


三、 數據傾斜解決方案
3.1 Hive ETL處理
3.1.1 適用場景
導致數據傾斜的是 Hive 表。如果該 Hive 表中的數據本身很不均勻(比如某個 key 對應了 100 萬數 據,其他 key 才對應了 10 條數據),而且業務場景需要頻繁使用 Spark 對 Hive 表執行某個分析操 作,那么比較適合使用這種技術方案
3.1.2 實現思路
此時可以評估一下,是否可以通過Hive來進行數據預處理(即通過 Hive ETL 預先對數據按照 key 進行 聚合,或者是預先和其他表進行join),然后在 Spark 作業中針對的數據源就不是原來的 Hive 表了, 而是預處理后的Hive表。此時由于數據已經預先進行過聚合或join操作了,那么在 Spark 作業中也就不 需要使用原先的 shuffle 類算子執行這類操作了。
3.1.3 實現原理
這種方案從根源上解決了數據傾斜,因為徹底避免了在Spark中執行shuffle類算子,那么肯定就不會有 數據傾斜的問題了。但是這里也要提醒一下大家,這種方式屬于治標不治本。因為畢竟數據本身就存在 分布不均勻的問題,所以Hive ETL中進行group by或者join等shuffle操作時,還是會出現數據傾斜,導 致Hive ETL的速度很慢。我們只是把數據傾斜的發生提前到了Hive ETL中,避免Spark程序發生數據傾 斜而已。
3.1.4 方案優缺點
* 優點: 實現起來簡單便捷,效果還非常好,完全規避掉了數據傾斜,Spark作業的性能會大幅度提升。
* 缺點:治標不治本,Hive ETL中還是會發生數據傾斜。
3.1.5 企業最佳實踐
* 在一些 Java 系統與 Spark 結合使用的項目中,會出現 Java 代碼頻繁調用 Spark 作業的場景,而且對 Spark 作業的執行性能要求很高,就比較適合使用這種方案。將數據傾斜提前到上游的 Hive ETL,每天 僅執行一次,只有那一次是比較慢的,而之后每次 Java 調用 Spark作業時,執行速度都會很快,能夠 提供更好的用戶體驗。
* 在美團·點評的交互式用戶行為分析系統中使用了這種方案,該系統主要是允許用戶通過 Java Web 系統 提交數據分析統計任務,后端通過Java 提交 Spark作業進行數據分析統計。要求 Spark 作業速度必須要 快,盡量在10 分鐘以內,否則速度太慢,用戶體驗會很差。所以我們將有些 Spark 作業的shuffle操作 提前到了Hive ETL中,從而讓 Spark 直接使用預處理的 Hive 中間表,盡可能地減少 Spark 的 shuffle操 作,大幅度提升了性能,將部分作業的性能提升了6倍以上。
3.2 調整shuffle操作的并行度
3.2.1 適用場景
大量不同的Key被分配到了相同的Task造成該Task數據量過大。
如果我們必須要對數據傾斜迎難而上,那么建議優先使用這種方案,因為這是處理數據傾斜最簡單的一 種方案。但是也是一種屬于碰運氣的方案。因為這種方案,并不能讓你一定解決數據傾斜,甚至有可能 加重。那當然,總歸,你會調整到一個合適的并行度是能解決的。前提是這種方案適用于 Hash散列的 分區方式。湊巧的是,各種分布式計算引擎,比如MapReduce,Spark 等默認都是使用 Hash散列的方 式來進行數據分區。
Spark 在做 Shuffle 時,默認使用 HashPartitioner(非Hash Shuffle)對數據進行分區。如果并行度設 置的不合適,可能造成大量不相同的 Key 對應的數據被分配到了同一個 Task 上,造成該 Task 所處理 的數據遠大于其它 Task,從而造成數據傾斜。
如果調整 Shuffle 時的并行度,使得原本被分配到同一 Task 的不同 Key 發配到不同 Task 上處理,則可 降低原 Task 所需處理的數據量,從而緩解數據傾斜問題造成的短板效應。
3.2.2 實現思路
在對 RDD 執行 Shuffle 算子時,給 Shuffle 算子傳入一個參數,比如 reduceByKey(1000),該參數就 設置了這個 shuffle 算子執行時shuffle read task 的數量。對于 Spark SQL 中的 Shuffle 類語句,比如 group by、join 等,需要設置一個參數,即 spark.sql.shuffle.partitions,該參數代表了 shuffle readTask 的并行度,該值默認是 200,對于很多場景來說都有點過小。
