


多表查詢是指在關系型數據庫中,通過同時查詢多個數據表來檢索相關數據的操作。這種查詢方式通常用于需要在多個數據表中搜索和比較數據的情況,以獲取更完整和準確的結果。
在多表查詢中,使用聯接(join)操作將多個表連接在一起,并使用條件語句來指定要檢索的數據。聯接操作可以使用不同的方式進行,包括內部聯接、外部聯接、左聯接、右聯接等,這些方式可以根據查詢需求選擇不同的聯接方式。
多表查詢可以提高查詢效率,避免重復的數據輸入,并且可以根據需要獲取更詳細的查詢結果。不過,在進行多表查詢時,需要注意數據庫表之間的關系、數據類型和查詢條件等因素,以確保查詢結果的準確性和完整性。
舉個例子,如果我們需要查詢一篇文章的作者姓名和發表時間,那么這個信息通常會被保存在不同的兩個表中,一張表存儲文章的信息,包括文章標題、內容等;另一張表存儲作者的信息,包括姓名、ID等。在這種情況下,如果只查詢文章表,我們只能獲取文章的基本信息,無法獲得作者的信息;但如果使用多表查詢,我們就可以將兩個表聯接起來,獲取文章的作者信息,從而得到更全面和詳細的查詢結果。
多表查詢基本寫法
TIPS:
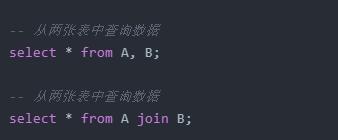
其實,連接兩張表進行查詢,標準SQL采用的是join的語法。上述的select * from A, B;的寫法,其實只是在MySQL中的“方言”,只在MySQL中生效,在其他的DBMS中就不一定能使用了。
select * from A, B; 其實是等價于 select * from A inner join B; 的。那么什么是inner join呢?后面會講。
笛卡爾積
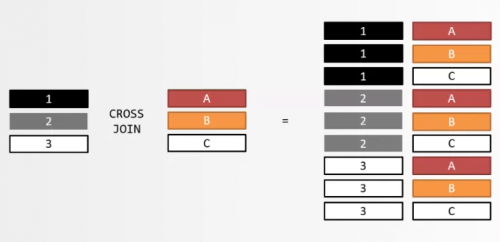
在做連接查詢的時候,一張表中的每一行數據都會和另一張表中的每一行數據進行關聯,形成笛卡爾積。
假如A表中有m行數據,B表中有n行數據,連接查詢之后的結果就是m*n行數據,其中有太多的數據是我們不需要的了。
連接查詢條件限制
通過上圖,我們知道了在兩張表進行連接查詢的時候,會出現大量的無效的數據。因此,我們就需要通過一些操作,去除連接查詢之后的無用的數據,只得到我們需要的數據!而這個過程是可以通過條件的限制來實現的:
1.MySQL的查詢方言

2.標準SQL的語法

連接查詢分類
將兩張表連接在一起查詢的時候,通常情況下我們需要進行一定的條件限制,來達到去除查詢結果笛卡爾積中多余的數據,保留我們需要的數據的目的。通常情況下,進行連接查詢的多張表之間是有一定的邏輯關聯的,具體表現為有一個相同的字段,在兩張表中都會出現。因此,我們在進行連接查詢的時候就會使用這個字段的值進行數據的過濾。
那么,連接查詢就會出現這樣的幾種情況:
A表中,通過關聯的字段,可以在B表中查詢到數據。
A表中,通過關聯的字段,無法在B表中查詢到數據。
B表中,通過關聯的字段,無法的A表中查詢到數據。
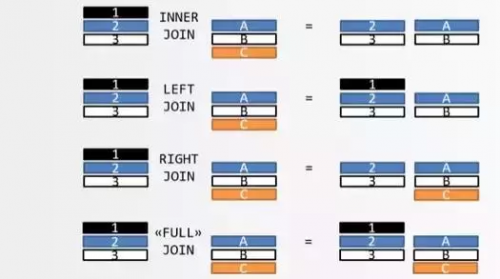
此時,根據所需的不同結果,可以將連接查詢分為兩類: 內連接、外連接
內連接
內連接,使用inner join來表示,在進行查詢的時候,inner是可以省略的,因此通常情況下直接寫join就是內連接。
所謂內連接,以左表為驅動表,右表為從動表。查詢結果中保留A表的數據通過連接的字段,在B表中能夠查詢到的數據。
-- 查詢員工的編號、職位、入職時間、部門編號、部門名稱select empno, job, hiredate, deptno, dname from emp join dept on emp.deptno = dept.deptno;-- 查詢LOCATION在NEW YORK的員工數量select count(*) from emp join dept on emp.deptno = dept.deptno where loc = 'NEW YORK';
外連接
外連接,使用outer join來表示,但是外連接還有更加明細的分類: 左外連接和右外連接。
左外連接: 以左表為驅動表,右表為從動表,查詢結果中保留A表的數據通過連接的字段,在B表中能夠查詢到的數據。如果通過這個連接字段無法在B表中查詢到數據,則B表與之關聯的就是null數據。
右外連接: 以右表為驅動表,左表為從動表,查詢結果中保留B表的數據通過連接的字段,在A表中能夠查詢到的數據。如果通過這個連接字段無法在A表中查詢到數據,則A表與之關聯的就是null數據。
總結來說
左外連接查詢結果: 包含左表中的所有數據,右表與之關聯的數據,如果在右表沒有與之關聯的數據,則用null填充。
右外連接查詢結果: 包含右表中的所有數據,左表與之關聯的數據,如果在左表沒有與之關聯的數據,則用null填充。
語法: 左外連接使用 left outer join來表示,右外連接使用 right outer join來表示。
而outer是可以省略不寫的,也就是: 左外連接: left join,右外連接: right join
-- 查詢所有的部門的人數select deptno, dname, count(empno) from dept left join emp on dept.deptno = emp.deptno;
全連接
全連接,又叫全外連接。全連接的意義是保留兩張表中的所有的數據。如果在另外一張表中沒有與之連接的數據,使用null進行填充。也就是說,其實全連接就是將左外連接和右外連接的查詢結果合并到一起并去除重復的數據。
MySQL不支持全連接!
雖然MySQL不支持全連接,但是可以使用其他的方式來間接實現;
將左外連接和右外連接的查詢結果,使用union合并到一起即可。
自然連接
我們在進行連接查詢的時候,通常會在需要連接的兩張表中找到字段關聯在一起,而絕大多數情況下我們所需要進行的是等值連接。在進行數據庫和表的設計的時候,這樣用來聯系多張表之間的關系的字段,一般情況下命名是相同的。
所謂“自然連接“指的就是找到需要進行連接查詢的兩張表中名字相同、類型也相同的字段,自動的使用這個字段作為連接的字段。如果不存在這樣的名字相同的字段,會有錯誤。

