


一. 概述
在程序員這個群體的日常工作中,我們經常會聽到一個詞----算法;也經常接觸一個崗位----算法工程師。那么究竟什么是算法,作為一個程序員又需要掌握哪些算法那?
度娘對計算機算法的定義如下:
計算機算法是以一步接一步的方式,來詳細描述計算機該如何將輸入轉化為所要求的輸出的過程。或者說,算法是對計算機上執行的計算過程的具體描述。
這個解釋有些小伙伴可能不是很能理解,那索爾就用一個容易理解例子給大家說一下:
比如有一個數組,存儲了10個隨機存入的整數,我們想對這個數組進行排序。在這個排序的過程中,其實就用到了算法--排序算法。
再比如我們想要在一組數據中找到某個具體的數據,這個查找的過程也會用到算法--查找算法。
二. 常用算法
作為一個程序員,我們在開發過程中還真的需要了解和使用一些算法來幫助我們完成編碼工作,下面索爾就來給大家介紹幾種常用的算法:
冒泡排序
選擇排序
插入排序
快速排序
二分查找
二叉樹算法
Dijkstra算法
字符串查找算法
1. 冒泡排序
1.1 算法簡介
冒泡排序(Bubble Sort)是一種較為簡單的排序算法。它會重復地走訪要排序的元素列,依次比較兩個相鄰的元素,如果順序(如從大到小、首字母從Z到A)錯誤就把他們交換過來。走訪元素的工作會重復地進行,直到沒有相鄰元素需要交換為止,也就是說直到該元素列完成排序。
這個算法之所以叫這個名字,是因為越小的元素經過交換會慢慢“浮”到數列的最頂端(升序或降序排列),就如同碳酸飲料中二氧化碳的氣泡最終會上浮到最頂端一樣,故名“冒泡排序”。
1.2 冒泡原理
冒泡算法的基本原理就是比較相鄰的兩個元素,如果第一個比第二個大,就交換他們兩個。然后對每一對相鄰的兩個元素進行同樣的工作,從第一對開始,直到最后的一對結尾,等到最后的元素應該就是最大的元素。
我們只需要針對所有的元素,重復以上的步驟,除了最后一個。所以持續對越來越少的元素重復上面的步驟,直到沒有任何一對數字需要比較為止。
我們可以參考下圖來理解冒泡算法:

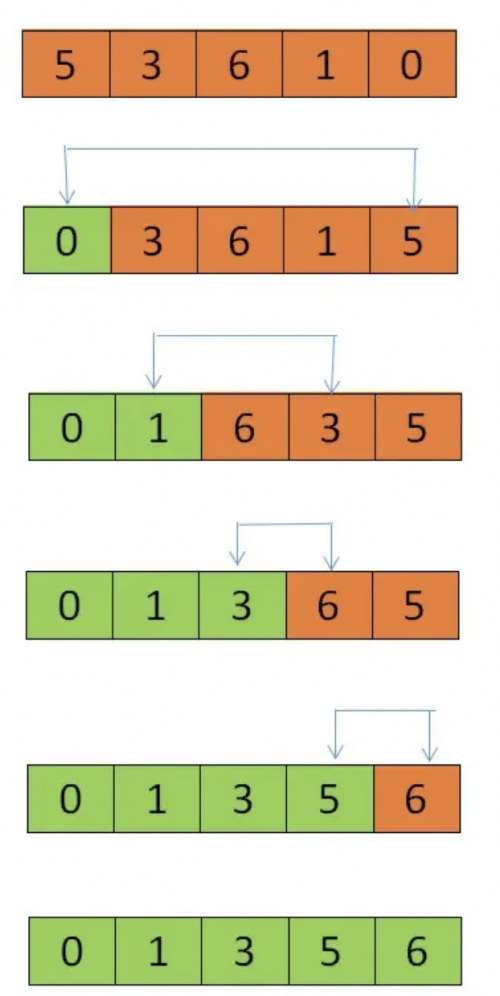
2. 選擇排序
選擇排序(Selection sort)是一種簡單直觀的排序算法,這是一種不穩定的排序方法,其工作原理是:
第一次從待排序的數據元素中選出最小(或最大)的一個元素,存放在序列的起始位置;
然后再從剩余的未排序元素中尋找到最小(大)的元素,然后再放到已排序的序列末尾;
以此類推,直到全部待排序的數據元素的個數為零。
3. 插入排序
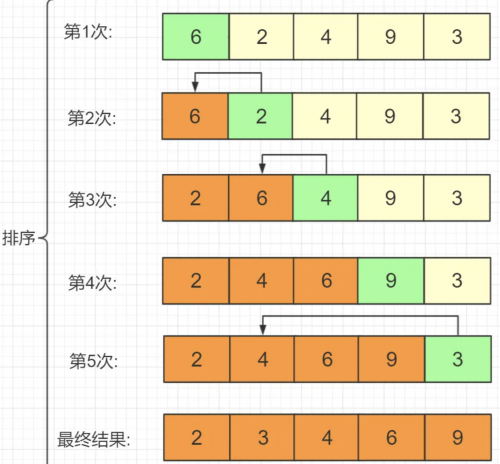
3.1 算法簡介
插入排序一般也被稱為直接插入排序。對于少量元素的排序,它是一個有效的算法。插入排序是一種最簡單的排序方法,它的基本思想是將一個記錄插入到已經排好序的有序表中,從而一個新的、記錄數增1的有序表。在其實現過程使用雙層循環,外層循環對除了第一個元素之外的所有元素,內層循環對當前元素前面有序表進行待插入位置查找,并進行移動。
3.2 插入原理
