


Python爬蟲庫urllib使用詳解!
一、Python urllib庫
Python urllib 庫用于操作網(wǎng)頁 URL,并對網(wǎng)頁的內(nèi)容進(jìn)行抓取處理。
Python3 的 urllib。
urllib 包 包含以下幾個模塊:
●urllib.request - 打開和讀取 URL。
●urllib.error - 包含 urllib.request 拋出的異常。
●urllib.parse - 解析 URL。
●urllib.robotparser - 解析 robots.txt 文件。
二、urllib.request模塊
urllib.request 定義了一些打開 URL 的函數(shù)和類,包含授權(quán)驗證、重定向、瀏覽器 cookies等。
urllib.request 可以模擬瀏覽器的一個請求發(fā)起過程。
這里主要介紹兩個常用方法,urlopen和Request。
1.urlopen函數(shù)
語法格式如下:

url:url 地址。
data:發(fā)送到服務(wù)器的其他數(shù)據(jù)對象,默認(rèn)為 None。
timeout:設(shè)置訪問超時時間。
cafile 和 capath:cafile 為 CA 證書, capath 為 CA 證書的路徑,使用 HTTPS 需要用到。
cadefault:已經(jīng)被棄用。
context:ssl.SSLContext類型,用來指定 SSL 設(shè)置。
示例:

運行結(jié)果:

response對象是http.client. HTTPResponse類型,主要包含 read、readinto、getheader、getheaders、fileno 等方法,以及 msg、version、status、reason、debuglevel、closed 等屬性。
常用方法:
read():是讀取整個網(wǎng)頁內(nèi)容,也可以指定讀取的長度,如read(300)。獲取到的是二進(jìn)制的亂碼,所以需要用到decode()命令將網(wǎng)頁的信息進(jìn)行解碼。
readline() - 讀取文件的一行內(nèi)容。
readlines() - 讀取文件的全部內(nèi)容,它會把讀取的內(nèi)容賦值給一個列表變量。
info():返回HTTPMessage對象,表示遠(yuǎn)程服務(wù)器返回的頭信息。
getcode():返回Http狀態(tài)碼。如果是http請求,200請求成功完成;404網(wǎng)址未找到。
geturl():返回請求的url。
2、Request類
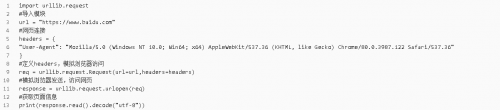
我們抓取網(wǎng)頁一般需要對 headers(網(wǎng)頁頭信息)進(jìn)行模擬,否則網(wǎng)頁很容易判定程序為爬蟲,從而禁止訪問。這時候需要使用到 urllib.request.Request 類:

url:url 地址。
data:發(fā)送到服務(wù)器的其他數(shù)據(jù)對象,默認(rèn)為 None。
headers:HTTP 請求的頭部信息,字典格式。
origin_req_host:請求的主機(jī)地址,IP 或域名。
unverifiable:很少用整個參數(shù),用于設(shè)置網(wǎng)頁是否需要驗證,默認(rèn)是False。。
method:請求方法, 如 GET、POST、DELETE、PUT等。
示例:
三、urllib.error模塊
urllib.error 模塊為 urllib.request 所引發(fā)的異常定義了異常類,基礎(chǔ)異常類是 URLError。
urllib.error 包含了兩個方法,URLError 和 HTTPError。
URLError 是 OSError 的一個子類,用于處理程序在遇到問題時會引發(fā)此異常(或其派生的異常),包含的屬性 reason 為引發(fā)異常的原因。
HTTPError 是 URLError 的一個子類,用于處理特殊 HTTP 錯誤例如作為認(rèn)證請求的時候,包含的屬性 code 為 HTTP 的狀態(tài)碼, reason 為引發(fā)異常的原因,headers 為導(dǎo)致 HTTPError 的特定 HTTP 請求的 HTTP 響應(yīng)頭。
區(qū)別:
URLError封裝的錯誤信息一般是由網(wǎng)絡(luò)引起的,包括url錯誤。
HTTPError封裝的錯誤信息一般是服務(wù)器返回了錯誤狀態(tài)碼。
關(guān)系:
URLError是OSERROR的子類,HTTPError是URLError的子類。
1.URLError 示例
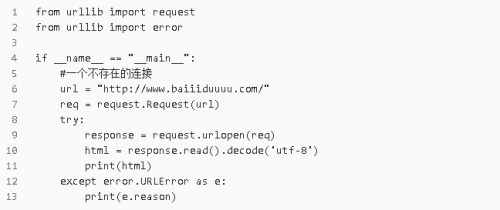
返回結(jié)果:

reason:
此錯誤的原因。它可以是一個消息字符串或另一個異常實例。
2.HTTPError示例
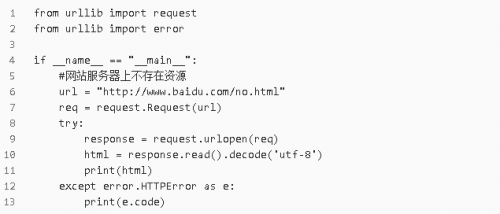
返回結(jié)果:

code
一個 HTTP 狀態(tài)碼,具體定義見 RFC 2616。這個數(shù)字的值對應(yīng)于存放在
http.server.BaseHTTPRequestHandler.responses 代碼字典中的某個值。
reason
這通常是一個解釋本次錯誤原因的字符串。
headers
導(dǎo)致 HTTPError 的特定 HTTP 請求的 HTTP 響應(yīng)頭。
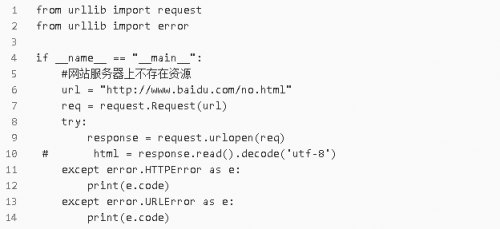
3.URLError和HTTPError混合使用
注意:由于HTTPError是URLError的子類,所以捕獲的時候HTTPError要放在URLError的上面。
示例:
如果不用上面的方法,可以直接用判斷的形式。
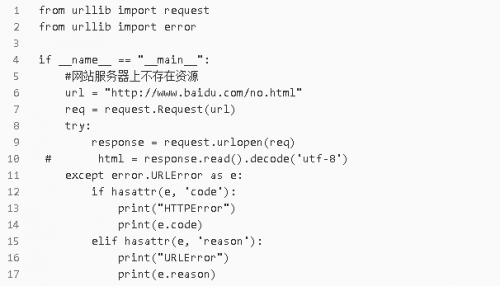
執(zhí)行結(jié)果:

四、urllib.parse模塊
模塊定義的函數(shù)可分為兩個主要門類: URL 解析和 URL 轉(zhuǎn)碼。
4.1 URL 解析
4.1.1 urlparse()
urllib.parse 用于解析 URL,格式如下:

urlstring 為 字符串的 url 地址,scheme 為協(xié)議類型。
allow_fragments 參數(shù)為 false,則無法識別片段標(biāo)識符。相反,它們被解析為路徑,參數(shù)或查詢組件的一部分,并 fragment 在返回值中設(shè)置為空字符串。
標(biāo)準(zhǔn)鏈接格式為:
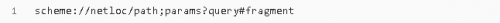
對象中包含了六個元素,分別為:協(xié)議(scheme)、域名(netloc)、路徑(path)、路徑參數(shù)(params)、查詢參數(shù)(query)、片段(fragment)。
示例:

執(zhí)行結(jié)果:

以上還可以通過索引獲取,如通過

4.1.2 urlunparse()
urlunparse()可以實現(xiàn)URL的構(gòu)造。(構(gòu)造URL)
urlunparse()接收一個是一個長度為6的可迭代對象,將URL的多個部分組合為一個URL。若可迭代對象長度不等于6,則拋出異常。
示例:

結(jié)果:
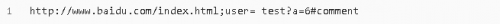
4.1.3 urlsplit()
urlsplit() 函數(shù)也能對 URL 進(jìn)行拆分,所不同的是, urlsplit() 并不會把 路徑參數(shù)(params) 從 路徑(path) 中分離出來。
當(dāng) URL 中路徑部分包含多個參數(shù)時,使用 urlparse() 解析是有問題的,這時可以使用 urlsplit() 來解析.
4.1.4 urlsplit()
urlunsplit()與 urlunparse()類似,(構(gòu)造URL),傳入對象必須是可迭代對象,且長度必須是5。
示例:

結(jié)果:

