


大數據經典面試題答疑---經常問的原理問題總結(系列文章,持續更新),幫你解決大數據開發中的困擾.
1. HDFS

1.1. 讀數據

1.2. 寫數據
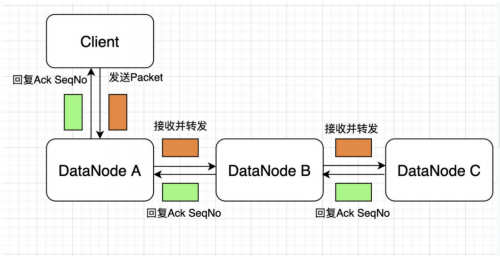

如果在寫的過程中某個datanode發生錯誤,會采取以下幾步:
1) pipeline被關閉掉;
2)為了防止防止丟包ack quene里的packet會同步到data quene里;
3)把產生錯誤的datanode上當前在寫但未完成的block刪掉;
4)block剩下的部分被寫到剩下的兩個正常的datanode中;
5)namenode找到另外的datanode去創建這個塊的復制。當然,這些操作對客戶端來說是無感知的。
6.當客戶端結束寫入數據,則調用stream的close函數。此操作將所有的數據塊寫入pipeline中的數據節點,并等待ack queue返回成功。最后通知元數據節點寫入完畢。
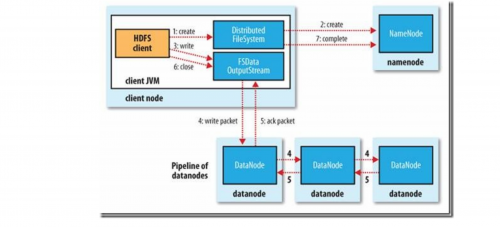
校驗
1.2.1. HDFS在寫入過程中如何保證packet傳輸的一致性
hdfs寫入的時候計算出校驗和,然后每次讀的時候再計算校驗和。hdfs每固定長度就會計算一次校驗和,這個值由io.bytes.per.checksum指定,默認是512字節。因為CRC32是32位即4個字節,這樣校驗和占用的空間就會少于原數據的1%。
datanode在存儲收到的數據前會校驗數據的校驗和,比如收到客戶端的數據或者其他副本傳過來的數據。hdfs數據流中客戶端寫入數據到hdfs時的數據流,在管道的最后一個datanode會去檢查這個校驗和,如果發現錯誤,就會拋出ChecksumException到客戶端。
可以在對FileSystem調用open()之前調用setVerifyChecksum()來禁止校驗和檢測.
也可以通過在shell中執行-get,-copyToLocal命令時指定-ignoreCrc選項做到.
1.3. namenode
根據元數據增長趨勢,參考本文前述的內存空間占用預估方法,能夠大體得到NameNode常駐內存大小,一般按照常駐內存占內存總量~60%調整JVM內存大小可基本滿足需求。
為避免GC出現降級的問題,可將CMSInitiatingOccupancyFraction調整到~70。
NameNode重啟過程中,尤其是DataNode進行BlockReport過程中,會創建大量臨時對象,為避免其晉升到Old區導致頻繁GC甚至誘發FGC,可適當調大Young區(-XX:NewRatio)到10~15。
據了解,針對NameNode的使用場景,使用CMS內存回收策略,將HotSpot JVM內存空間調整到180GB,可提供穩定服務。繼續上調有可能對JVM內存管理能力帶來挑戰,尤其是內存回收方面,一旦發生FGC對應用是致命的。這里提到180GB大小并不是絕對值,能否在此基礎上繼續調大且能夠穩定服務不在本文的討論范圍。結合前述的預估方法,當可用JVM內存達180GB時,可管理元數據總量達~700M,基本能夠滿足中小規模以下集群需求。
參考:https://blog.csdn.net/lingbo229/article/details/81079769
結論:
1、Total = 198 ∗ num(Directory + Files) + 176 ∗ num(blocks) + 2% ∗ size(JVM Memory Size)
2、受JVM可管理內存上限等物理因素,180G內存下,NameNode服務上限的元數據量約700M。更多關于“大數據培訓”的問題,歡迎咨詢千鋒教育在線名師。千鋒教育多年辦學,課程大綱緊跟企業需求,更科學更嚴謹,每年培養泛IT人才近2萬人。不論你是零基礎還是想提升,都可以找到適合的班型,千鋒教育隨時歡迎你來試聽。














 京公網安備 11010802030320號
京公網安備 11010802030320號