


Scrapy框架與Selenium我們前面都介紹過,本次給大家分享的是兩者如何配合使用。
本次我們獲取千瓜的數(shù)據(jù):http://www.qian-gua.com/rank/category/
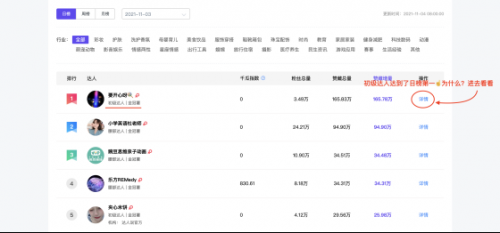
不好意思!接下來這個頁面你會很郁悶!
我們想獲取更多的日榜達(dá)人的數(shù)據(jù)怎么操作?借助selenium哦!為了獲取更多我們結(jié)合Scrapy完成此次的爬蟲任務(wù)。
任務(wù)要求:
Python3環(huán)境
Scrapy框架
Selenium 可以參照https://selenium-python-zh.readthedocs.io/en/latest/
谷歌瀏覽器+ChromeDriver
ChromeDriver的下載地址:https://chromedriver.storage.googleapis.com/index.html
首先我們創(chuàng)建項目:scrapy startproject qiangua_spider
然后進(jìn)入qiangua_spider目錄下,執(zhí)行:scrapy genspider qiangua qian-gua.com
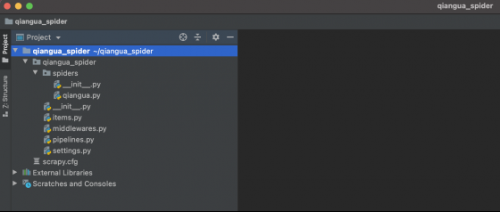
在Pycharm中打開創(chuàng)建的項目,目錄結(jié)構(gòu)如下:
修改settings.py文件ROBOTSTXT_OBEY 為 False
編寫items.py文件內(nèi)容如下:
代碼如下:
import scrapy
class QianguaSpiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
level = scrapy.Field()
fans = scrapy.Field()
likeCollect = scrapy.Field()
編寫spider.py爬蟲文件,如果不登陸我們是無法看的更多的小紅書達(dá)人們的賬號排行、漲粉等信息。如果想看的更多則需要登陸才可以。
流程與思路:
先進(jìn)入http://www.qian-gua.com/rank/category/
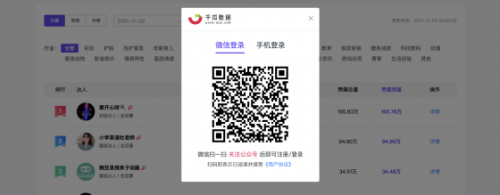
點擊右上角的登陸(此過程需要有千瓜的賬號才可以)
有兩種登陸方式,我們可以選擇微信掃碼登陸,或者手機(jī)登陸(本案例采用手機(jī)登陸)
獲取登陸的Cookies
保存Cookies并訪問
http://api.qian-gua.com/Rank/GetBloggerRank?pageSize=50&pageIndex=頁碼數(shù)&dateCode=20211104&period=1&originRankType=2&rankType=2&tagId=0&_=時間戳
得到j(luò)son數(shù)據(jù)并解析數(shù)據(jù)
在上述的流程中1-4,我們都是結(jié)合selenium完成的。
代碼如下
import json
import time
import scrapy
from selenium import webdriver
from qiangua_spider.items import QianguaSpiderItem
class QianguaSpider(scrapy.Spider):
name = 'qiangua'
allowed_domains = ['www.qian-gua.com']
# start_urls = ['http://www.qian-gua.com/rank/category/']
headers = {
'Origin': 'http://app.qian-gua.com',
'Host': 'api.qian-gua.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Safari/605.1.15'
}
def start_requests(self):
driver = webdriver.Chrome()
url = 'http://www.qian-gua.com/rank/category/'
driver.get(url)
driver.implicitly_wait(5)
driver.find_element_by_xpath('//div[@class="loggin"]/a').click()
time.sleep(2)
driver.find_element_by_xpath('//div[@class="login-tab"]/span[2]').click()
driver.find_element_by_xpath('//input[@class="js-tel"]').send_keys('15010185644')
driver.find_element_by_xpath('//input[@class="js-pwd"]').send_keys('qiqining123')
driver.find_element_by_xpath('//button[@class="btn-primary js-login-tel-pwd"]').click()
