


在使用Python進行數據分析時,經常會遇到時間日期格式處理、轉換和時間索引,Pandas作為Python環境下的數據分析庫,提供了一套標準的時間序列處理工具和算法,使我們可以非常高效的處理時間序列,比如切片、聚合、重采樣等等。這些強大的日期數據處理功能,是處理日期時間序列的利器。
pandas 支持 4 種常見時間概念:
> 1. 日期時間(Datetime):帶時區的日期時間,類似于標準庫的 `datetime.datetime` 。
> 2. 時間差(Timedelta):絕對時間周期,類似于標準庫的 `datetime.timedelta`。
> 3. 時間段(Timespan):在某一時點以指定頻率定義的時間跨度。
> 4. 日期偏移(Dateoffset):與日歷運算對應的時間段,類似于 `dateutil` 的 `dateutil.relativedelta.relativedelta`。

一般情況下,時間序列主要是 Series 或 DataFrame的時間型索引,可以用時間元素進行操控。
時間戳
時間戳是最基本的時間序列數據,用于把數值與時點關聯在一起。Pandas 對象通過時間戳調用時點數據。
時間戳的創建
在pandas中提供了Timestamp()可以用于創建一個時間戳對象。
import datetime
import pandas as pd
# 三種方式
pd.Timestamp(datetime.datetime(2021, 8, 16)) # 結果: Timestamp('2021-08-16 00:00:00')
pd.Timestamp(2021, 8, 16) # 結果: Timestamp('2021-08-16 00:00:00')
pd.Timestamp('2021-08-16') # 結果: Timestamp('2021-08-16 00:00:00')
to_datetime()轉換得到時間戳
import pandas as pd
pd.to_datetime('2021/08/08') # 結果:Timestamp('2021-08-08 00:00:00')
to_datetime` 轉換單個字符串時,返回的是單個 `Timestamp`。`Timestamp` 僅支持字符串輸入,不支持 `dayfirst`、`format` 等字符串解析選項,如果要使用這些選項,就要用 `to_datetime`。
要實現精準轉換,除了傳遞 `datetime` 字符串,還要指定 `format` 參數,指定此參數還可以加速轉換速度。
pd.to_datetime('2021/08/08', format='%Y/%m/%d')
pd.to_datetime('08-08-2021 00:00', format='%d-%m-%Y %H:%M')
返回結果也是一個`Timestamp`類型。當然如果不可解析則出發錯誤
pd.to_datetime(['2021/08/31', 'abc'], errors='raise') # 報錯ValueError: Unknown string format
轉換多個時間序列
import pandas as pd
pd.to_datetime(pd.Series(["Aug 16, 2021", "2021-08-17", None]))
結果(其中Pandas 用 `NaT` 表示日期時間、時間差及時間段的空值,代表了缺失日期或空日期的值,類似于浮點數的 `np.nan`)
0 2021-08-16
1 2021-08-17
2 NaT
dtype: datetime64[ns]
當然也可以使用如下方式:
pd.to_datetime(["2021/08/16", "2021.08.17"]) #也可以轉成時間戳的格式
返回結果與上面的有所不同,返回值不是一個序列而是一個DatetimeIndex類型
DatetimeIndex(['2021-08-16', '2021-08-17'], dtype='datetime64[ns]', freq=None)
date_range()獲取時間戳范圍
實際工作中,經常要生成含大量時間戳的超長索引,一個個輸入時間戳又枯燥,又低效。如果時間戳是定頻的,用 `date_range()`與 `bdate_range()`函數即可創建 `DatetimeIndex`。`date_range` 默認的頻率是**日歷日**,`bdate_range` 的默認頻率是**工作日
pd.date_range(start=None,end=None,periods=None,freq=None)
Return a fixed frequency DatetimeIndex.
start:表示起始
end:表示結尾
periods:表示時間段
freq:表示有倍數的頻率字符串,e.g. '5H'.
pd.date_range("2021-8-8", periods=8) # 表示從2021-8-8開始到現在日期的8個時間
輸出結果:
DatetimeIndex(['2021-08-08', '2021-08-09', '2021-08-10', '2021-08-11',
'2021-08-12', '2021-08-13', '2021-08-14', '2021-08-15'],
dtype='datetime64[ns]', freq='D')
如果使用bdate_range()則獲取的日期是工作日的日期時間
pd.bdate_range("2021-8-8", periods=8)
結果:
DatetimeIndex(['2021-08-09', '2021-08-10', '2021-08-11', '2021-08-12',
'2021-08-13', '2021-08-16', '2021-08-17', '2021-08-18'],
dtype='datetime64[ns]', freq='B')
如果指定freq,date_range 默認使用的頻率是 日歷日即`D`,也可以通過freq修改成周的。
pd.date_range("2021-8-8", periods=8, freq="W")
輸出結果下:
DatetimeIndex(['2021-08-08', '2021-08-15', '2021-08-22', '2021-08-29',
'2021-09-05', '2021-09-12', '2021-09-19', '2021-09-26'],
dtype='datetime64[ns]', freq='W-SUN')
時間序列的頻率表:

