


一、selenium簡介
由于requests模塊是一個不完全模擬瀏覽器行為的模塊,只能爬取到網頁的HTML文檔信息,無法解析和執行CSS、JavaScript代碼,因此需要我們做人為判斷;
1、什么是selenium
selenium最初是一個自動化測試工具,而爬蟲中使用它主要是為了解決requests無法執行javaScript代碼的問題。
selenium模塊本質是通過驅動瀏覽器,完全模擬瀏覽器的操作,比如跳轉、輸入、點擊、下拉等,來拿到網頁渲染之后的結果,可支持多種瀏覽器;由于selenium解析執行了CSS、JavaScript所以相對requests它的性能是低下的;
2、selenium的用途
(1)、selenium可以驅動瀏覽器自動執行自定義好的邏輯代碼,也就是可以通過代碼完全模擬成人類使用瀏覽器自動訪問目標站點并操作,那我們也可以拿它來做爬蟲。
(2)、selenium本質上是通過驅動瀏覽器,完全模擬瀏覽器的操作,比如跳轉、輸入、點擊、下拉等...進而拿到網頁渲染之后的結果,可支持多種瀏覽器
二、selenium的安裝與測試
1、下載selenium模塊:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
或者在pycharm中下載
2、安裝瀏覽器驅動
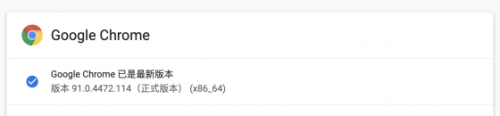
(1) Google瀏覽器驅動(在下載驅動之前,查看一下chrome瀏覽器的版本號,如下:)
國內鏡像網站地址:http://npm.taobao.org/mirrors/chromedrive
當然也可以去官網找最新的版本,官網: https://sites.google.com/a/chromium.org/chromedriver/downloads
另外注意:把下載好的chromedriver.exe放到python安裝路徑的scripts目錄中即可
(2) firefox瀏覽器驅動:
selenium3默認支持的webdriver是Firfox,而Firefox需要安裝geckodriver
下載鏈接:https://github.com/mozilla/geckodriver/releases
(3) 測試是否安裝成功
from selenium import webdriver
browser=webdriver.Chrome()
#實例化1個谷歌瀏覽器對象
browser.get('https://www.baidu.com/')
time.sleep(5)
browser.close()
三、selenium的使用
所謂模擬瀏覽器基本就是下面的流程:
請求
顯示頁面
查找元素
點擊可點擊元素
所以如何使用selenium找到頁面中的標簽,進而觸發標簽事件,就會變的尤為重要。
○ selenium選擇器
要想定位頁面的元素,selenium也提供了一系列的方法。
1.通過標簽id屬性進行定位
browser.find_element_by_id('kw') # 其中kw便是頁面中某個元素的id值
2.通過標簽name屬性進行定位
# 兩種方式是一樣的
browser.find_element_by_name("wd") # 其中wd是頁面中某個元素的name值
3.通過標簽名進行定位
browser.find_element_by_tag_name("img") # img參數表示的就是圖片標簽img
4.通過CSS查找方式進行定位
browser.find_elements_by_css_selector("#kw") # 根據選擇器進行定位查找,其中#kw表示的是id選擇器名稱是kw的
5.通過xpath方式定位
browser.find_element_by_xpath('//*[@id="kw"]') # 參數即是xpath的語法
6.通過搜索 頁面中 鏈接進行定位
有時候不是一個輸入框也不是一個按鈕,而是一個文字鏈接,我們可以通過link
browser.find_element_by_link_text("設置")
通過搜索 頁面中 鏈接進行定位 ,可以支持模糊匹配**
browser.find_element_by_partial_link_text("百度") # 查找頁面所有的含有百度的文字鏈接
○ selenium顯示等待和隱式等待
顯示等待:就是明確要等到某個元素的出現或者是某個元素的可點擊等條件,等不到,就一直等,除非在規定的時間之內都沒找到,就會跳出異常Exception
操作格式:WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
WebDriverWait()一般由until()或 untilnot()方法配合使用
until(method, message=' '):調用該方法提供的驅動程序作為一個參數,直到返回值為True
`untilnot(method, message=' ')`:調用該方法提供的驅動程序作為一個參數,直到返回值為False
返回值為False
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.chrome()
driver.get('http://www.baidu.com')
element = WebDriverWait(driver, 5, 0.5).until(EC.presence_of_element_located((By.ID, "kw")))
element.send_keys('selenium')
隱式等待:就是在創建driver時,為瀏覽器對象創建一個等待時間,這個方法是得不到某個元素就等待一段時間,直到拿到某個元素位置。
注意:在使用隱式等待的時候,實際上瀏覽器會在你自己設定的時間內部斷的刷新頁面去尋找我們需要的元素
