


一、物理內(nèi)存的組織形式:
由于物理內(nèi)存是連續(xù)的,頁也是連續(xù)的,每個頁的大小一樣,從0開始給每個頁編號,每個頁用struct page表示,存放在一個大數(shù)組里。因此對于任何一個地址,只要除以頁的大小,就可以得到對應(yīng)頁的編號,根據(jù)下標就可以找到對應(yīng)的struct page結(jié)構(gòu),這種模型是最經(jīng)典的平坦內(nèi)存模型:

所有的CPU總是通過總線去訪問內(nèi)存,這是最經(jīng)典的內(nèi)存使用方法,它可以使用平坦內(nèi)存模型來管理內(nèi)存:
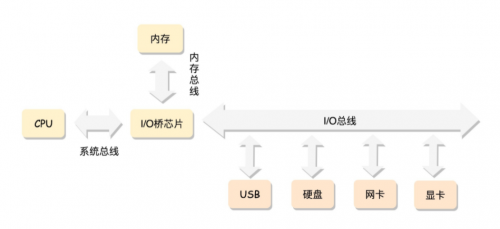
在這種模式下,所有的CPU都在總線的一側(cè),所有的內(nèi)存組成一大塊內(nèi)存在總線的另外一側(cè),CPU訪問內(nèi)存都需要通過總線訪問,而且距離都是一樣的,這種模式稱為SMP(Symmetric multiprocessing),即為對稱多處理器。這種模式有一個顯著的缺點,就是每個CPU訪問內(nèi)存都需要通過總線,那么總線就會成為瓶頸:
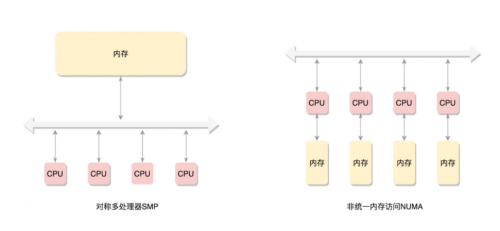
為了提高性能,有了一種更加高級的模式,NUMA(Non-uniform memory access),非一致內(nèi)存訪問。這種模式下,內(nèi)存不是組成連續(xù)的一大塊,而是每個CPU都有自己的一塊內(nèi)存,CPU訪問內(nèi)存不需要經(jīng)過總線,所以速度上會更快,每個CPU和內(nèi)存組成一個NUMA節(jié)點。但是在本地內(nèi)存不足的情況下,每個CPU會去其他NUMA節(jié)點申請內(nèi)存,此時內(nèi)存的訪問時間就比較長
這樣內(nèi)存被分為多個節(jié)點,每個節(jié)點都分成一個一個的頁。由于頁是全局唯一定位的,所以每個頁都需要有一個全局唯一的頁號。但是由于物理內(nèi)存不再是連續(xù)的,所以頁號也不是連續(xù)的,于是內(nèi)存模型就變成了非連續(xù)內(nèi)存模型,管理起來就會比較復(fù)雜。
二、節(jié)點:
下面解析當(dāng)前主流場景,NUMA方式。
為了表示一個NUMA節(jié)點,內(nèi)核定義了struct pglist_struct這樣一個結(jié)構(gòu)體,如下:

每個節(jié)點都有自己的ID:node_id
node_mem_map是這個節(jié)點struct page數(shù)組,用于描述這個節(jié)點所有的頁
node_start_pfn是這個節(jié)點的起始頁號
node_spanned_pages是整個物理內(nèi)存包含的頁數(shù)目(包括空洞)
node_present_pages是真正可用的物理頁數(shù)目
