


小千今天分享的這篇spark筆試題是sparkSQL的優(yōu)化器catalyst,本質(zhì)上它就是一個(gè)SQL查詢的優(yōu)化器,大家了解了它之后基本就能了解其他的SQL處理引擎的優(yōu)化原理了。
*SQL優(yōu)化器核心執(zhí)行策略主要分為兩個(gè)大的方向:基于規(guī)則優(yōu)化(RBO)以及基于代價(jià)優(yōu)化(CBO),基于規(guī)則優(yōu)化是一種經(jīng)驗(yàn)式、啟發(fā)式地優(yōu)化思路,更多地依靠前輩總結(jié)出來的優(yōu)化規(guī)則,簡單易行且能夠覆蓋到大部分優(yōu)化邏輯,但是對于核心優(yōu)化算子Join卻顯得有點(diǎn)力不從心。舉個(gè)簡單的例子,兩個(gè)表執(zhí)行Join到底應(yīng)該使用BroadcastHashJoin 還是SortMergeJoin?當(dāng)前SparkSQL的方式是通過手工設(shè)定參數(shù)來確定,如果一個(gè)表的數(shù)據(jù)量小于這個(gè)值就使用BroadcastHashJoin,但是這種方案顯得很不優(yōu)雅,很不靈活。基于代價(jià)優(yōu)化就是為了解決這類問題,它會(huì)針對每個(gè)Join評估當(dāng)前兩張表使用每種Join策略的代價(jià),根據(jù)代價(jià)估算確定一種代價(jià)最小的方案。
*我們這里主要說明基于規(guī)則的優(yōu)化,略提一下CBO
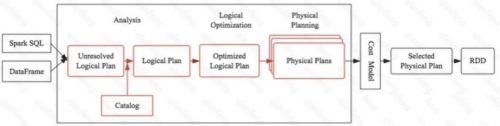
如上圖是一個(gè)SQL經(jīng)過優(yōu)化器的最終生成物理查詢計(jì)劃的留存,紅色部分是我們要重點(diǎn)說明的內(nèi)容。大 家思考我們寫的一個(gè)SQL最終如何在Spark引擎中轉(zhuǎn)換成具體的代碼執(zhí)行的。任何一個(gè)優(yōu)化器工作原理都大同小異:SQL語句首先通過Parser模塊被解析為語法樹,此棵樹稱為Unresolved Logical Plan; Unresolved Logical Plan通過Analyzer模塊借助于數(shù)據(jù)元數(shù)據(jù)解析為Logical Plan;此時(shí)再通過各種基于規(guī)則的優(yōu)化策略進(jìn)行深入優(yōu)化,得到Optimized Logical Plan;優(yōu)化后的邏輯執(zhí)行計(jì)劃依然是邏輯的,并不能被Spark系統(tǒng)理解,此時(shí)需要將此邏輯執(zhí)行計(jì)劃轉(zhuǎn)換為Physical Plan;為了更好的對整個(gè)過程進(jìn)行理解,下文通過一個(gè)簡單示例進(jìn)行解釋。
Parser
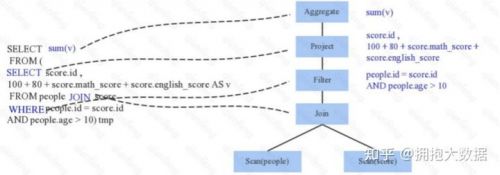
Parser簡單來說是將SQL字符串切分成一個(gè)一個(gè)Token,再根據(jù)一定語義規(guī)則解析為一棵語法樹。Parser模塊目前基本都使用第三方類庫 ANTLR 進(jìn)行實(shí)現(xiàn),比如Hive、 Presto、SparkSQL等。下圖是一個(gè)示例性的SQL語句(有兩張表,其中people表主要存儲(chǔ)用戶基本信息,score表存儲(chǔ)用戶 的各種成績),通過Parser解析后的AST語法樹如下圖所示:
Analyzer
通過解析后的邏輯執(zhí)行計(jì)劃基本有了?架,但是系統(tǒng)并不知道score、sum這些都是些什么?,此 時(shí)需要基本的元數(shù)據(jù)信息來表達(dá)這些詞素,最重要的元數(shù)據(jù)信息主要包括兩部分:表的Scheme和 基本函數(shù)信息,表的scheme主要包括表的基本定義(列名、數(shù)據(jù)類型)、表的數(shù)據(jù)格式(Json、Text)、表的物理位置等,基本函數(shù)信息主要指類信息。