driver.implicitly_wait() 默認設置為0
例如: driver.implicitly_wait(10) 。如果元素在10s內定位到了,繼續執行。如果定位不到,將以循環方式判斷元素是否被定位到。如果在10s內沒有定位到,則拋出異常
from selenium import webdriver
driver = webdriver.chrome()
driver.get('http://www.baidu.com')
# 隱式等待10秒
driver.implicitly_wait(10)
另外還有一種就是我們常用的sleep,我們稱為:強制等待。
有時候我們希望腳本在執行到某一位置時暫停一段時間等待頁面加載,這時可以使用sleep()方法。sleep()方法會固定休眠一定的時長,然后再繼續執行。sleep()方法默認參數以秒為單位。
from time import sleep
from selenium import webdriver
driver = webdriver.chrome()
driver.get('http://www.baidu.com')
# 強制休眠2秒
sleep(2)
driver.find_element_by_id("kw").send_keys("selenium")
○ 元素交互操作
用selenium做自動化,有時候會遇到需要模擬鼠標操作才能進行的情況,比如單擊、雙擊、點擊鼠標右鍵、拖拽(滑動驗證)等等。而selenium給我們提供了一個類來處理這類事件——ActionChains;
selenium.webdriver.common.action_chains.ActionChains(driver)
這個類基本能夠滿足我們所有對鼠標操作的需求。
actionChains的基本使用:
首先需要了解ActionChains的執行原理,當你調用ActionChains的方法時,不會立即執行,而是會將所有的操作按順序存放在一個隊列里,當你調用perform()方法時,隊列中的時間會依次執行。
這種情況下我們可以有兩種調用方法:
鏈式寫法
menu = driver.find_element_by_css_selector(".div1")
hidden_submenu = driver.find_element_by_css_selector(".div1 #menu1")
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
分步寫法
menu = driver.find_element_by_css_selector(".div1")
hidden_submenu = driver.find_element_by_css_selector(".div1 #menu1")
actions = ActionChains(driver)
actions.move_to_element(menu)
actions.click(hidden_submenu)
actions.perform()
兩種寫法本質是一樣的,ActionChains都會按照順序執行所有的操作。
actionChains方法列表:
click(on_element=None) ——單擊鼠標左鍵
click_and_hold(on_element=None) ——點擊鼠標左鍵,不松開
context_click(on_element=None) ——點擊鼠標右鍵
double_click(on_element=None) ——雙擊鼠標左鍵
drag_and_drop(source, target) ——拖拽到某個元素然后松開
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某個坐標然后松開
key_down(value, element=None) ——按下某個鍵盤上的鍵
key_up(value, element=None) ——松開某個鍵
move_by_offset(xoffset, yoffset) ——鼠標從當前位置移動到某個坐標
move_to_element(to_element) ——鼠標移動到某個元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移動到距某個元素(左上角坐標)多少距離的位置
perform() ——執行鏈中的所有動作
release(on_element=None) ——在某個元素位置松開鼠標左鍵
send_keys(*keys_to_send) ——發送某個鍵到當前焦點的元素
send_keys_to_element(element, *keys_to_send) ——發送某個鍵到指定元素
示例代碼:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
try:
driver = webdriver.Chrome()
driver.implicitly_wait(10)
# 1、往jd發送請求
driver.get('https://www.jd.com/')
# 找到輸入框輸入圍城
input_tag = driver.find_element_by_id('key')
input_tag.send_keys('華為')
# 鍵盤回車
input_tag.send_keys(Keys.ENTER)
time.sleep(2)
# 找到輸入框輸入墨菲定
input_tag = driver.find_element_by_id('key')
input_tag.clear()
input_tag.send_keys('樊登讀書')
# 找到搜索按鈕點擊搜索
button = driver.find_element_by_class_name('button')
button.click()
time.sleep(10)