3.2.3 實現原理
增加 shuffle read task 的數量,可以讓原本分配給一個 task 的多個 key 分配給多個 task,從而讓每個 task 處理比原來更少的數據。舉例來說,如果原本有 5 個key,每個 key 對應 10 條數據,這 5 個 key 都是分配給一個 task 的,那么這個 task 就要處理 50 條數據。而增加了 shuffle read task 以后,每個 task 就分配到一個 key,即每個 task 就處理 10 條數據,那么自然每個 task 的執行時間都會變短了。 具體原理如下圖所示。
一句話總結:調整并行度分散同一個 Task的不同 Key,之前由于運氣比較差,多個數據比較多的 key 都分布式在同一個 Task 上,如果調整了并行度,極大可能會讓這些 key 分布式到不同的 Task,有效緩 解數據傾斜。
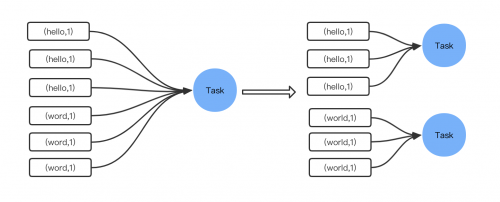
3.2.4 方案優缺點
* 優點: 實現起來比較簡單,可以有效緩解和減輕數據傾斜的影響。實現簡單,可在需要Shuffle的操作算子上直接設 置并行度或者使用spark.default.parallelism設置。如果是Spark SQL,還可通過SET spark.sql.shuffle.partitions=[num_tasks]設置并行度。可用最小的代價解決問題。一般如果出現 數據傾斜,都可以通過這種方法先試驗幾次,如果問題未解決,再嘗試其它方法。
* 缺點:只是緩解了數據傾斜而已,沒有徹底根除問題,根據實踐經驗來看,其效果有限。適用場景少,只能將分配到 同一Task的不同Key分散開,但對于同一Key傾斜嚴重的情況該方法并不適用。并且該方法一般只能緩解數據 傾斜,沒有徹底消除問題。從實踐經驗來看,其效果一般。
3.2.5 企業最佳實踐
* 該方案通常無法徹底解決數據傾斜,因為如果出現一些極端情況,比如某個key對應的數據量有100萬, 那么無論你的task數量增加到多少,這個對應著100萬數據的key肯定還是會分配到一個task中去處理, 因此注定還是會發生數據傾斜的。所以這種方案只能說是在發現數據傾斜時嘗試使用的第一種手段,嘗 試去用嘴簡單的方法緩解數據傾斜而已,或者是和其他方案結合起來使用
3.3 過濾少數導致傾斜的key
3.3.1 適用場景
如果發現導致傾斜的 key 就少數幾個,而且對計算本身的影響并不大的話,那么很適合使用這種方案。 比如 99% 的 key 就對應 10 條數據,但是只有一個 key 對應了 100 萬數據,從而導致了數據傾斜。
3.3.2 實現思路
如果我們判斷那少數幾個數據量特別多的 key,對作業的執行和計算結果不是特別重要的話,那么干脆 就直接過濾掉那少數幾個 key。比如,在 Spark SQL 中可以使用 where 子句過濾掉這些 key 或者在 SparkCore 中對 RDD 執行 filter 算子過濾掉這些 key。如果需要每次作業執行時,動態判定哪些 key 的數據量最多
然后再進行過濾,那么可以使用 sample 算子對 RDD 進行采樣,然后計算出每個 key 的 數量,取數據量最多的 key 過濾掉即可。
3.2.3 實現原理
將導致數據傾斜的 key 給過濾掉之后,這些 key 就不會參與計算了,自然不可能產生數據傾斜。
3.3.4 方案優缺點
* 優點:實現簡單,而且效果也很好,可以完全規避掉數據傾斜。
* 缺點:適用場景不多,大多數情況下,導致傾斜的key還是很多的,并不是只有少數幾個
3.3.5 企業最佳實踐
* 在項目中我們也采用過這種方案解決數據傾斜。有一次發現某一天 Spark 作業在運行的時候突然 OOM 了,追查之后發現,是 Hive 表中的某一個 key 在那天數據異常,導致數據量暴增。因此就采取每次執 行前先進行采樣,計算出樣本中數據量最大的幾個 key 之后,直接在程序中將那些key給過濾掉。
3.4 將reduce join轉為map join