時間段
時間段的創建
pandas提供了`Period`類型,它是基于`numpy.datetime64`編碼的固定頻率間隔。與之相關的索引類型是`PeriodIndex`。`Period` 表示的時間段更直觀,還可以用日期時間格式的字符串進行推斷。默認是月`M`,也可以是天`D`
pd.Period('2021-08')
pd.Period('2021-05', freq='D')
返回:
Period('2021-08', 'M')
Period('2021-05-01', 'D')
時間段的范圍創建
pd.period_range('2020-08',periods=5,freq='M')
pd.period_range('2020-08',periods=5,freq='D')
結果是時間段序列:
PeriodIndex(['2020-08', '2020-09', '2020-10', '2020-11', '2020-12'], dtype='period[M]', freq='M')
PeriodIndex(['2020-08-01', '2020-08-02', '2020-08-03', '2020-08-04',
'2020-08-05'],
dtype='period[D]', freq='D')
Pandas 可以識別兩種表現形式,并在兩者之間進行轉化。Pandas 后臺用 `Timestamp` 實例代表時間戳,用 `DatetimeIndex` 實例代表時間戳序列。pandas 用 `Period` 對象表示符合規律的時間段標量值,用 `PeriodIndex` 表示時間段序列。
時間索引
`DatetimeIndex` 主要用作 pandas 對象的索引。`DatetimeIndex` 類為時間序列做了很多優化:
1. 預計算了各種偏移量的日期范圍,并在后臺緩存,讓后臺生成后續日期范圍的速度非常快(僅需抓取切片)。
2. 在 pandas 對象上使用 `shift` 與 `tshift` 方法進行快速偏移。
3. 合并具有相同頻率的重疊 `DatetimeIndex` 對象的速度非常快(這點對快速數據對齊非常重要)。
4. 通過 `year`、`month` 等屬性快速訪問日期字段。
5. `snap` 等正則函數與超快的 `asof` 邏輯
DatetimeIndex` 可以當作常規索引,支持選擇、切片等方法。
index = pd.date_range('2020-12-01','2021-10-01' , freq='BM') # 指定范圍內的每個月的最后一個工作日
ts = pd.Series(np.random.randn(len(index)), index=index)
輸出結果:
2020-12-31 -0.351660
2021-01-29 0.358744
2021-02-26 0.746602
2021-03-31 0.178684
2021-04-30 -0.408984
2021-05-31 0.117038
2021-06-30 0.661603
2021-07-30 0.655608
2021-08-31 -0.207675
2021-09-30 -0.023105
Freq: BM, dtype: float64
可以支持獲取index和索引切片
display(ts.index)
display(ts[:4].index)
display(ts[::2].index)
輸出結果:
DatetimeIndex(['2020-12-31', '2021-01-29', '2021-02-26', '2021-03-31',
'2021-04-30', '2021-05-31', '2021-06-30', '2021-07-30',
'2021-08-31', '2021-09-30'],
dtype='datetime64[ns]', freq='BM')
DatetimeIndex(['2020-12-31', '2021-01-29', '2021-02-26', '2021-03-31'], dtype='datetime64[ns]', freq='BM')
DatetimeIndex(['2020-12-31', '2021-02-26', '2021-04-30', '2021-06-30',
'2021-08-31'],
dtype='datetime64[ns]', freq='2BM')
當然也可以按照年、月、日獲取時間索引,或者獲取所有的索引的年月等
display(ts['2020'])
display(ts['2021-06'])
display(ts['2020-12':'2021-05'])
display(ts.index.year)
2020-12-31 -0.35166
Freq: BM, dtype: float64
2021-06-30 0.661603
Freq: BM, dtype: float64
2020-12-31 -0.351660
2021-01-29 0.358744
2021-02-26 0.746602
2021-03-31 0.178684
2021-04-30 -0.408984
2021-05-31 0.117038
Freq: BM, dtype: float64
Int64Index([2020, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021], dtype='int64')
當然,`Series` 的值為 `datetime` 時,還可以用 `.dt` 訪問這些屬性。
df = pd.DataFrame(np.random.randn(10000, 2),columns=['A','B'])
df['datetime'] = pd.date_range('20180101', periods=10000, freq='H')
df
輸出結果:
此時可以通過datetime列獲取年月日時分秒等
df['datetime'].dt.year
# df['datetime'].dt.month
# df['datetime'].dt.day
dt的屬性如下表:
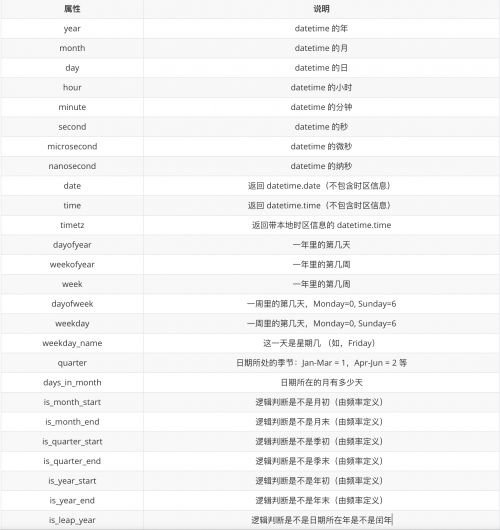
時間差
使用pandas中的Timedelta()函數表示時間差,這個方法與Python基礎中datetime.timedelta是等效的可以互換的在大多數情況下。
以時間差為數據的 `Series` 與 `DataFrame` 支持各種運算,`datetime64 [ns]` 序列或 `Timestamps` 減法運算生成的是`timedelta64 [ns]` 序列
直接使用符號獲取時間差
pd.to_datetime('2021-8-14') - pd.to_datetime('2021-6-1')
返回值就是一個Timedelta類型的
Timedelta('74 days 00:00:00')
如果想在當前的日期前三天或者后5天的值,則需要創建時間差對象
from datetime import datetime
delta = pd.Timedelta('3 days')
display(datetime.now()-delta)
delta1 = pd.Timedelta('30 days')
display(datetime.now()+delta1)
輸出結果(默認是ns作為單位):
datetime.datetime(2021, 8, 14, 15, 21, 9, 875792)
datetime.datetime(2021, 9, 16, 15, 21, 9, 877299)
創建Timedelta()可以支持的unit參數值