Analyzer會(huì)再次遍歷整個(gè)語法樹,對樹上的每個(gè)節(jié)點(diǎn)進(jìn)行數(shù)據(jù)類型綁定以及函數(shù)綁定,比如people 詞素會(huì)根據(jù)元數(shù)據(jù)表信息解析為包含age、id以及name三列的表,people.age會(huì)被解析為數(shù)據(jù)類型 為int的變量,sum會(huì)被解析為特定的聚合函數(shù),如下圖所示:

Optimizer
優(yōu)化器是整個(gè)Catalyst的核心,上文提到優(yōu)化器分為基于規(guī)則優(yōu)化和基于代價(jià)優(yōu)化兩種,此處只介 紹基于規(guī)則的優(yōu)化策略,基于規(guī)則的優(yōu)化策略實(shí)際上就是對語法樹進(jìn)行一次遍歷,模式匹配能夠滿 足特定規(guī)則的節(jié)點(diǎn),再進(jìn)行相應(yīng)的等價(jià)轉(zhuǎn)換。因此,基于規(guī)則優(yōu)化說到底就是一棵樹等價(jià)地轉(zhuǎn)換為 另一棵樹。SQL中經(jīng)典的優(yōu)化規(guī)則有很多,下文結(jié)合示例介紹三種比較常?的規(guī)則:謂詞下推(Predicate Pushdown)、常量累加(Constant Folding)和列值裁剪(Column Pruning)
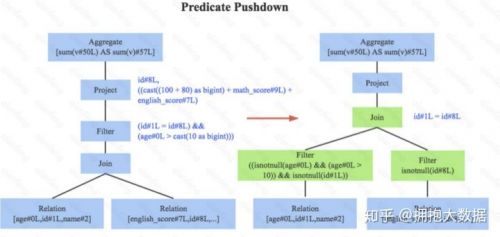
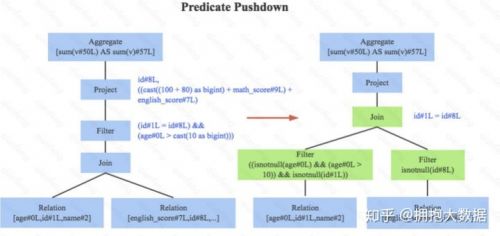
1.謂詞下推, 下圖左邊是經(jīng)過Analyzer解析后的語法樹,語法樹中兩個(gè)表先做join,之后再使用age>10對結(jié)果進(jìn)行過濾。大家知道join算子通常是一個(gè)非常耗時(shí)的算子,耗時(shí)多少一般取決于參與join的兩個(gè)表的大小,如果能夠減少參與join兩表的大小,就可以大大降低join算子所需 時(shí)間。謂詞下推就是這樣一種功能,它會(huì)將過濾操作下推到j(luò)oin之前進(jìn)行,下圖中過濾條件age>0以及id!=null兩個(gè)條件就分別下推到了join之前。這樣,系統(tǒng)在掃描數(shù)據(jù)的時(shí)候就對數(shù)據(jù) 進(jìn)行了過濾,參與join的數(shù)據(jù)量將會(huì)得到顯著的減少,join耗時(shí)必然也會(huì)降低。
2.常量累加,如下圖。 常量累加其實(shí)很簡單,就是 x+(1+2) -> x+3 這樣的規(guī)則,雖然是一個(gè)很小的改動(dòng),但是意義巨大。示例如果沒有進(jìn)行優(yōu)化的話,每一條結(jié)果都需要執(zhí)行一次100+80的操作,然后再與變量math_score以及english_score相加,而優(yōu)化后就不需要再執(zhí)行100+80操作。
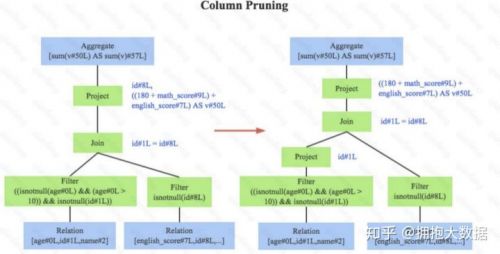
3.列值裁剪,如下圖。這是一個(gè)經(jīng)典的規(guī)則,示例中對于people表來說,并不需要掃描它的所有列值,而只需要列值id,所以在掃描people之后需要將其他列進(jìn)行裁剪,只留下列id。這個(gè) 優(yōu)化一方面大幅度減少了網(wǎng)絡(luò)、內(nèi)存數(shù)據(jù)量消耗,另一方面對于列存數(shù)據(jù)庫(Parquet)來說 大大提高了掃描效率
物理計(jì)劃
經(jīng)過上述步驟,邏輯執(zhí)行計(jì)劃已經(jīng)得到了比較完善的優(yōu)化,然而,邏輯執(zhí)行計(jì)劃依然沒辦法真正執(zhí)行,他們只是邏輯上可行,實(shí)際上Spark并不知道如何去執(zhí)行這個(gè)東?。比如Join只是一個(gè)抽象概 念,代表兩個(gè)表根據(jù)相同的id進(jìn)行合并,然而具體怎么實(shí)現(xiàn)這個(gè)合并,邏輯執(zhí)行計(jì)劃并沒有說明。
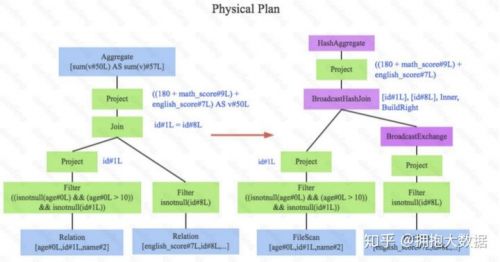
