


在大數據開發過程中我們經常會使用到消息隊列類型的組件,比較常見的就是Kafka與ActiveMQ,但很多同學鬧不懂兩者的區別和聯系,今天小千就來帶大家分析一下。
一、背景分析
消息隊列這個類型的組件一直是非常重要的組件,當經過兩家企業后我就很堅信這個結論了。隊列這種東西,最廣泛的作用還是在于解耦,寬泛一點的說,它可以將不同部門的工作內容進行有效的整合,基于一個約定好的格式,就可以兩頭互相不干擾的進行開發。可以說這個生產消費的思想不僅僅適用于程序也適用于非常多的地方。
目前對于我看到的來說,Kafka更多的還是做為一個數據源,數據橋梁的作用,不同業務之間的溝通。比如需要實時接入A部門的業務數據的話,就會有這樣的手段:
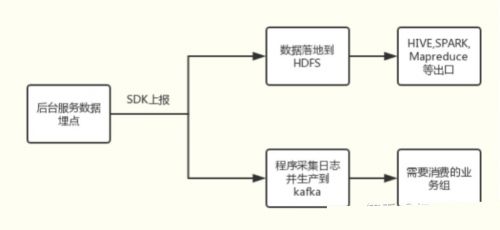
落地到HDFS的數據會用來進行一些算法上的離線處理,而Kafka端則是給需要實時性的消費方。其實數據的消費方式無非也就實時和離線兩種方式。
二、Kafka和ActiveMQ對比
相比過去經常使用的ActiveMQ,Kafka確實非常的不同,做一個對比來深化印象

說到底,做為kafka的消費方,能感受到最大的不同還是在于幾個:
1. 吞吐量確實非常高
2.可以重讀歷史數據
3.但是也有一些缺點:概念上比較復雜,相對于AMQ只需要知道ip和隊列名你就能獲得數據,Kafka使用起來非常繁瑣
三、Kafka的基本概念(摘錄)
1.Broker:消息中間件處理結點,一個Kafka節點就是一個broker,多個broker可以組成一個Kafka集群。
2.Topic:一類消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能夠同時負責多個topic的分發。
3.Partition:topic物理上的分組,一個topic可以分為多個partition,每個partition是一個有序的隊列。
4.Segment:partition物理上由多個segment組成。
5.offset:每個partition都由一系列有序的、不可變的消息組成,這些消息被連續的追加到partition中。partition中的每個消息都有一個連續的序列號叫做offset,用于partition唯一標識一條消息.
四、Kafka消費端的常用參數

看過上面的介紹之后,相信大家對Kafka與ActiveMQ都有一定的了解了吧,最后歡迎對大數據開發感興趣的同學來到千鋒大數據培訓班了解一下我們的大數據開發培訓課程,現在還有免費學習教程視頻可以領取,先到先得。















 京公網安備 11010802030320號
京公網安備 11010802030320號