


reduceByKey 可以接收一個 func 函數作為參數,這個函數會作用到每個分區的數據上,即分區內部的數據先進行一輪計算,然后才進行 shuffle 將數據寫入下游分區,再將這個函數作用到下游的分區上,這樣做的目的是減少 shuffle 的數據量,減輕負擔。
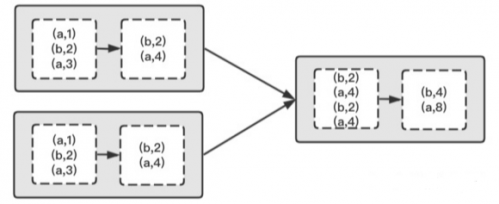
groupByKey 不接收函數,Shuffle 過程所有的數據都會參加,從上游拉去全量數據根據 Key 進行分組寫入下游分區,這樣會消耗比較多的資源,數據傳輸會導致任務處理的延遲。
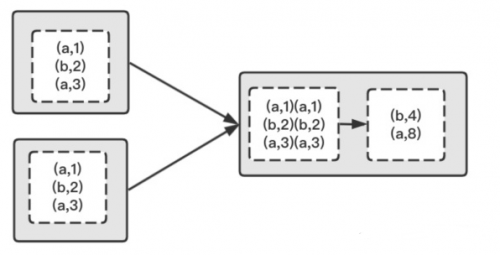
如果我們想要進行分組后進行聚合操作,使用 reduceByKey 會更高效, 因為reduceByKey 會在map階段合并分區內相同的key,而gourpByKey 則不會合并。
更多關于大數據培訓的問題,歡迎咨詢千鋒教育在線名師。千鋒教育擁有多年IT培訓服務經驗,采用全程面授高品質、高體驗培養模式,擁有國內一體化教學管理及學員服務,助力更多學員實現高薪夢想。
注:本文部分文字和圖片來源于網絡,如有侵權,請聯系刪除。版權歸原作者所有!














 京公網安備 11010802030320號
京公網安備 11010802030320號