delta1 = pd.Timedelta(5,unit='W') # 表示5周后的時間
display(datetime.now()+delta1)
簡單應用:獲取1998-12-20到現在的年齡
age = (datetime.now()- pd.to_datetime('1998-12-20')) / pd.Timedelta(days=365)
print(age)
結果:
22.675737040520104
時間偏移
`DateOffset` 類似于時間差 `Timedelta` ,但遵循指定的日歷日規則。例如,`Timedelta` 表示的每日時間差一直都是 24 小時,而 `DateOffset` 的每日偏移量則是與下一天相同的時間差,使用夏時制時,每日偏移時間有可能是 23 或 24 小時,甚至還有可能是 25 小時。不過,`DateOffset` 子類只能是等于或小于**小時**的時間單位(`Hour`、`Minute`、`Second`、`Milli`、`Micro`、`Nano`),操作類似于 `Timedelta`及對應的絕對時間。
DateOffset` 基礎操作類似于 `dateutil.relativedelta`可按指定的日歷日時間段偏移日期時間。
ts = pd.Timestamp('2016-10-30 00:00:00', tz='Europe/Helsinki') # 其中 tz='Europe/Helsinki'表示夏時制時區
display(ts + pd.Timedelta(days=1))
display(ts + pd.DateOffset(days=1))
輸出結果:
Timestamp('2016-10-30 23:00:00+0200', tz='Europe/Helsinki')
Timestamp('2016-10-31 00:00:00+0200', tz='Europe/Helsinki')
`DateOffset`可用算數運算符(+)或 `apply` 方法執行日期偏移操作。
d = pd.Timestamp('2021-08-15')
two_business_days = 2 * pd.offsets.BDay() # BDay()表示工作日
two_business_days.apply(d) # Timestamp('2021-08-17 00:00:00')
`DateOffset` 還支持 `rollforward()` 與 `rollback()` 方法,按偏移量把某一日期**向前**或**向后**移動至有效偏移日期。例如,工作日偏移滾動日期時會跳過周末(即,星期六與星期日),直接到星期一,因為工作日偏移針對的是工作日。
可以為 `Series` 或 `DatetimeIndex` 里的每個元素應用偏移。
rng = pd.date_range('2021-01-01', '2021-08-16')
s = pd.Series(rng)
s + pd.DateOffset(days=2) # 或者使用s+pd.offsets.Day(2)
輸出結果:
0 2021-01-03
1 2021-01-04
2 2021-01-05
3 2021-01-06
4 2021-01-07
223 2021-08-14
224 2021-08-15
225 2021-08-16
226 2021-08-17
227 2021-08-18
Length: 228, dtype: datetime64[ns]
與時間序列相關的方法
在做時間序列相關的工作時,經常要對時間做一些移動/滯后、頻率轉換、采樣等相關操作,我們來看下這些操作如何使用吧。
移動
如果你想移動或滯后時間序列,你可以使用 shift 方法。
ts = pd.Series(np.random.randn(4), index = pd.date_range('2012-01-01',periods =4, freq ='M'))
print(ts)
2012-01-31 1.132395
2012-02-29 0.740404
2012-03-31 0.154164
2012-04-30 -0.487571
Freq: M, dtype: float64
print(ts.shift(2)) #將數據往后移動, 往前移動則為 ts.shift(-2)
2012-01-31 NaN
2012-02-29 NaN
2012-03-31 1.132395
2012-04-30 0.740404
Freq: M, dtype: float64
當然也可以結合頻度
print(ts.shift(2, freq='M')) # 此時時間增加了2個月
結果:
2012-03-31 1.132395
2012-04-30 0.740404
2012-05-31 0.154164
2012-06-30 -0.487571
Freq: M, dtype: float64
改變頻率
使用函數 `asfreq()`。對于 `DatetimeIndex`,這就是一個調用 `reindex()`,并生成 `date_range` 的便捷打包器。
from pandas.tseries.offsets import *
ts = pd.Series(np.random.randn(2), index = pd.date_range('2021-06-01',periods =2, freq ='w'))
ts.asfreq(Day())
結果(即原來是周顯示,現在將頻率由周轉為了天):
2021-06-06 0.362032
2021-06-07 NaN
2021-06-08 NaN
2021-06-09 NaN
2021-06-10 NaN
2021-06-11 NaN
2021-06-12 NaN
2021-06-13 -1.720824
Freq: D, dtype: float64
你會發現出現了缺失值,因此 Pandas 為你提供了 method 參數來填充缺失值。幾種不同的填充方法參考 Pandas 缺失值處理 中 fillna 介紹
ts.asfreq(Day(), method="pad") # 即使用0.362032填充了NaN的值
結果:
2021-06-06 0.362032
2021-06-07 0.362032
2021-06-08 0.362032
2021-06-09 0.362032
2021-06-10 0.362032
2021-06-11 0.362032
2021-06-12 0.362032
2021-06-13 -1.720824
Freq: D, dtype: float64
重采樣
Pandas 有一個雖然簡單,但卻強大、高效的功能,可在頻率轉換時執行重采樣,如,將秒數據轉換為 5 分鐘數據,這種操作在金融等領域里的應用非常廣泛。
重采樣(resampling)指的是將時間序列從一個頻率轉換到另一個頻率的處理過程。將高頻數據聚合到低頻稱為降采樣(downsampling),將低頻數據轉換到高頻則稱為升采樣(upsampling)。除此以外還存在一種采樣方式既不是升采樣,也不是降采樣,比如`W-WED`轉換成`W-FRI`。
可以通過`resample()`函數來實現,也可以通過更簡單的方式`asfreq()`函數來實現。兩者基本的不同點在于`resample()`是一種數據聚合方式`asfreq()`是一種數據選取方式。
resample() 是基于時間的分組操作,每個組都遵循歸納方法。可以按照分鐘、小時、工作日、周、月、年等來作為日期維度
# 獲取7月1日到7月31日的時間區間
rng = pd.date_range(start='2021/07/1',end='2021/07/31',freq='D')
# 使用此時間區間構建一個Series對象
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
# 獲取此Series對象每5天的數據總和
ts.resample('5D').sum()
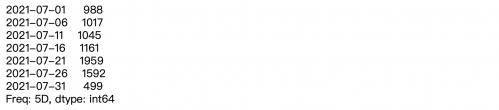
案例演示
AAPL = pd.read_csv('AAPL.csv')
AAPL.Date = pd.to_datetime(AAPL.Date)
AAPL.head()
AAPL['month'] = AAPL.Date.dt.month
AAPL.groupby('month')['Adj Close'].mean() # 每個月份的Adj Close的均值

AAPL.set_index('Date').resample('Y')['Adj Close'].mean() # 獲取每年的Adj Close的均值

如果使用resample進行重采樣,獲取日期每十年`Adj Close`的均值
AAPL.set_index('Date').resample('10Y')['Adj Close'].mean()

AAPL.csv數據回復`時間序列重采樣`獲取
更多關于“Python培訓”的問題,歡迎咨詢千鋒教育在線名師。千鋒教育多年辦學,課程大綱緊跟企業需求,更科學更嚴謹,每年培養泛IT人才近2萬人。不論你是零基礎還是想提升,都可以找到適合的班型,千鋒教育隨時歡迎你來試聽。














 京公網安備 11010802030320號
京公網安備 11010802030320號