子查詢
子查詢簡介
有的時候,當一個查詢語句A所需要的數據,不是直觀在表中體現,而是由另外一個查詢語句B查詢出來的結果,那么查詢語句A就是主查詢語句,查詢語句B就是子查詢語句。這種查詢我們稱之為高級關聯查詢,也叫做子查詢。
子查詢語句的返回數據形式:

子查詢語句的位置可以在以下幾個子句中:

在where子句中
# 需求:查詢工資大于員工編號為7369這個員工的所有員工信息。# 解析:# 第一步:目的是查詢工資大于某一個數num的所有員工信息# select * from emp where sal>num# 第二步:num的值7369員工的工資# select sal from emp where empno = 7369;# 第三步:將主查詢中的代詞使用子查詢語句替換select * from emp where sal>(select sal from emp where empno = 7369);# 需求:查詢工資大于10號部門的平均工資的所有員工信息select * from emp where sal>(select avg(ifnull(sal,0)) from emp where deptno=10);# 需求:查詢工資大于10號部門的平均工資的非10號部門的員工信息。select * from emp where sal>(select avg(ifnull(sal,0)) from emp where deptno=10) and deptno<>10;# 需求:查詢與7369同部門的同事信息。select * from emp where deptno=(select deptno from emp where empno=7369) and empno<>7369;
在from子句中
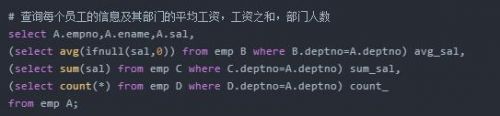
# 需求:查詢員工的姓名,工資,及其部門的平均工資。# 解析:# 第一步:先查詢每個部門的平均工資# select deptno,avg(ifnull(sal,0)) from emp group by deptno;# 第二步:將上一個查詢語句的返回結果當成一張表,與員工表進行關聯查詢select A.ename, A.sal, B.avg_salfrom emp A join (select deptno,avg(ifnull(sal,0)) avg_sal from emp group by deptno) B on A.deptno = B.deptno
在having子句中
# 需求:查詢平均工資大于30號部門的平均工資的部門號,和平均工資select deptno,avg(ifnull(sal,0)) from emp group by deptno having avg(ifnull(sal,0))>(select avg(ifnull(sal,0)) from emp where deptno=30);
在select子句中
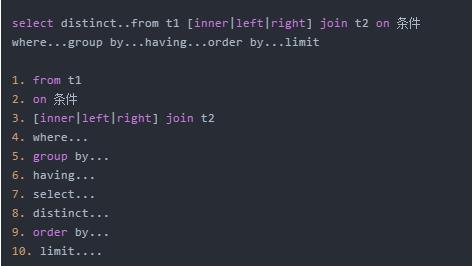
SQL完整的執行順序
合并查詢結果集
合并查詢結果集概述
合并結果集,就是將兩次或者多次的查詢結果,合并到一起,存入一張查詢結果虛擬表中。
進行結果集合并的多張表,要求字段的數量是完全相同的。
A查詢的結果有5個字段,B查詢的結果有5個字段。此時是可以合并到一起的。
A查詢的結果有5個字段,B查詢的結果有3個字段。此時是無法合并到一起的。
合并查詢結果集語法
union: 對兩次的查詢結果進行合并,對最終的合并結果會進行去重的處理。
union all : 對兩次的查詢結果的直接合并,沒有進行去重的處理。















 京公網安備 11010802030320號
京公網安備 11010802030320號