time.sleep(2)
cookies = driver.get_cookies()
driver.close()
jsonCookies = json.dumps(cookies) # 通過json將cookies寫入文件
with open('qianguaCookies.json', 'w') as f:
f.write(jsonCookies)
print(cookies)
with open('qianguaCookies.json', 'r', encoding='utf-8') as f:
listcookies = json.loads(f.read()) # 獲取cookies
cookies_dict = dict()
for cookie in listcookies:
# 在保存成dict時,我們其實只要cookies中的name和value,而domain等其他都可以不要
cookies_dict[cookie['name']] = cookie['value']
# 更多的數(shù)據(jù)需要開通會員才可以,我們當(dāng)前獲取了top30的數(shù)據(jù)
for page in range(1, 2):
t = time.time()
timestamp = str(t).replace(".", '')[:13]
data_url = "http://api.qian-gua.com/Rank/GetBloggerRank?pageSize=50&pageIndex=" + str(
page) + "&dateCode=20211104&period=1&originRankType=2&rankType=2&tagId=0&_=" + timestamp
yield scrapy.Request(url=data_url, cookies=cookies_dict, callback=self.parse, headers=self.headers)
def parse(self, response):
rs = json.loads(response.text)
if rs.get('Msg')=='ok':
blogger_list = rs.get('Data').get("ItemList")
for blogger in blogger_list:
name = blogger.get('BloggerName')
level = blogger.get('LevelName','無')
fans = blogger.get('Fans')
likeCollect = blogger.get('LikeCollectCount')
item = QianguaSpiderItem()
item['name'] = name
item['level'] = level
item['fans'] = fans
item['likeCollect'] = likeCollect
yield item
最后我們添加pipelines.py保存解析的數(shù)據(jù),我們是將數(shù)據(jù)保存到csv文件中
代碼如下:
import csv
from itemadapter import ItemAdapter
class QianguaSpiderPipeline:
def __init__(self):
self.stream = open('blogger.csv', 'w', newline='', encoding='utf-8')
self.f = csv.writer(self.stream)
def open_spider(self, spider):
print("爬蟲開始...")
def process_item(self, item, spider):
data = [item.get('name'), item.get('level'), item.get('fans'), item.get('likeCollect')]
self.f.writerow(data)
def close_spider(self, spider):
self.stream.close()
print('爬蟲結(jié)束!')
務(wù)必記得將settings.py中pipelines部分的代碼注釋取消掉
ITEM_PIPELINES = {
'qiangua_spider.pipelines.QianguaSpiderPipeline': 300,
}
執(zhí)行爬蟲
scrapy crawl qiangua
結(jié)果很令我們滿意
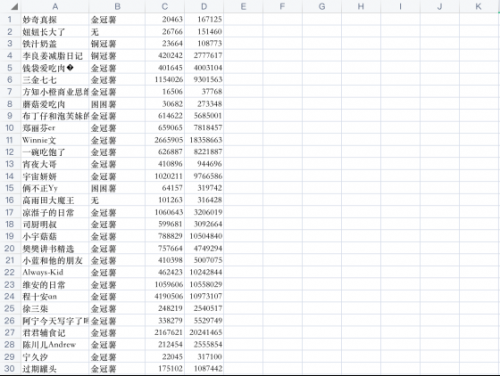
更多關(guān)于python培訓(xùn)的問題,歡迎咨詢千鋒教育在線名師。千鋒教育擁有多年IT培訓(xùn)服務(wù)經(jīng)驗,采用全程面授高品質(zhì)、高體驗培養(yǎng)模式,擁有國內(nèi)一體化教學(xué)管理及學(xué)員服務(wù),助力更多學(xué)員實現(xiàn)高薪夢想。















 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號