4.1.5 urljoin()
同樣可以構(gòu)造URL。
傳遞一個基礎(chǔ)鏈接,根據(jù)基礎(chǔ)鏈接可以將某一個不完整的鏈接拼接為一個完整鏈接.
注:連接兩個參數(shù)的url, 將第二個參數(shù)中缺的部分用第一個參數(shù)的補(bǔ)齊,如果第二個有完整的路徑,則以第二個為主。
4.2 URL 轉(zhuǎn)碼
python中提供urllib.parse模塊用來編碼和解碼,分別是urlencode()與unquote()。
4.2.1 編碼quote(string)
URL 轉(zhuǎn)碼函數(shù)的功能是接收程序數(shù)據(jù)并通過對特殊字符進(jìn)行轉(zhuǎn)碼并正確編碼非 ASCII 文本來將其轉(zhuǎn)為可以安全地用作 URL 組成部分的形式。它們還支持逆轉(zhuǎn)此操作以便從作為 URL 組成部分的內(nèi)容中重建原始數(shù)據(jù),如果上述的 URL 解析函數(shù)還未覆蓋此功能的話
語法:

使用 %xx 轉(zhuǎn)義符替換 string 中的特殊字符。字母、數(shù)字和 '_.-~' 等字符一定不會被轉(zhuǎn)碼。在默認(rèn)情況下,此函數(shù)只對 URL 的路徑部分進(jìn)行轉(zhuǎn)碼。可選的 safe 形參額外指定不應(yīng)被轉(zhuǎn)碼的 ASCII 字符 --- 其默認(rèn)值為 '/'。
string 可以是 str 或 bytes 對象。
示例:

執(zhí)行結(jié)果:
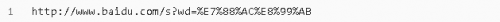
4.2.2 編碼urlencode()
quote()只能對字符串編碼,而urlencode()可以對查詢字符串進(jìn)行編碼。

結(jié)果:
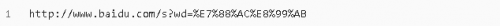
4.2.3 解碼unquote(string)
解碼就是對編碼后的url進(jìn)行還原。
示例:

執(zhí)行結(jié)果:

五、urllib.robotparser模塊
(在網(wǎng)絡(luò)爬蟲中基本不會用到,使用較少,僅作了解)
urllib.robotparser 用于解析 robots.txt 文件。
robots.txt(統(tǒng)一小寫)是一種存放于網(wǎng)站根目錄下的 robots 協(xié)議,它通常用于告訴搜索引擎對網(wǎng)站的抓取規(guī)則。
Robots協(xié)議也稱作爬蟲協(xié)議,機(jī)器人協(xié)議,網(wǎng)絡(luò)爬蟲排除協(xié)議,用來告訴爬蟲哪些頁面是可以爬取的,哪些頁面是不可爬取的。它通常是一個robots.txt的文本文件,一般放在網(wǎng)站的根目錄上。
當(dāng)爬蟲訪問一個站點的時候,會首先檢查這個站點目錄是否存在robots.txt文件,如果存在,搜索爬蟲會根據(jù)其中定義的爬取范圍進(jìn)行爬取。如果沒有找到這個文件,搜索爬蟲會訪問所有可直接訪問的頁面。
urllib.robotparser 提供了 RobotFileParser 類,語法如下:

這個類提供了一些可以讀取、解析 robots.txt 文件的方法:
set_url(url) - 設(shè)置 robots.txt 文件的 URL。
read() - 讀取 robots.txt URL 并將其輸入解析器。
parse(lines) - 解析行參數(shù)。
can_fetch(useragent, url) - 如果允許 useragent 按照被解析 robots.txt 文件中的規(guī)則來獲取 url 則返回 True。
mtime() -返回最近一次獲取 robots.txt 文件的時間。這適用于需要定期檢查 robots.txt 文件更新情況的長時間運行的網(wǎng)頁爬蟲。
modified() - 將最近一次獲取 robots.txt 文件的時間設(shè)置為當(dāng)前時間。
crawl_delay(useragent) -為指定的 useragent 從 robots.txt 返回 Crawl-delay 形參。如果此形參不存在或不適用于指定的 useragent 或者此形參的 robots.txt 條目存在語法錯誤,則返回 None。
request_rate(useragent) -以 named tuple RequestRate(requests, seconds) 的形式從 robots.txt 返回 Request-rate 形參的內(nèi)容。如果此形參不存在或不適用于指定的 useragent 或者此形參的 robots.txt 條目存在語法錯誤,則返回 None。
site_maps() - 以 list() 的形式從 robots.txt 返回 Sitemap 形參的內(nèi)容。如果此形參不存在或者此形參的 robots.txt 條目存在語法錯誤,則返回 None。

















 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號