3.4.1 適用場景
在對 RDD 使用 join 類操作,或者是在 Spark SQL 中使用 join 語句時,而且 join 操作中的一個 RDD 或 表的數據量比較小(比如幾百M或者一兩G),比較適用此方案。
在分布式計算引擎中,實現Join的思路有兩種: 1、MapJoin,顧名思義,Join邏輯的完成是在 Mapper 階段就完成了,這是假定執行的是 MapReduce任務,如果是 Spark任務,表示只用一個 Stage 就執行完了 Join 操作。
* 優點:避免了兩階段之間的shuffle,效率高,沒有shuffle也就沒有了傾斜。
* 缺點:多使用內存資源,只適合大小表做join的場景
2、ReduceJoin,顧名思義,Join邏輯的完成是在 Reducer 階段完成的。那么如果是MapReduce任 務,則表示 Maper階段執行完之后把數據 Shuffle到 Reducer階段來執行 Join 邏輯,那么就可能導致數 據傾斜。如果是 Spark任務,意味著,上一個stage的執行結果數據shuffle到 下一個stage中來完成 Join 操作,同樣也可能產生數據傾斜。
* 優點:這是一種通用的join,在不產生數據傾斜的情況下,能完成各種類型的join
* 缺點:會發生數據傾斜的情況
3.4.2 實現思路
不使用join算子進行連接操作,而使用Broadcast變量與map類算子實現join操作,進而完全規避掉 shuffle類的操作,徹底避免數據傾斜的發生和出現。將較小
RDD中的數據直接通過collect算子拉取到 Driver端的內存中來,然后對其創建一個Broadcast變量;接著對另外一個RDD執行map類算子,在算 子函數內,從Broadcast變量中獲取較小RDD的全量數據,與當前RDD的每一條數據按照連接key進行 比對,如果連接key相同的話,那么就將兩個RDD的數據用你需要的方式連接起來。
3.4.3 實現原理
普通的 join 是會走 shuffle 過程的,而一旦 shuffle,就相當于會將相同 key 的數據拉取到一個 shuffle read task 中再進行 join,此時就是 reduce join。但是如果一個 RDD 是比較小的,則可以采用廣播小 RDD 全量數據 +map 算子來實現與 join 同樣的效果,也就是 map join,此時就不會發生 shuffle 操 作,也就不會發生數據傾斜。具體原理如下圖所示。
3.4.4 方案優缺點
* 優點: 對join操作導致的數據傾斜,效果非常好,因為根本就不會發生shuffle,也就根本不會發生數據傾斜。
* 缺點: 適用場景較少,因為這個方案只適用于一個大表和一個小表的情況。畢竟我們需要將小表進行廣播,此時會比 較消耗內存資源,driver 和每個Executor 內存中都會駐留一份小 RDD 的全量數據。如果我們廣播出去 的 RDD 數據比較大,比如 10G 以上,那么就可能發生內存溢出了。因此并不適合兩個都是大表的情況。
3.5 采樣傾斜 key并分拆 join操作
3.5.1 適用場景
兩個 RDD/Hive 表進行 join 的時候,如果數據量都比較大,無法采用3.5方案,那么此時可以看一 下兩個 RDD/Hive 表中的 key 分布情況。如果出現數據傾斜,是因為其中某一個 RDD/Hive 表中的少數 幾個 key 的數據量過大,而另一個 RDD/Hive 表中的所有 key 都分布比較均勻,那么采用這個解決方案 是比較合適的。
3.5.2 實現思路
1. 對包含少數幾個數據量過大的key的那個RDD,通過sample算子采樣出一份樣本來,然后統計一下每個 key的數量,計算出來數據量最大的是哪幾個key。
2. 然后將這幾個key對應的數據從原來的RDD中拆分出來,形成一個單獨的RDD,并給每個key都打上n以內的 隨機數作為前綴,而不會導致傾斜的大部分key形成另外一個RDD。
3. 接著將需要join的另一個RDD,也過濾出來那幾個傾斜key對應的數據并形成一個單獨的RDD,將每條數據 膨脹成n條數據,這n條數據都按順序附加一個0~n的前綴,不會導致傾斜的大部分key也形成另外一個RDD。
