


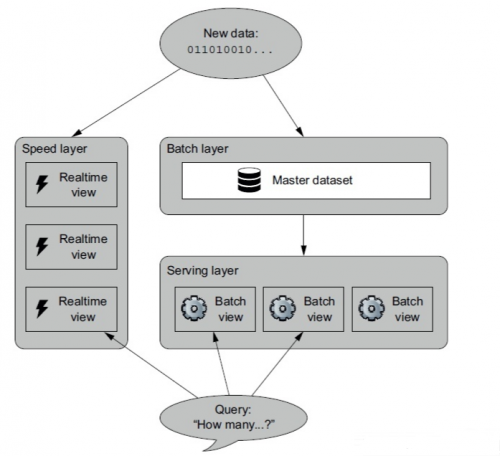
lambda架構(gòu)從這點出發(fā), 有兩套解決辦法, 正如圖上的兩條分支, 一條叫Speed Layer 顧名思義 快速的處理實時數(shù)據(jù)以供查詢, 而另一條分支, 又分作兩層(Batch Layer & Serving Layer) 處理那些對時效性要求不高的數(shù)據(jù)。
Speed Layer處理實時數(shù)據(jù) 代價是對計算資源要求很高, 而且邏輯復(fù)雜度也會很高, 通常采用的技術(shù)比如Redis,Storm,Kafka,Spark Streaming等。而另外兩層使用的典型技術(shù)比如MR或Spark,Hive。這條路線處理延遲比較大, 結(jié)果邏輯相對簡單,往往把它的處理叫做“離線處理”, 與Speed Layer的“實時處理”相對應(yīng)。這種設(shè)計被稱作:Complexity Isolation(復(fù)雜度分離)。
兩者其實是相輔相成的, Batch Layer會持續(xù)地吸收增量數(shù)據(jù)加以處理(比如漸變維度,增加索引,劃分分區(qū),預(yù)計算聚合值等操作), 當新增數(shù)據(jù)被Batch Layer處理完成后, 它們的分析就不再由Speed Layer處理了(交由Serving Layer處理),所以保證了Speed Layer處理的歷史數(shù)據(jù)量永遠不會太大,畢竟對于Speed Layer來說 “快” 是關(guān)鍵。















 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號