


接下來幾周的文章我們會給大家主要介紹Pandas的使用,Pandas是一個Python 的包,提供快速、靈活和富有表現(xiàn)力的數(shù)據(jù)結(jié)構(gòu),旨在使"關(guān)系或標記數(shù)據(jù)的使用既簡單又直觀"。它的目標是成為用Python進行實際的、真實的數(shù)據(jù)分析的基礎(chǔ)高級模塊。
**Pandas的數(shù)據(jù)結(jié)構(gòu)**,分兩種:**Series**和**DataFrame**.
> 1、Series 一維,帶標簽數(shù)組 Series的中文意思是序列,系列.
> 2、DataFrame 二維,Series容器
本篇文章主要介紹Series的使用。:
#### Series簡介
Serial對象本質(zhì)上由兩個數(shù)組構(gòu)成,一個數(shù)組構(gòu)成對象的健(index,索引),一個數(shù)組構(gòu)成對象的值(values).因此Series可以看作是鍵值對。Series是**帶標簽**的一維數(shù)組,可存儲整數(shù)、浮點數(shù)、字符串、Python 對象等類型的數(shù)據(jù)。軸標簽統(tǒng)稱為**索引,**它由兩部分組成**。**
- values:一組數(shù)據(jù)(ndarray類型)
- index:相關(guān)的數(shù)據(jù)索引標簽
如圖:

特點:標簽(index)與數(shù)據(jù)(value)默認對齊,除非特殊情況,一般不會斷開連接,因此通過索引取值非常方便,不需要循環(huán),可以直接通過字典方式,key 獲取value.
#### Series 創(chuàng)建的幾種方式
創(chuàng)建Series對象使用Pandas中的Series,
```
Series組成部分:pd.Series(data=None, index=None, dtype=None)
其中參數(shù):data參數(shù)支持多種數(shù)據(jù)類型,比如列表,字典等,index是一個可選參數(shù)表示索引標簽,通過dtype指定數(shù)據(jù)類型
```
Series的創(chuàng)建方式有多種:
> 1. 標量創(chuàng)建
> 2. 列表創(chuàng)建
> 3. numpy創(chuàng)建
> 4. 字典創(chuàng)建
**標量創(chuàng)建:**
```
import numpy as np
import pandas as pd
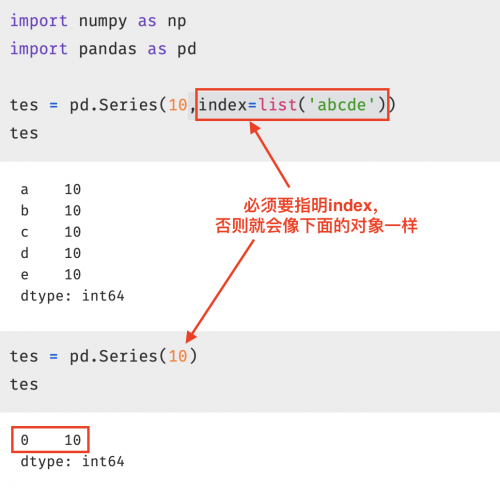
tes = pd.Series(10,index=list('abcde'))
tes
```
**列表創(chuàng)建**
即已知一個list結(jié)構(gòu)的數(shù)據(jù),通過該數(shù)據(jù)創(chuàng)建Series對象。
```
# lst = [11,0,3,7,9,19,4]
# s = pd.Series(lst) # 默認隱式索引
# s
lst = [11,0,3,7,9,19,4]
s = pd.Series(lst,index=["A","B","C","D","E","F","G"]) # 通過index設(shè)置顯式索引
s
```

**numpy創(chuàng)建**
即Series中傳入的是ndarray對象。
```
# data = np.random.randint(0,100,size=(6,))
# s = pd.Series(data=data)
# s
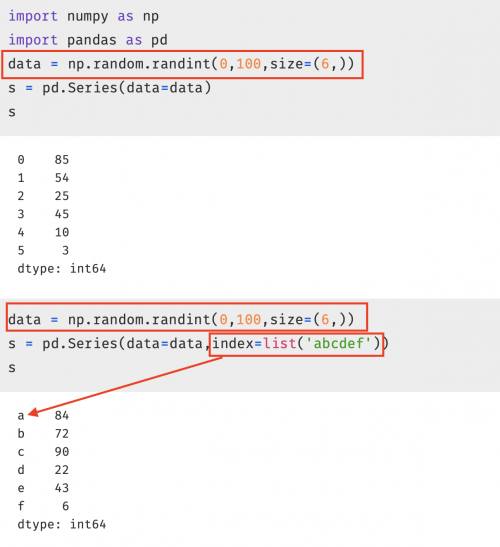
data = np.random.randint(0,100,size=(6,))
s = pd.Series(data=data,index=list('abcdef'))
s
```
結(jié)果:
**字典創(chuàng)建**
```
dic = {"A":1,"B":2,"C":3,"D":2}
s = pd.Series(dic) # 索引默認就是字典的key值
s
```
結(jié)果:

#### Series的索引和切片
因為Series只有一列,因此一般只對行進行操作,索引分為隱式索引和顯示索引,因此不同的方式操作起來也不一樣。
索引分別為哪些呢?
> 1. 位置下標
>
> 2. 標簽索引
> 3. 布爾型索引
> 4. 切片索引
位置下標:當使用默認值索引的時候,通常使用位置下標。類似列表的索引使用方式
```
data = np.random.randint(0,100,size=(6,))
s = pd.Series(data=data)
print(s[0])
print(s[3])
print(s[4])
```

標簽索引:類似字典通過key獲取value的方式,通常用在顯示索引的時候。
```
data = np.random.randint(0,100,size=(6,))
s = pd.Series(data=data,index=list('abcdef'))
print(s['a'])
print(s['f'])
print(s['c'])
```
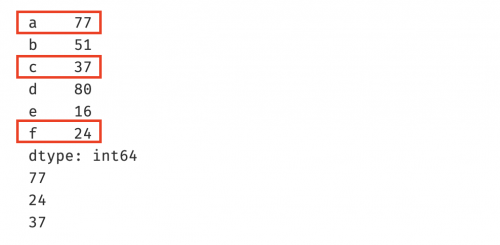
布爾型索引: 通過一個布爾型的數(shù)組獲取Series對象中的值。
```
data = np.random.randint(0,100,size=(6,))
s = pd.Series(data=data,index=list('abcdef'))
print(s)
s2 = s>50 # 獲取s中大于50的元素,結(jié)果會是一個bool類型的數(shù)組
print(s2) # 打印s2得到的是一個bool類型的數(shù)組
print(s[s2]) # 通過s2這個bool數(shù)組獲取s中的元素
```
結(jié)果:

切片索引:即切片,類似列表的切片使用,但是又有所區(qū)別。
隱式索引的使用:
```
data = np.random.randint(0,100,size=(6,))
s = pd.Series(data=data)
print(s)
print(s[1:5])
print(s[:4])
print(s[2:])
print(s[::2])
```
結(jié)果:

當然也可以使用iloc完成Series對象中元素的獲取,使用方式如下:
```
data = np.random.randint(0,100,size=(6,))
s = pd.Series(data=data)
print(s.iloc[2]) # 指定下標
print(s.iloc[1:3]) # 指定切片范圍
```
結(jié)果:

顯示索引的切片使用
```
data = np.random.randint(0,100,size=(6,))
s = pd.Series(data=data,index=list('abcdef'))
print(s)
print(s['a':'d'])
print(s['a':])
print(s[:'f'])
print(s[::2])
```
結(jié)果:

顯示索引也可以使用loc的方式獲取元素
```
print(s.loc['a':'e'])
print(s.loc[['a','c','f']])
```
結(jié)果:

總結(jié):
1. **Series的索引和切片只針對行而言,因為它只有一列**
2. **loc是對于顯式索引的相關(guān)操作(對于標簽的處理),iloc是針對隱式索引的相關(guān)操作(對于整數(shù)的處理)。**
3. **我們發(fā)現(xiàn)其實s[0:2] 與 s.iloc[0:2]沒有太大差別(顯式索引也是一樣),這并不說明iloc就沒有用,個人覺得它更有意義的是在DataFrame當中使用**
#### Series的基本使用
**顯示Series部分數(shù)據(jù)內(nèi)容**
**s.head(n)** 該函數(shù)代表的意思是顯示前多少行,可以指定顯示的行數(shù),不寫n默認是前5行
**s.tail(n)** 該函數(shù)代表的意思是顯示后多少行,可以指定顯示的行數(shù),不寫n默認是前5行
**s.unique()** 去除重復(fù)的值
**s.notnull()** 不為空返回True,為空返回False
**s.isnull()** 不為空返回False,為空返回True
```text
lst = [1,3,5,6,10,23]
s1 = pd.Series(lst,index=["A","B","C","D","E","F"])
print(s1.head()) # 獲取前5行
print(s1.tail()) # 獲取后5行
print(s1.unique()) # 去除重復(fù)的值
s1['D']=None # 修改D索引對應(yīng)的值為None
print(s1.isnull()) # 判斷是否有空值
print(s1.notnull()) # 判斷是否有非空值
```
結(jié)果:
















 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號