此時(shí)就需要將邏輯執(zhí)行計(jì)劃轉(zhuǎn)換為物理執(zhí)行計(jì)劃,將邏輯上可行的執(zhí)行計(jì)劃變?yōu)镾park可以真正執(zhí) 行的計(jì)劃。比如Join算子,Spark根據(jù)不同場景為該算子制定了不同的算法策略,有BroadcastHashJoin、ShuffleHashJoin以及SortMergeJoin等(可以將Join理解為一個(gè)接口, BroadcastHashJoin是其中一個(gè)具體實(shí)現(xiàn)),物理執(zhí)行計(jì)劃實(shí)際上就是在這些具體實(shí)現(xiàn)中挑選一個(gè)耗時(shí)最小的算法實(shí)現(xiàn),這個(gè)過程涉及到基于代價(jià)優(yōu)化(CBO)策略,所謂基于代價(jià) , 是因?yàn)槲锢韴?zhí)行計(jì)劃的每一個(gè)節(jié)點(diǎn)都是有執(zhí)行代價(jià)的,這個(gè)代價(jià)主要分為兩部分
第一部分:該執(zhí)行節(jié)點(diǎn)對數(shù)據(jù)集的影響,或者說該節(jié)點(diǎn)輸出數(shù)據(jù)集的大小與分布(需要去采集)
第二部分:該執(zhí)行節(jié)點(diǎn)操作算子的代價(jià)(相對固定,可用規(guī)則來描述)
在SQL 執(zhí)行之前會(huì)根據(jù)代價(jià)估算確定一種代價(jià)最小的方案來執(zhí)行。我們這里以Join為例子做個(gè)簡單說明
*在 Spark SQL 中 ,Join 可 分 為 Shuffle based Join 和 BroadcastJoin 。 Shuffle basedJoin 需要引入 Shuffle,代價(jià)相對較高。BroadcastJoin 無須 Join,但要求至少有一張表足夠小,能通過 Spark 的 Broadcast 機(jī)制廣播到每個(gè) Executor 中。
*在不開啟 CBO 中,Spark SQL 通過 spark.sql.autoBroadcastJoinThreshold 判斷是否啟用BroadcastJoin。其默認(rèn)值為 10485760 即 10 MB。并且該判斷基于參與 Join 的表的原始大小。
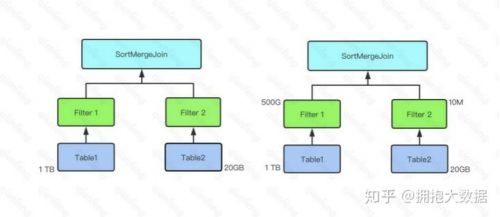
*在下圖示例中,Table 1 大小為 1 TB,Table 2 大小為 20 GB,因此在對二者進(jìn)行 join 時(shí),由于二者都遠(yuǎn)大于自動(dòng) BroatcastJoin 的閾值,因此 Spark SQL 在未開啟 CBO 時(shí)選用 SortMergeJoin 對二者進(jìn)行 Join。
*而開啟 CBO 后,由于 Table 1 經(jīng)過 Filter 1 后結(jié)果集大小為 500 GB,Table 2 經(jīng)過 Filter 2后結(jié)果集大小為 10 MB 低于自動(dòng) BroatcastJoin 閾值,因此 Spark SQL 選用 BroadcastJoin。
學(xué)習(xí)大數(shù)據(jù)開發(fā),可以參考千鋒大數(shù)據(jù)培訓(xùn)班提供的大數(shù)據(jù)學(xué)習(xí)路線,千鋒大數(shù)據(jù)培訓(xùn)機(jī)構(gòu)的學(xué)習(xí)路線提供完整的大數(shù)據(jù)開發(fā)知識體系,內(nèi)容包含Linux&&Hadoop生態(tài)體系、大數(shù)據(jù)計(jì)算框架體系、云計(jì)算體系、機(jī)器學(xué)習(xí)&&深度學(xué)習(xí)。根據(jù)千鋒大數(shù)據(jù)培訓(xùn)班提供的大數(shù)據(jù)學(xué)習(xí)路線圖可以讓你對學(xué)習(xí)大數(shù)據(jù)需要掌握的知識有個(gè)清晰的了解,并快速入門大數(shù)據(jù)開發(fā)。想要獲取免費(fèi)的大數(shù)據(jù)學(xué)習(xí)資料可以添加我們的大數(shù)據(jù)技術(shù)交流qq群:857910996,加群找管理領(lǐng)取即可,有任何大數(shù)據(jù)相關(guān)問題也可以加群解決,等你來哦~~















 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號