例如:64M物理內(nèi)存隔著4M的空洞,然后再是另外的64M,換算成頁數(shù)目,分別是16K、1K、16K。那么node_spanned_pages就是33K,node_spanned_pages就是32K
每個節(jié)點被分為一個一個的區(qū)域zone,存放在node_zones數(shù)組中,數(shù)組的大小為MAX_NR_ZONES,定義如下:
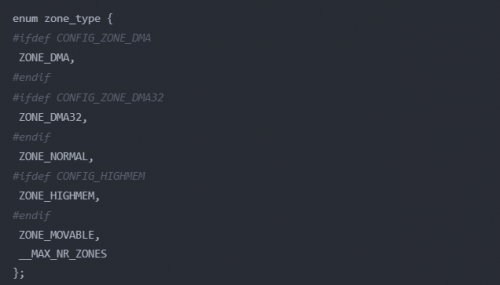
這里說明以下,這些分區(qū)都是對物理內(nèi)存的說明:
ZONE_DMA:用作DMA的物理內(nèi)存
ZONE_DMA32:對于64位CPU,還有這個DMA區(qū)域
ZONE_NORMAL:就是直接映射區(qū)
ZONE_MOVABLE:可移動區(qū)域,通過將物理內(nèi)存劃分為可移動分配區(qū)域和不可移動分配區(qū)域來避免內(nèi)存碎片
__MAX_NR_ZONES:內(nèi)存區(qū)域的數(shù)量
內(nèi)核中有一個數(shù)組用來存放節(jié)點:

三、區(qū)域:
到這里,將內(nèi)存分為節(jié)點,將節(jié)點分為區(qū)域,下面來看一看區(qū)域的定義
區(qū)域是zone結(jié)構(gòu)體表示:
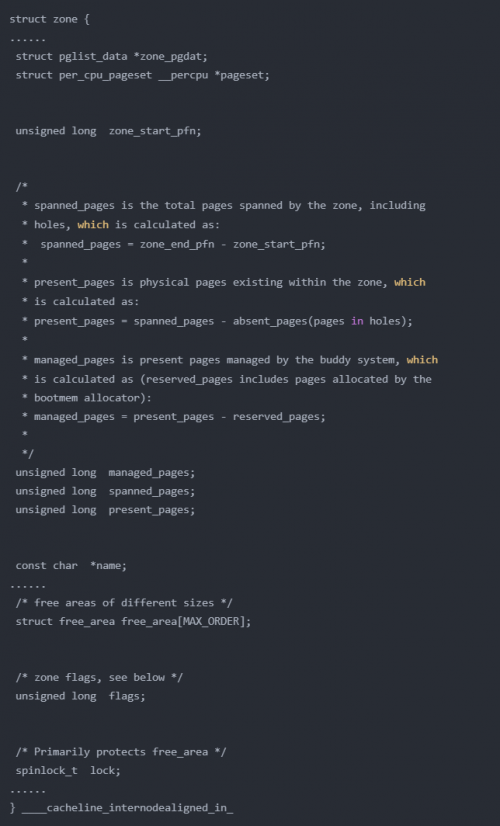
zone_start_pfn:表示這個屬于這個zone的第一個頁
spanned_pages:注釋里有spanned_pages = zone_end_pfn - zone_start_pfn,表示spanned_pages就是結(jié)束頁面減去起始頁面的頁面數(shù),不管中間是否存在空洞
present_pages:注釋里有spanned_pages - absent_pages(pages in holes),表示減去空洞后的頁面數(shù)
managed_pages:注釋中有managed_pages = present_pages - reserved_pages,表示這個zone中被伙伴系統(tǒng)管理的所有的page數(shù)目
per_cpu_pageset:用于區(qū)分冷熱頁。什么是冷熱頁?指的是一個頁是否被加載進CPU的高速緩存中。
四、頁:
在了解區(qū)域后,再來看組成物理內(nèi)存最基本的單位頁,頁的數(shù)組結(jié)構(gòu)使用struct page表示。這個結(jié)構(gòu)體定義非常的復(fù)雜,因為支持多種使用模式,所以定義了許多union:
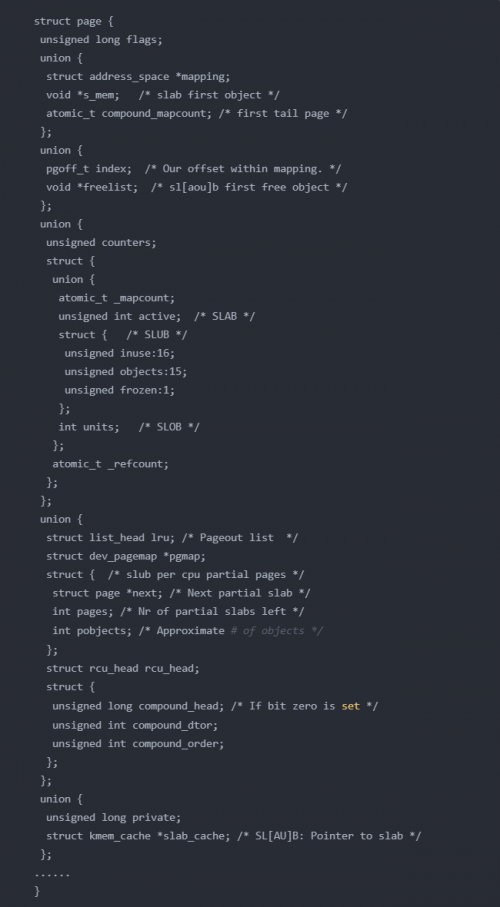
第一模式:
要用就使用一整頁。這一整頁的內(nèi)存要么直接跟虛擬地址建立映射關(guān)系,這中稱為匿名頁(Anonymous Page)。或者關(guān)聯(lián)一個文件,然后再跟虛擬地址建立映射