finally:
driver.close()
或者前進后退相關
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.cnblogs.com/xuanyuan/')
browser.find_element_by_partial_link_text('我是如何把計算機網絡考了100分的?').click()
time.sleep(3)
browser.back() # 后退
time.sleep(3)
browser.forward() # 前進
time.sleep(5)
browser.close()
四、綜合案例
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC # available since 2.26.0
from selenium.webdriver.support.ui import WebDriverWait # available since 2.4.0
from selenium.webdriver.support import expected_conditions
import pandas as pd
class MyCrawler(object):
def __init__(self):
self.path = "./data"
if not os.path.exists(self.path):
os.mkdir(self.path)
self.driver = webdriver.Chrome()
self.base_url = "http://data.house.163.com/bj/housing/trend/district/todayprice/{date:s}/{interval:s}/allDistrict/1.html?districtname={disname:s}#stoppoint"
self.data = None
def craw_page(self, date="2020.01.01-2020.12.30", interval="month", disname="全市"):
driver = self.driver
url = self.base_url.format(date=date, interval=interval, disname=disname)
driver.get(url)
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "resultdiv_1")))
self.data = pd.DataFrame()
ct = True
while ct:
self.get_items_in_page(driver)
e_pages = driver.find_elements_by_xpath(
'//div[@class="pager_box"]/a[@class="pager_b current"]/following::a[@class="pager_b "]')
if len(e_pages) > 0:
next_page_num = e_pages[0].text
e_pages[0].click()
# 通過判斷當前頁是否為我們點擊頁面的方式來等待頁面加載完成
WebDriverWait(driver, 10).until(
expected_conditions.text_to_be_present_in_element(
(By.XPATH, '//a[@class="pager_b current"]'),
next_page_num
)
)
else:
ct = False
brea
return self.data
finally:
driver.quit()
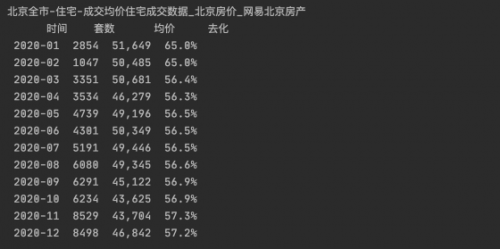
def get_items_in_page(self, driver):
e_tr = driver.find_elements_by_xpath("http://tr[normalize-space(@class)='mBg1' or normalize-space(@class)='mBg2']")
temp = pd.DataFrame(e_tr, columns=['web'])
temp['時間'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd2').text.split(' ')[0])
temp['套數'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd5').text)
temp['均價'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd7').text)
temp['去化'] = temp.web.apply(lambda x: x.find_element_by_class_name('wd14').text)
del temp['web']
self.data = pd.concat([temp, self.data], axis=0)
mcraw = MyCrawler()
data = mcraw.craw_page()
data= data.sort_values(by='時間')
print(data.to_string(index=False))
更多關于python培訓的問題,歡迎咨詢千鋒教育在線名師。千鋒教育擁有多年IT培訓服務經驗,采用全程面授高品質、高體驗培養模式,擁有國內一體化教學管理及學員服務,助力更多學員實現高薪夢想。















 京公網安備 11010802030320號
京公網安備 11010802030320號