插入排序的工作方式像許多人排序一手撲克牌。開始時,我們的左手為空并且桌子上的牌面向下。然后,我們每次從桌子上拿走一張牌并將它插入左手中正確的位置。為了找到一張牌的正確位置,我們從右到左將它與已在手中的每張牌進行比較。拿在左手上的牌總是排序好的,原來這些牌是桌子上牌堆中頂部的牌。
插入排序是指在待排序的元素中,假設前面n-1(其中n>=2)個數已經是排好順序的,現將第n個數插到前面已經排好的序列中,然后找到合適自己的位置,使得插入第n個數的這個序列也是排好順序的。按照此法對所有元素進行插入,直到整個序列排為有序的過程,稱為插入排序。
4. 快速排序
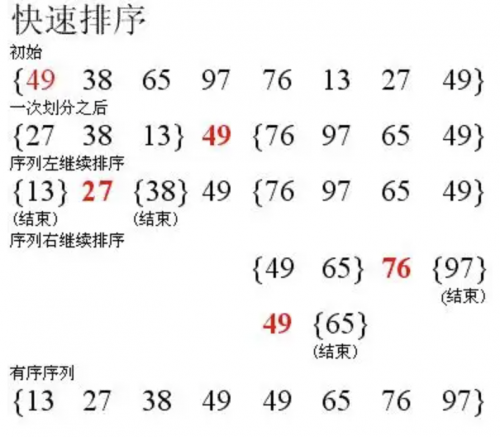
快速排序(Quicksort)是對冒泡排序算法的一種改進,其基本原理如下:
設要排序的數組是A[0]……A[N-1],首先任意選取一個數據(通常選用數組的第一個數)作為關鍵數據,然后將所有比它小的數都放到它左邊,所有比它大的數都放到它右邊,這個過程稱為一趟快速排序。值得注意的是,快速排序不是一種穩定的排序算法,也就是說,多個相同的值的相對位置也許會在算法結束時產生變動。這樣一趟快速排序的算法是:
設置兩個變量i、j,排序開始的時候:i=0,j=N-1;
以第一個數組元素作為關鍵數據,賦值給key,即key=A[0];
從j開始向前搜索,即由后開始向前搜索(j--),找到第一個小于key的值A[j],將A[j]和A[i]的值交換;
從i開始向后搜索,即由前開始向后搜索(i++),找到第一個大于key的A[i],將A[i]和A[j]的值交換;
重復第3、4步,直到i==j;(3,4步中,沒找到符合條件的值,即3中A[j]不小于key,4中A[i]不大于key的時候改變j、i的值,使得j=j-1,i=i+1,直至找到為止。找到符合條件的值,進行交換的時候i, j指針位置不變。另外,i==j這一過程一定正好是i+或j-完成的時候,此時令循環結束)。
5. 二分查找
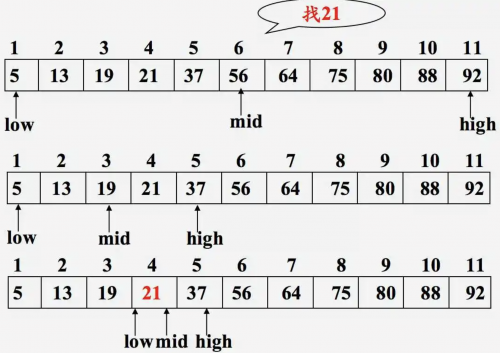
5.1 算法簡介
二分查找也稱折半查找(Binary Search),這是一種效率較高的查找方法。但折半查找要求線性表必須采用順序存儲結構,而且表中元素按關鍵字有序排列。
5.2 算法原理
首先,假設表中元素是按升序排列,將表中間位置記錄的關鍵字與查找關鍵字比較,如果兩者相等,則查找成功;
否則利用中間位置記錄將表分成前、后兩個子表,如果中間位置記錄的關鍵字大于查找關鍵字,則進一步查找前一子表,否則進一步查找后一子表;
重復以上過程,直到找到滿足條件的記錄,使查找成功,或直到子表不存在為止,此時查找不成功。
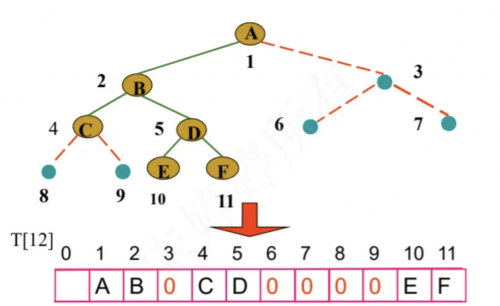
6. 二叉樹算法
6.1 算法簡介
二叉樹的每個結點至多只有二棵子樹(不存在度大于2的結點),二叉樹的子樹有左右之分,次序不能顛倒。二叉樹的第i層至多有2^(i-1)個節點。深度為k的二叉樹至多有2^k- 1個結點; 對任何一棵二叉樹T,如果其終端結點數為n0,度為2的結點數為n2,則n0 = n2 + 1。二叉樹算法常被用于實現二叉查找樹和二叉堆。
