


現在直播帶貨太火了,宋宋最近也在小紅書上敗家了好幾單,身為程序員的宋宋有點不甘心。拿到了一份小紅書直播帶貨榜數據分析下,看一看小紅書的賣貨實力和用戶分析?本案例主要針對DataFrame的排序知識點的講解。

### 數據排序
在數據分析的使用過程中,數據排序是必不可少的。當然DataFrame就給我提供了一個非常方便的對數據排序的方法,那就是:
sort_index和sort_values方法。在我們講解DataFrame的排序之前,回顧下Series的排序。
Series排序有兩種:一個是sort_index,顧名思義根據Series中的索引對這些值進行排序。另一個是sort_values,根據Series中的值來排序。這兩個方法都會返回一個新的Series。使用Series的排序可以對DataFrame中的某一列進行排序。比如:按照年齡排序
```
df['age'].sort_values() # 獲取age列,并進行排序
```
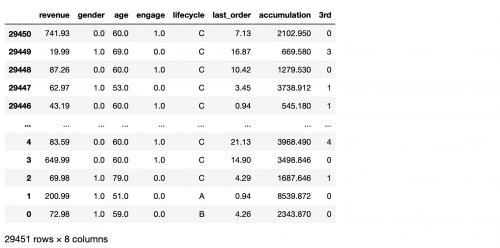
#### 索引排序
對于DataFrame來說也是一樣,同樣有根據值排序以及根據索引排序這兩個功能。但是由于DataFrame是一個二維的數據,所以在使用上會有些不同。最主要的差別是在于Series只有一列,我們明確的知道排序的對象,但是DataFrame不是,它當中的索引就分為兩種,分別是行索引以及列索引。所以我們在排序的時候**需要指定我們想要排序的軸**,也就是axis。
```
df.sort_index(axis=0,ascending=False)
# 其中ascending是用來指定排序的升降序的,默認是升序,如果是降序排列可以使用ascending=False
```
#### 值排序
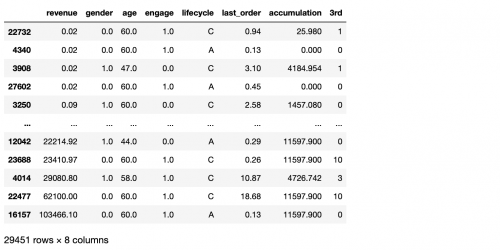
DataFrame的值排序有所不同,我們不能對行進行排序,**只能針對列**。我們通過by參數傳入我們希望排序參照的列,可以是一列也可以是多列。比如:需要按照用戶下單的金額排序,升序排列
```
df.sort_values(by='revenue') # 通過by參數指定排序的列名
```
結果:
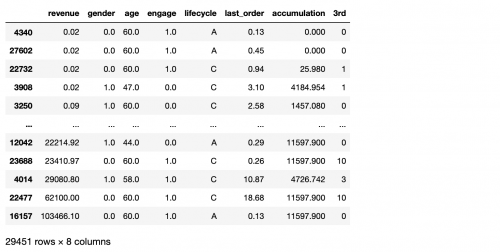
或者是按照用戶下單金額和消費的總金額排序,
```
# 如果排序的列名是多個,則可以使用列表將多個列名放于列表中
df.sort_values(by=['revenue','accumulation'])
```
結果:
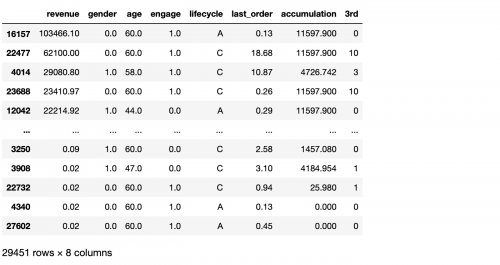
以上排序是默認的升序,如果需要獲取用戶下單金額最高的則需要,則需要降序排列查看。
```
df.sort_values(by=['revenue','accumulation'],asccending=False)
```
當然還可以在sort_values方法中指定,inplace=True 保留排序結果在原數據中,默認是False。也可以指定按照哪個軸排序使用axis,
也可以指定排序的方式是:快速排序、合并排序、堆排序使用kind參數,默認是快速排序。(以下分別是合并排序和快排)

### 數據匯總
DataFrame中的匯總運算也就是**聚合運算**,比如我們最常見的sum方法,對一批數據進行聚合求和。還有mean方法,對數據進行均值運算等等。
> max([axis=1|0])
>
> min([axis=1|0])
>
> sum([axis=1|0])
>
> mean([axis=1|0])
>
> count([axis=1|0])
>
> ....
我們可以使用sum來對DataFrame的行或者列進行求和,如果不傳任何參數,默認是對每一行進行求和,如果需要按照列求和則設置axis=1。比如求過往第三方購買的數量的總和
```python
df['3rd'].sum()
```
結果:
> ```
> 67329
> ```
當然我們也可以獲取用戶的購買金額revenue的均值
```
df['revenue'].mean() # 默認axis=0
```
結果:
> ```
> 398.2981660045499
> ```
獲取用戶注冊6個月內的個數
```
df.loc[df['lifecycle']=='A','lifecycle'].count()
```
結果:
> ```
> 3541
> ```
獲取消費總額最大的金額
```
df['accumulation'].max()
```
結果:
> ```
> 11597.9
> ```
由于DataFrame當中常常會有為NA的元素,所以我們可以通過skipna這個參數排除掉缺失值之后再計算平均值。另外還有一個很好用的方法是descirbe,可以返回DataFrame當中的**整體信息**。比如每一列的均值、樣本數量、標準差、最小值、最大值等等。是一個常用的統計方法,可以用來了解DataFrame當中數據的分布情況。
```
df.describe()
```
結果:
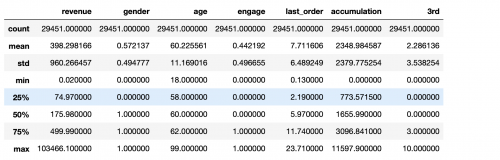
其中std是求標準差,50%求中位數,var()求方差等...
當然我們也可以同時獲取用戶的購買金額revenue的均值和消費總額最大的金額,此時我們需要使用agg方法完成。
```
df.agg({'revenue':np.mean,'accumulation':np.max}) # 參數是一個字典,key為列名,value為要進行的聚合運算
```
結果:
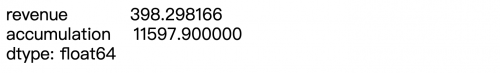
當然更多情況下,agg方法往往是結合分組groupby使用。也不是絕對的,根據實際的情況吧!
更多關于Python 培訓的問題,歡迎咨詢千鋒教育在線名師。千鋒教育擁有多年IT培訓服務經驗,采用全程面授高品質、高體驗培養模式,擁有國內一體化教學管理及學員服務,助力更多學員實現高薪夢想。
注:本文部分文字和圖片來源于網絡,如有侵權,請聯系刪除。版權歸原作者所有!














 京公網安備 11010802030320號
京公網安備 11010802030320號