟲:
scrapy crawl designer
來看一下成果吧!

Mongo數據庫的數據展示一下:

下篇預告:Scrapy分布式,歡迎分享!!!














 京公網安備 11010802030320號
京公網安備 11010802030320號