二叉樹是每個節點最多有兩個子樹的有序樹,通常子樹被稱作“左子樹”(left subtree)和"右子樹"(right subtree)。二叉樹常被用于實現二叉查找樹和二叉堆。
6.2 算法特性
二叉樹算法通常具有如下特性:
(1). 在二叉樹中,第i層的結點總數不超過2^(i-1);
(2). 深度為h的二叉樹最多有2^h-1個結點(h>=1),最少有h個結點;
(3). 對于任意一棵二叉樹,如果其葉結點數為N0,而度數為2的結點總數為N2,則N0=N2+1;
(4). 具有n個結點的完全二叉樹的深度為int(log2n)+1
(5). 有N個結點的完全二叉樹各結點如果用順序方式存儲,則結點之間有如下關系:若I為結點編號則 如果I>1,則其父結點的編號為I/2;如果2*IN,則無左兒子;如果2*I+1N,則無右兒子。
(6). 給定N個節點,能構成h(N)種不同的二叉樹。h(N)為卡特蘭數的第N項。h(n)=C(n,2*n)/(n+1)。
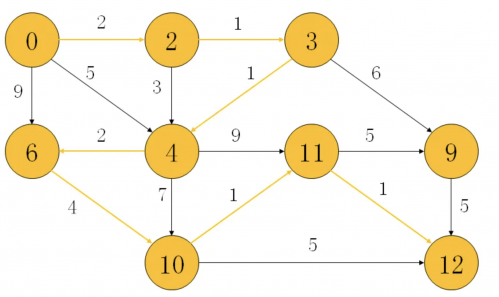
7. Dijkstra算法
迪杰斯特拉算法(Dijkstra)是由荷蘭計算機科學家狄克斯特拉于1959年提出的,因此又叫狄克斯特拉算法。是從一個頂點到其余各頂點的最短路徑算法,解決的是有權圖中最短路徑問題。迪杰斯特拉算法主要特點是從起始點開始,采用貪心算法的策略,每次遍歷到始點距離最近且未訪問過的頂點的鄰接節點,直到擴展到終點為止。
Dijkstra算法一般的表述通常有兩種方式,一種用永久和臨時標號方式,一種是用OPEN, CLOSE表的方式,這里均采用永久和臨時標號的方式。注意該算法要求圖中不存在負權邊。
Dijkstra算法可以解決如下問題:
在有向圖 G=(V,E) 中,假設每條邊 E[i] 的長度為 w[i],找到由頂點 V0 到其余各點的最短值。
8. 字符串搜索算法
字符串搜索算法是一種搜索算法,目的為在一長字符串中找出其是否包含某字符串。
字符串搜索算法工作的原理如下:
遍歷目標字符串,使用指定的字符逐個比較,如果發現有相同的,返回這個元素的索引并結束遍歷;如果從頭比較到結束都沒有相同的,返回-1。
例如問題:在abcdefg中查找cd:
第一步:ab與cd比較;
第二步:bc與cd比較;
第三步:cd與cd比較
上面的操作會返回cd中c字符的索引。
字符串比較算法比較簡單,效率也比較低,但是這種思想適合很多搜索場景。

三. 結語
上面索爾給大家介紹了一些基礎的常用算法,其實算法也是一門獨立的學科,通常和數據結構一起學習,合適的算法在特定場景下能夠幫助我們更好更快的完成工作。
如果大家對Java算法感興趣可以聯系千鋒索爾老師,我們一起來體味算法中的奧妙。















 京公網安備 11010802030320號
京公網安備 11010802030320號