


Spark Streaming 反壓機制是1.5版本推出的特性,用來解決處理速度比攝入速度慢的情況,簡單來講就是做流量控制。當批處理時間(Batch Processing Time)大于批次間隔(Batch Interval,即 BatchDuration)時,說明處理數據的速度小于數據攝入的速度,持續時間過長或源頭數據暴增,容易造成數據在內存中堆積,最終導致Executor OOM。反壓就是來解決這個問題的。

spark streaming的消費數據源方式有兩種:
若是基于Receiver的數據源,可以通過設置spark.streaming.receiver.maxRate來控制最大輸入速率;
若是基于Direct的數據源(如Kafka Direct Stream),則可以通過設置spark.streaming.kafka.maxRatePerPartition來控制最大輸入速率。
當然,在事先經過壓測,且流量高峰不會超過預期的情況下,設置這些參數一般沒什么問題。但最大值,不代表是最優值,最好還能根據每個批次處理情況來動態預估下個批次最優速率。
在Spark 1.5.0以上,就可通過背壓機制來實現。開啟反壓機制,即設置spark.streaming.backpressure.enabled為true,Spark Streaming會自動根據處理能力來調整輸入速率,從而在流量高峰時仍能保證最大的吞吐和性能
Spark Streaming的反壓機制中,有以下幾個重要的組件:
RateController
RateController 組件是 JobScheduler 的監聽器,主要監聽集群所有作業的提交、運行、完成情況,并從 BatchInfo 實例中獲取以下信息,交給速率估算器(RateEstimator)做速率的估算。
當前批次任務處理完成的時間戳 (processingEndTime)
該批次從第一個 job 到最后一個 job 的實際處理時長 (processingDelay)
該批次的調度時延,即從被提交到 JobScheduler 到第一個 job 開始處理的時長(schedulingDelay)
該批次輸入數據的總條數(numRecords)
RateEstimator
Spark 2.x 只支持基于 PID 的速率估算器,這里只討論這種實現。基于 PID 的速率估算器簡單地說就是它把收集到的數據(當前批次速率)和一個設定值(上一批次速率)進行比較,然后用它們之間的差計算新的輸入值,估算出一個合適的用于下一批次的流量閾值。這里估算出來的值就是流量的閾值,用于更新每秒能夠處理的最大記錄數
RateLimiter
以上這兩個組件都是在Driver端用于更新最大速度的,而RateLimiter是用于接收到Driver的更新通知之后更新Executor的最大處理速率的組件。RateLimiter是一個抽象類,它并不是Spark本身實現的,而是借助了第三方Google的GuavaRateLimiter來產生的。它實質上是一個限流器,也可以叫做令牌,如果Executor中task每秒計算的速度大于該值則阻塞,如果小于該值則通過,將流數據加入緩存中進行計算。
* 反壓機制真正起作用時需要至少處理一個批:由于反壓機制需要根據當前批的速率,預估新批的速率,所以反壓機制真正起作用前,應至少保證處理一個批。
* 如何保證反壓機制真正起作用前應用不會崩潰:要保證反壓機制真正起作用前應用不會崩潰,需要控制每個批次最大攝入速率。若為Direct Stream,如Kafka Direct Stream,則可以通過spark.streaming.kafka.maxRatePerPartition參數來控制。此參數代表了 每秒每個分區最大攝入的數據條數。假設BatchDuration為10秒,spark.streaming.kafka.maxRatePerPartition為12條,kafka topic 分區數為3個,則一個批(Batch)最大讀取的數據條數為360條(3*12*10=360)。同時,需要注意,該參數也代表了整個應用生命周期中的最大速率,即使是背壓調整的最大值也不會超過該參數。
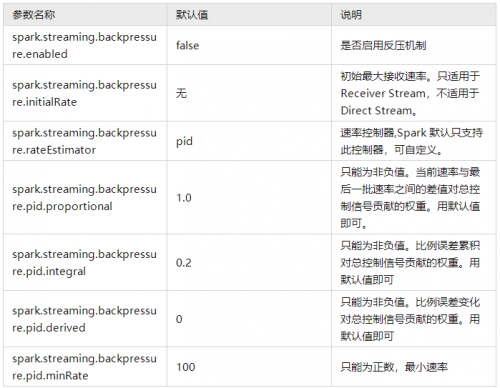
反壓相關的參數
更多關于大數據培訓的問題,歡迎咨詢千鋒教育在線名師,如果想要了解我們的師資、課程、項目實操的話可以點擊咨詢課程顧問,獲取試聽資格來試聽我們的課程,在線零距離接觸千鋒教育大咖名師,讓你輕松從入門到精通。
注:本文部分文字和圖片來源于網絡,如有侵權,請聯系刪除。版權歸原作者所有!














 京公網安備 11010802030320號
京公網安備 11010802030320號