


生活中我們可能會遇到需要從圖片上獲取文本內容的情況,人工去核對的話非常頭疼,今天小千就來教大家使用Python一行代碼就能實現文本識別,下面來看看吧。

Python圖片文本識別
這里我們需要用到兩個庫:pytesseract和PIL,同時我們還需要安裝識別引擎tesseract-ocr
安裝這兩個包可以借助pip
pip install PIL
pip install pytesseract
然后我們還需要安裝識別引擎tesseract-ocr和中文語言包,默認是不支持中文識別的,所以需要同學們額外安裝一個中文語言包,網絡上下載安裝即可。
安裝完成tesseract-ocr后,我們還需要做一下配置關聯到Python中:
在你安裝Python的文件夾中C:\Users\huxiu\AppData\Local\Programs\Python\Python35\Lib\site-packages\pytesseract找到pytesseract.py文件,打開之后在里面添加下面的操作。
CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
#tesseract_cmd = 'tesseract'
tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
可以看到里面有一個路徑就是你安裝Tesseract-OCR的路徑,注意不要填錯了。
配置完成之后就可以使用它們了,代碼如下,其中denggao.jpeg為圖片,同學們替換成自己想要的圖片即可。
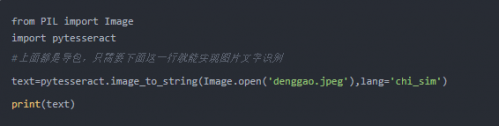
好了同學們趕緊去自己試試吧,最后歡迎大家來到千鋒了解一下我們的Python培訓課程,涵蓋了Python爬蟲、Python web、Python人工智能等領域,歡迎同學們前來試聽學習。















 京公網安備 11010802030320號
京公網安備 11010802030320號