


1.Flink的重啟策略
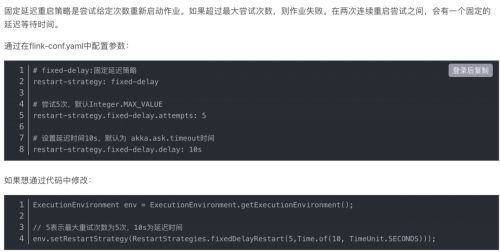
答案:固定延遲重啟策略(默認)
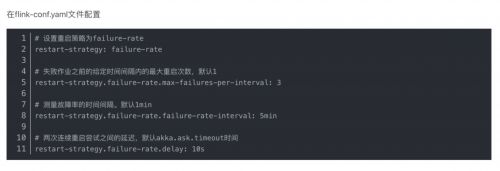
失敗率重啟策略
在一定時間內重啟一定次數,超過這個次數則重啟失敗。
**代碼設置:**
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 3為最大失敗次數;5min為測量的故障時間;10s為2次間的延遲時間
env.setRestartStrategy(RestartStrategies.failureRateRestart(3,Time.of(5, TimeUnit.MINUTES),Time.of(10, TimeUnit.SECONDS)));
無重啟策略
無重啟,作業直接失敗
2.checkpoint過程(Chandy-Lamport,分布式快照)
答案:
1)JobManager端的 CheckPointCoordinator向 所有SourceTask發送CheckPointTrigger,Source Task會在數據流中安插CheckPoint barrier
2)當task收到所有的barrier后,向自己的下游繼續傳遞barrier,然后自身執行快照,并將自己的狀態異步寫入到持久化存儲中。增量CheckPoint只是把最新的一部分更新寫入到 外部存儲;為了下游盡快做CheckPoint,所以會先發送barrier到下游,自身再同步進行快照
3)當task完成備份后,會將備份數據的地址(state handle)通知給JobManager的CheckPointCoordinator;如果CheckPoint的持續時長超過 了CheckPoint設定的超時時間,CheckPointCoordinator 還沒有收集完所有的 State Handle,CheckPointCoordinator就會認為本次CheckPoint失敗,會把這次CheckPoint產生的所有 狀態數據全部刪除。
4)最后 CheckPoint Coordinator 會把整個 StateHandle 封裝成 completed CheckPoint Meta,寫入到hdfs。
3.什么是barrier對齊?
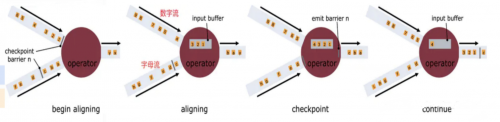
答案:一旦Operator從輸入流接收到CheckPoint barrier n,它就不能處理來自該流的任何數據記錄,直到它從其他所有輸入接收到barrier n為止。否則,它會混合屬于快照n的記錄和屬于快照n + 1的記錄;
接收到barriern的流暫時被擱置。從這些流接收的記錄不會被處理,而是放入輸入緩沖區。
雖然數字流對應的barrier已經到達了,但是barrier之后的1、2、3這些數據只能放到buffer中,等待字母流的barrier到達;
一旦最后所有輸入流都接收到barrier n,CheckPoint barrier n接著往下游發送,Operator就會把緩沖區中pending 的輸出數據發出去
這里還會對自身進行快照;之后,Operator將繼續處理來自所有輸入流的記錄,在處理來自流的記錄之前先處理來自輸入緩沖區的記錄。
更多關于“大數據培訓”的問題,歡迎咨詢千鋒教育在線名師。千鋒教育多年辦學,課程大綱緊跟企業需求,更科學更嚴謹,每年培養泛IT人才近2萬人。不論你是零基礎還是想提升,都可以找到適合的班型,千鋒教育隨時歡迎你來試聽。















 京公網安備 11010802030320號
京公網安備 11010802030320號