4. 再將附加了隨機前綴的獨立RDD與另一個膨脹n倍的獨立RDD進行join,此時就可以將原先相同的key打散 成n份,分散到多個task中去進行join了。
5. 而另外兩個普通的RDD就照常join即可。
6. 最后將兩次join的結果使用union算子合并起來即可,就是最終的join結果。
3.5.3 實現原理
對于 join 導致的數據傾斜,如果只是某幾個 key 導致了傾斜,可以將少數幾個 key 分拆成獨立 RDD, 并附加隨機前綴打散成 n 份去進行join,此時這幾個 key 對應的數據就不會集中在少數幾個 task 上, 而是分散到多個 task 進行 join 了。具體原理見下圖。
3.5.4 方案優缺點
* 優點: 對于join導致的數據傾斜,如果只是某幾個key導致了傾斜,采用該方式可以用最有效的方式打散key進行 join。而且只需要針對少數傾斜key對應的數據進行擴容n倍,不需要對全量數據進行擴容。避免了占用過多 內存。
* 缺點: 如果導致傾斜的key特別多的話,比如成千上萬個key都導致數據傾斜,那么這種方式也不適合。
3.6 兩階段聚合(局部聚合+全局聚合)
3.6.1 適用場景
對RDD執行reduceByKey等聚合類shuffle算子或者在Spark SQL中使用group by語句進行分組聚合時, 比較適用這種方案。
3.6.2 實現思路
這個方案的核心實現思路就是進行兩階段聚合。第一次是局部聚合,先給每個key都打上一個隨機數, 比如10以內的隨機數,此時原先一樣的key就變成不一樣的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就會變成(1hello, 1) (1hello, 1) (2hello, 1) (2hello, 1)。接著對打上隨機數后的數據,執行 reduceByKey等聚合操作,進行局部聚合,那么局部聚合結果,就會變成了(1hello, 2) (2hello, 2)。然 后將各個key的前綴給去掉,就會變成(hello,2)(hello,2),再次進行全局聚合操作,就可以得到最終結果 了,比如(hello, 4)。
3.6.3 實現原理
將原本相同的key通過附加隨機前綴的方式,變成多個不同的key,就可以讓原本被一個task處理的數據 分散到多個task上去做局部聚合,進而解決單個task處理數據量過多的問題。接著去除掉隨機前綴,再 次進行全局聚合,就可以得到最終的結果。具體原理見下圖。
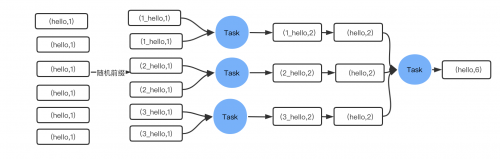
3.6.4 方案優缺點
* 優點: 對于聚合類的shuffle操作導致的數據傾斜,效果是非常不錯的。通常都可以解決掉數據傾斜,或者至少是大 幅度緩解數據傾斜,將Spark作業的性能提升數倍以上。
* 缺點: 僅僅適用于聚合類的shuffle操作,適用范圍相對較窄。如果是join類的shuffle操作,還得用其他的解決 方案。
3.7 使用隨機前綴和擴容 RDD 進行 join
3.7.1 適用場景
如果在進行 join 操作時,RDD 中有大量的 key 導致數據傾斜,那么進行分拆 key 也沒什么意義。
3.7.2 實現思路
1. 該方案的實現思路基本和3.5方案類似,首先查看 RDD/Hive 表中的數據分布情況,找到那個造成 數據傾斜的 RDD/Hive 表,比如有多個key 都對應了超過1萬條數據。
2. 然后將該RDD的每條數據都打上一個n以內的隨機前綴。
3. 同時對另外一個正常的RDD進行擴容,將每條數據都擴容成n條數據,擴容出來的每條數據都依次打上一個 0~n的前綴。
4. 最后將兩個處理后的RDD進行join即可。
3.7.3 實現原理
將原先一樣的 key 通過附加隨機前綴變成不一樣的key,然后就可以將這些處理后的“不同key”分散到多 個task中去處理,而不是讓一個task處理大量的相同key。該方案與3.6方案的不同之處就在于,上 一種方案是盡量只對少數傾斜key對應的數據進行特殊處理,由于處理過程需要擴容RDD,因此上一種 方案擴容RDD后對內存的占用并不大;而這一種方案是針對有大量傾斜key的情況,沒法將部分key拆分 出來進行單獨處理,因此只能對整個RDD進行數據擴容,對內存資源要求很高。