如果某一頁使用此模式,那么union就使用以下的結(jié)構(gòu):
struct address_space *mapping 就是用于內(nèi)存映射,如果是匿名頁,最低位為1;如果是映射文件,最低位為0
pgoff_t index 是映射區(qū)的偏移量
atomic_t _mapcount 每個進程都有自己的頁表,這個變量是指有多少個頁表映射到這個物理頁
struct list_head lru 表示這一頁應(yīng)該在鏈表上,如果這一頁被換出,那么就應(yīng)該在換出頁的鏈表中
compound相關(guān)的變量用于復(fù)合頁,就是將物理上連續(xù)的兩個或者多個看成一個獨立的大頁
第二種模式:
僅需要分配一小塊內(nèi)存,并不需要一整頁。為了滿足這種需求,Linux系統(tǒng)采用了一種被稱為slab allocator的技術(shù),用于分配slab中的一小塊內(nèi)存。它的基本工作原理是申請一整塊頁,然后劃分成許多小塊的存儲池,用復(fù)雜的隊列來維護這些小塊的狀態(tài)(被分配了 / 被放回池子了 / 應(yīng)該被回收)
slab對于隊列的維護過于復(fù)雜,后來出現(xiàn)了一種不使用隊列的分配器slub allocator,它保留的slab的用戶接口,可以把它看作是slab的另一種實現(xiàn)
還有一種小塊內(nèi)存的分配器slob
如果某一頁被切分為一小塊一小塊,那么union中就會使用以下結(jié)構(gòu):
s_mem 是已經(jīng)分配了正在使用的slab的第一個對象
freelist 是池子的空閑對象
rcu_head 是需要釋放的列表
五、頁的分配:
前面講了物理內(nèi)存的組織,從NUMA節(jié)點到區(qū)域到頁再到小塊。接下倆看物理內(nèi)存的分配
對于要分配比較大的內(nèi)存,例如分配頁級別的,可以使用伙伴系統(tǒng)(Buddy System)
Linux內(nèi)存管理的頁大小為4K。把所有空閑的頁分組為11個頁塊鏈表,每個鏈表管理相應(yīng)大小的頁塊,有1、2、4、8、16、32、64、128、256、512、1024個連續(xù)頁的頁塊。最大可以申請1024個連續(xù)的頁,對應(yīng)4M大小的連續(xù)內(nèi)存。每個頁塊第一頁的起始地址是該頁塊大小的整數(shù)倍:
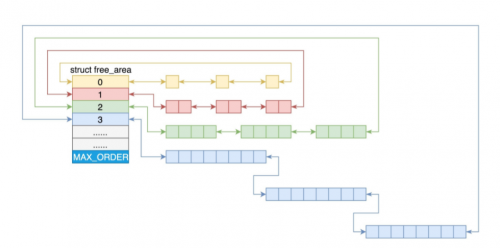
在 struct zone 里面有以下的定義:
struct free_area free_area[MAX_ORDER];
MAX_ORDER表示2的指數(shù):
#define MAX_ORDER 11
