


從瀏覽器的控制臺到運行Node.js的計算機終端,我們到處都會看到各類錯誤。
這篇文章的重點是概述我們在JS開發過程中可能遇到的錯誤類型。
1. RangeError
當數字超出允許的值范圍時,將拋出此錯誤。例如:

我們有一個帶有兩個元素的arr。接下來,我們嘗試使數組包含90**99 == 2.9512665430652753e+193元素。
這個數字超出了大小數組可以增長的范圍。所以運行時它會拋出RangeError:
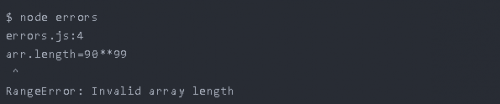
因為我們要增加arr數組的數量超出了JS指定的范圍。
2. ReferenceError
當對變量/項的引用被破壞或不存在時,將引發此錯誤。也就是說,變量/項不存在。
例如,

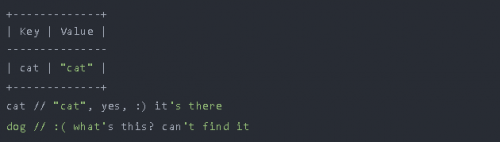
我們有一個變量cat初始化為“ cat”。接下來,我們引用cat變量和dog變量。cat變量存在,而dog變量不存在。
cat將返回“ cat”,而dog會引發ReferenceError,因為在環境記錄中找不到名為dog的變量。

每當我們創建或定義變量時,變量名稱都會寫入環境記錄中。此環境記錄就像鍵值存儲表一樣,如下圖:

每當我們引用變量時,它都會存儲程序中定義的變量。當在記錄中找到環境值并提取并返回值時,將以該變量的名稱作為關鍵字搜索環境記錄。調用尚未定義的函數。
現在,當我們創建或定義一個沒有賦值的變量時。變量將鍵作為變量名寫入環境記錄,但該值將保持未定義狀態。

稍后為變量分配值時,將在env記錄中搜索該變量,當發現該初始未定義值時,該賦值將被覆蓋。

因此,當在env記錄中找不到變量名時,JS引擎會拋出RefernceError。
注意:未定義的變量不會拋出ReferenceError,因為它存在于環境記錄中只是它的值尚未設置。
3. SyntaxError
這是我們遇到的最常見的錯誤。當我們鍵入JS引擎難以理解的代碼時,會出現此錯誤。解析期間,JS引擎捕獲了此錯誤。
在JS引擎中,我們的代碼經歷了不同的階段,然后才能在終端上看到運行結果。
標記化
解析
執行
標記化將源代碼分解為各個單元。在這個階段,將對數字,關鍵字,文字,運算符進行分類并分別進行標記。接下來,生成的token流將傳遞到解析階段,由解析器處理。這是從token生成AST的地方。AST是我們代碼結構的抽象數據結構。
在標記化和解析這兩個階段,如果我們代碼的語法不符合JS的語法規則,則會使執行階段失敗并引發SyntaxError。例如,

這里的“h”明顯是多余的,所以由于多了這個字符,會導致引擎拋出SyntaxError
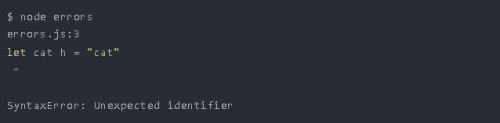
很顯然,Node.js引擎發現了錯誤,由于這個不和諧字符的出現,導致cat變量的聲明失敗了。
4. TypeError
TypeError 是指對象用來表示值的類型非預期類型時發生的錯誤。例如,我們期望它是布爾值,但結果發現它是string類型。
再例如:
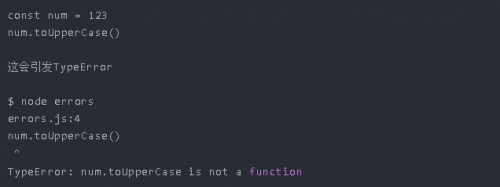
因為toUpperCase函數需要字符串數據類型。toUpperCase函數是有意通用的;它不需要其this值是String對象。因此,可以將其轉移到其他種類的對象中用作方法。
如果我們在Objects,Boolean,Symbol,null,undefined數據類型上調用toUpperCase函數,則只有字符串會轉換為大寫或小寫形式,我們將得到TypeError,因為它操作的數據類型錯誤。
5. URIError
這說明了使用一種全局URI處理功能與其定義不兼容。
JS中的URI(統一資源指示符)具有以下功能:decodeURI,decodeURIComponent等。
如果我們用錯誤的參數調用其中任何一個,我們將得到一個URIError。

encodeURI,獲取URI的未編碼版本。“%”不是正確的URI,因此引發了URIError。
編碼或解碼URI時出現問題時,將引發URIError。
6. EvalError
如果非法調用 eval(),則拋出 EvalError 異常。
根據EcmaSpec 2018版:
此異常不再會被JavaScript拋出,但是EvalError對象仍然保持兼容性。
7. InternalError
該錯誤在JS引擎內部發生,特別是當它有太多數據要處理并且堆棧增長超過其關鍵限制時。
當JS引擎被太多的遞歸,太多的切換情況等淹沒時,就會發生這種情況。
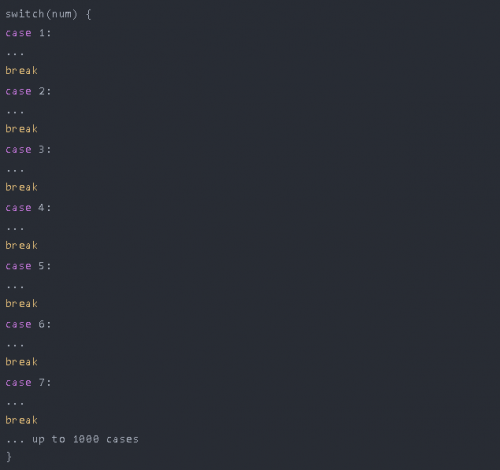
太多的遞歸,一個簡單的例子是這樣的:

結論
正如我們所說,沒有人能不犯錯誤。就我們輸入的代碼而言,發生錯誤是難以避免的。
不過為了避免更多的錯誤出現,我們需要知道拋出的錯誤的類型是什么,我們該如何解決。
所以我們在這篇文章中列出了它們,并提供了一些示例來簡要的來介紹了它們是如何發生的。

















 京公網安備 11010802030320號
京公網安備 11010802030320號