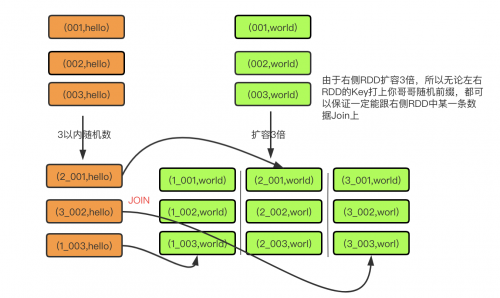
3.7.4 方案優缺點
* 優點: 對join類型的數據傾斜基本都可以處理,而且效果也相對比較顯著,性能提升效果非常不錯。
* 缺點: 該方案更多的是緩解數據傾斜,而不是徹底避免數據傾斜。而且需要對整個RDD進行擴容,對內存資源要求很 高。
3.7.5 企業最佳實踐
* 開發一個數據需求的時候,發現一個join導致了數據傾斜。優化之前,作業的執行時間大約是60分鐘左右;使用該方案優化之后,執行時間縮短到10分鐘左右,性能提升了6倍。
3.8 任務橫切,一分為二,單獨處理
3.8.1 適用場景
有時候,一個Spark應用程序中,導致傾斜的因素不是一個單一的,比如有一部分傾斜的因素是null, 有一部分傾斜的因素是某些個key分布特別多。那么拆分出來也得使用不同的手段來處理
3.8.2 實現思路
在了解清楚數據的分布規律,以及確定了數據傾斜是由何種原因導致的,那么按照這些原因,進行數據的拆分,然后單獨處理每個部分的數據,最后把結果合起來。
3.8.3 實現原理
3.6方案其實是一種縱切,3.8方案就是一種橫切。原理同思路。
3.8.4 方案優缺點
* 優點: 將多種簡單的方案綜合起來,解決一個復雜的問題。可以算上一種萬能的方案。
* 缺點: 確定數據傾斜的因素比較復雜,導致解決該數據傾斜的方案比較難實現落地。代碼復雜度也較高。
3.9 多方案組合使用
* 在實踐中發現,很多情況下,如果只是處理較為簡單的數據傾斜場景,那么使用上述方案中的某一種基 本就可以解決。但是如果要處理一個較為復雜的數據傾斜場景,那么可能需要將多種方案組合起來使 用。比如說,我們針對出現了多個數據傾斜環節的Spark作業,可以先運用3.1和3.2方案,預處理一 部分數據,并過濾一部分數據來緩解;其次可以對某些shuffle操作提升并行度,優化其性能;最后還可 以針對不同的聚合或join操作,選擇一種方案來優化其性能。大家需要對這些方案的思路和原理都透徹 理解之后,在實踐中根據各種不同的情況,靈活運用多種方案,來解決自己的數據傾斜問題。
* 如果這多種方案,組合使用也不行,最后一招:自定義分區規則
3.10 自定義Partitioner
3.10.1 適用場景
大量不同的Key被分配到了相同的Task造成該Task數據量過大。
3.10.2 實現思路
先通過抽樣,了解數據的 key 的分布規律,然后根據規律,去定制自己的數據分區規則,盡量保證所有 的 Task 的數據量相差無幾。
3.10.3 實現原理
使用自定義的 Partitioner(默認為HashPartitioner),將原本被分配到同一個 Task 的不同 Key 分配 到不同 Task。
3.10.4 分區方案
• 隨機分區
* 優點: 數據分布均勻
* 缺點: 具有相同特點的數據不會保證被分配到相同的分區
• 輪詢分區
* 優點: 確保一定不會出現數據傾斜
* 缺點: 無法根據存儲/計算能力分配存儲/計算壓力
• Hash散列
* 優點: 具有相同特點的數據保證被分配到相同的分區
* 缺點: 極容易產生數據傾斜
• 范圍分區
* 優點: 相鄰的數據都在相同的分區
* 缺點: 部分分區的數據量會超出其他的分區,需要進行裂變以保持所有分區的數據量是均勻的,如果每個分區不排序,那么裂變就會非常困難
3.10.5 方案優缺點
* 優點: 靈活,通用。
* 缺點: 必須根據對應的場景設計合理的分區方案。沒有現成的方案可用,需臨時實現。
四、案例
4.1 問題
如果是兩張特大寬表做 Join 怎么辦?
# 解決方案: 位圖法
4.2 例子
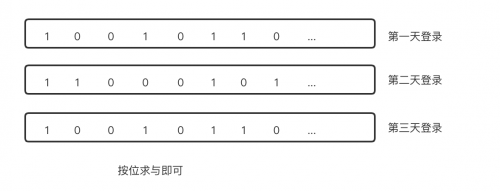
最近7天連續登錄的用戶有哪些?假如每天登陸的用戶存在多張表或者一張表的多個分區中。如果用戶基數很高比如10億。 那Join的方案將會比較低效。位圖解決是一個不錯的方案
4.3 實現思路
對每一天的用戶登陸數據維護一個Bitmap, 如果用戶登錄對應的Bitmap位就置為1。將7個Bitmap按位求與,就可以得到7天連續登錄的用戶了。














 京公網安備 11010802030320號
京公網安備 11010802030320號