當(dāng)申請的頁塊大小介于free_area中兩個頁塊大小之間時,會選取更大的一個頁塊大小,或者如果對應(yīng)的大小沒有空閑的頁塊,那么也會分配一個更大的頁塊。在得到一個更大的頁塊后,會將其進行拆分,然后將空閑的頁塊繼續(xù)插入到對應(yīng)頁塊大小的鏈表中
例如申請一個128個頁的頁塊,如果沒有,那么就找256,然后一直如此,直到能夠找到。如果找到的是256個頁的頁塊。那么就會將其拆分為128和128個頁大小的頁塊,然后將一個空閑的頁塊添加到128對應(yīng)的頁塊鏈表中
對于這些內(nèi)容,可以在 alloc_pages 函數(shù)中找到定義:
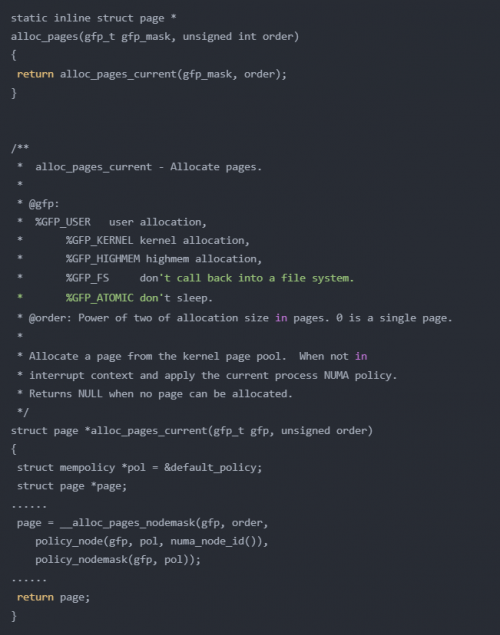
order:表示分配2的指數(shù)個頁的頁塊
gfp:分配標志,表示要分配那么區(qū)域的物理頁
GFP_USER 表示分配一個頁映射到用戶虛擬地址空間,并且希望直接被內(nèi)核或者硬件訪問,主要用于一個用戶進程希望通過內(nèi)存映射的方式,訪問硬件緩存(如顯卡緩存)
GFP_KERNEL 用于內(nèi)核中分配頁,主要分配 ZONE_NORMAL 區(qū)域的內(nèi)存
GFP_HIGHMEM 用于分配高端區(qū)域的物理內(nèi)存
接下來調(diào)用 get_page_from_freelist,這是伙伴系統(tǒng)的核心。它會先循環(huán)查找對應(yīng)節(jié)點的zone,如果找不到,那么就看備用節(jié)點的zone:
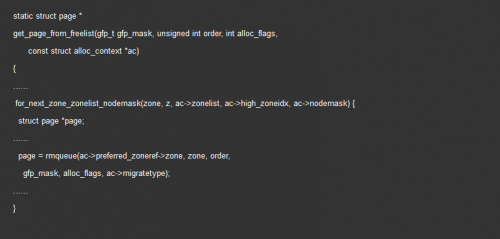
每一個zone,都有伙伴系統(tǒng)維護的各種大小的隊列
rmqueue 就是找到合適大小的隊列,然后將頁塊取下來
最終會調(diào)用到 __rmqueue_smallest:
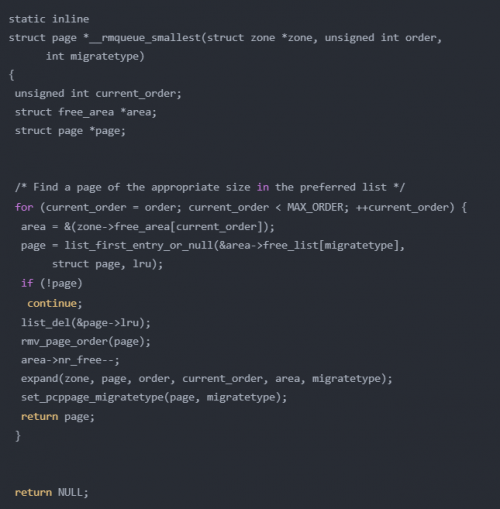
從指定的區(qū)域中,按照當(dāng)前指定的指數(shù)開始查找,如果找不到,那么就到更大的指數(shù)查找。除了將頁塊從鏈表取下,還要將多余的頁面插入到合適的鏈表中,expand 就是完成這個工作:
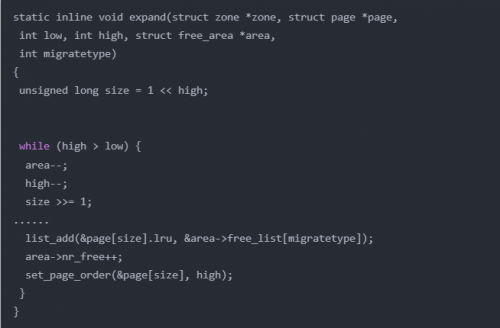
六、總結(jié):
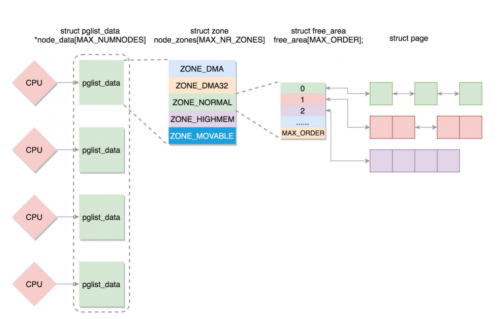
如果有多個CPU,就會有多個NUMA節(jié)點。每個節(jié)點使用 struct pglist_data 表示,存放在一個數(shù)組中
每個節(jié)點分為多個區(qū)域,每個區(qū)域使用 struct zone 表示,也存放在一個數(shù)組中
每個區(qū)域分為多個頁,空閑頁存放在 struct free_area 中,使用伙伴系統(tǒng)進行管理和分配
每一頁都是使用 struct page 表示:














 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號