


001-OCR光學文字識別
一、OCR簡介
OCR(Optical Character Recognition,光學文字識別)是指電子設備檢查紙上打印的字符,通過檢測暗、亮的模式確定其形狀,然后用字符識別方法將形狀翻譯成計算機文字的過程;即針對印刷體字符,采用光學的方式將紙質文檔中的文字轉換成為黑白點陣的圖像文件,并通過識別軟件將圖像中的文字轉換成文本格式,供文字處理軟件進一步編輯加工的技術。
各種場景都有OCR的身影,我們可以在任何地方使用到OCR。Python中常見的OCR有EasyOCR、PaddleOCR等,接下來我們以EasyOCR為例,演示其如何使用。
二、EasyOCR使用
EasyOCR是一個免費開源的OCR模塊,其有自己的一系列的訓練好的模型,借助這些模型,我們就可以識別各種場景下的文字。
Github鏈接:https://github.com/JaidedAI/EasyOCR
EasyOCR官網:https://www.jaided.ai/easyocr/
首先我們先來安裝OCR:
Windows:pip install easyocr;Mac/Linux:pip3 install easyocr
安裝完成以后
我們直接寫代碼即可
1.導入easyocr模塊
import easyocr2.實例化Reader類
Reader類中有幾個參數我們需要手動修改
lang_list:告訴它我們要識別的語言,以列表的形式傳參,可以一次傳遞多種語言,但并非所有語言都可以一起使用,截止到2022年12月19日,已經支持80+種語言。這是目前支持的語言的鏈接:https://www.jaided.ai/easyocr/。我們這里寫的ch_sim是簡體中文,en是英文。
gpu:會讓你選擇使用cpu驅動還是gpu驅動,使用gpu驅動識別速度會更快一些,但是所要配置的環境也更復雜,如果有興趣,可以自行研究一下,這里我們就使用cpu,將gpu改為False。
download_enabled:easyocr第一次運行時會先在線下載模型數據,但是鑒于網絡不好,大部分人下載時都會發生錯誤,所以將download_enabled改為False,我們手動去下載模型數據。
model_storage_directory:這個參數是指定模型數據的引用路徑,默認情況下在Windows系統中存放在C:\Users\用戶名\.EasyOCR\model中,在Mac/Linux系統中存放在~/.EasyOCR/model中,我們可以通過修改model_storage_directory參數自行指定模型數據的路徑,我這里就直接指定相對路徑為./model。
注意:
除此之外還有很多其他參數,詳情請見源碼。
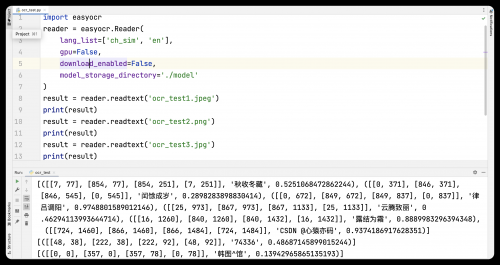
reader = easyocr.Reader(
lang_list=['ch_sim', 'en'],
gpu=False,
download_enabled=False,
model_storage_directory='./model'
)
1.調用readtext方法
實例化Reader類以后,調用readtext方法讀取圖片。
readtext方法中有一個參數叫做image,把圖片傳給它即可。image參數可以接收圖片路徑、圖片的numpy數組或者圖片的字節流對象。一般情況下我們直接傳遞圖片路徑即可,除非有要求要針對圖片做一些特殊處理。
result = reader.readtext(image='圖片')
print(result)三、模型下載
剛剛我們說將download_enabled參數改為False,要去手動下載模型數據,這是模型數據下載地址:https://www.jaided.ai/easyocr/modelhub/。
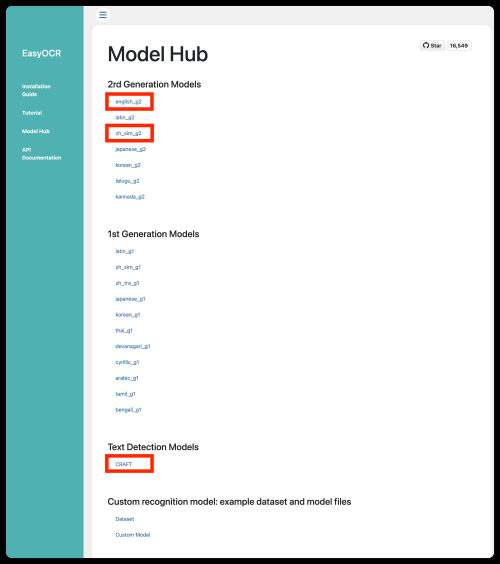
下載圖中框選中的三個即可,下載下來為zip壓縮包,一定要解壓縮,我們需要的是其中的后綴名為pth的文件,并將其移動到我們自己創建的**model**文件夾中。因為我們要做文字識別就一定要有CRAFT,我們識別的大部分為簡體中文和英文,所以下載zh_sim_g2和english_g2。當然,如果你要識別其他語言,請再次找其他語言的模型數據。
四、圖片
在此提供幾張圖片,供大家測試。

按照官方的說法,準確率在90%以上,但是碰到識別不出來或者識別錯誤的概率還是蠻大的。














 京公網安備 11010802030320號
京公網安備 11010802030320號