


問題復現
在以前的文章中,小千分享了以前在工作中遇到的線上業務BUG解決思路,今天我會結合自己的授信中心這個金融項目,繼續給大家分析如何對自己遇到的故障進行定位與解決,希望本文可以對缺乏實際開發經驗的小白有所幫助。

其實要想解決開發故障,通常的解決思路大致如下:
1.分析問題,根據理論知識+經驗分析問題所在,并將錯誤鎖定在一定的范圍內;
2.通過錯誤日志,快速定位問題。線上定位問題時,主要是依靠監控和日志。
比如小千老師遇到過這樣一個問題:
線上的金融項目啟動后,運行速度越來越慢,一段時間后直接無法訪問,但此時的內存使用率正常,而CPU使用率幾乎滿負荷。在重啟項目后,又運行了一段時間,項目重復出現該問題。
解決思路
對于這種線上的故障,我們該怎么解決呢?其解決思路可以按照以下幾個步驟來實現。
其實,大多數情況下,只要出問題,我們都可以利用 df(查看磁盤)、free(查看內存)、top(查看CPU) 來個素質三連,然后再通過jstack(Java堆棧跟蹤工具)、jmap(Java堆和方法區的詳細信息)等工具排查。這些工具的具體使用命令,大家可以自行查閱。
1.top命令
top命令或者其他監控數據,用于查看服務器的內存、cpu的使用情況。
2.jps命令
查看當前java程序的進程號,假如為:17357,
3.jstat命令
jstat -gc 17357 2000,可以查看jvm的內存分配情況,如圖:

接著我們再通過查看EU和OU、YGC、FGC的變化,來調整jvm的內存、young區(edge,s1,s2)、old區內存大小。
可靠建議:
修改JAVA_OPTS='-Xms1024m -Xmx1024m' ,將jvm的最大、最小內存設為系統內存的3/4。根據ygc,調整young區中s與edge比例,根據fgc的頻率調整young區和old區的大小(或比例)。
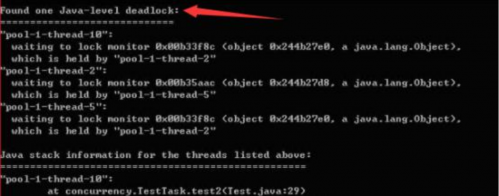
然后通過jstack 進程id,來查看線程的死鎖,例如:jstack -l 21733 | more,若出現下圖所示,則是出現了線程死鎖。
4.tomcat優化
我們也可以在yml文件中tomcat的配置進行優化。
server:
port: 9105
tomcat:
threads:
# 處理請求的最大線程數
max: 350
# 最小的工作線程數
min-spare: 100
# 等待隊列的最大隊列長度
accept-count: 500 5.設置數據庫連接池
對于數據庫服務(如mysql),dba在部署的時候,都會設置db的最大內存和最大鏈接數,開發人員可以暫時忽略。
另外,數據庫連接池請盡量別用dbch、c3p0等已經過時的連接池技術,推薦使用阿里巴巴的druid,其相關的鏈接配置,請參照其github的官網。
具體解決過程
結合以上解決思路,接下來給大家說一下我的具體解決過程。
1.top定位
由于cpu滿負荷,所以我先通過top定位到出現問題的線程。發現確實是我們的java項目所在進程吃掉了所有的cpu資源,這時可通過jps+jstat來查看java的gc狀態,進一步發現young gc幾乎是一秒一次,fullgc沒有。所以接著我又查看了jvm的設置,young內存才設為512m,我先去掉了這個配置,而是采用默認配置(young:old =1:2)。
在重啟項目之后,young gc基本到了10多秒一次,可項目運行一段時間還是會卡死。然后我又看了下tomcat的連接池,發現全部都是默認配置(默認最大連接數為50),故先將最大鏈接設為500,等待隊列設為1000,重啟項目,還是出現cpu滿負荷,系統卡死。
2.排查數據庫服務的內存
接著我查看了輸出的最新日志文件,發現日志輸出到一個dao方法之后,在輸出響應的sql后就卡住了。接著我通過mysql鏈接工具直接執行,sql卻很快輸出,因此排除數據庫服務的內存不足等硬件問題。
3.調整日志輸出級別
通過查看項目的框架,發現日志用的log4j(同步日志輸出),日志輸出級別是:INFO,這會導致項目里面的log輸出非常多,所以我先將log的輸出級別設為warn,重新啟動項目,項目正常運行。
4.優化數據表

修改日志輸出級別為warn之后,運行了一段時間發現系統又卡死了。這時還是兩個表的查詢卡死(通訊錄和通話記錄),這兩個表的存儲量級都是上億級別的,項目原有的邏輯是這樣的,用戶上傳通訊錄,需要刪除原來的通訊錄,再批量插入。這樣一個大表頻繁的進行刪除與批量插入,很容易導致IO響應慢。第一步,我先通過建立唯一索引,利用insert ignore into來減少該表的IO操作,接著重新啟動項目,系統正常運行。
5.添加索引
加好索引優化了sql語句之后,系統還是偶爾會出現卡死狀態。這時,我通過dba搜索慢查詢,發現通話記錄和通訊錄表中有一個排序查詢,該sql的末尾使用了order by update_time desc,但update_time沒有添加索引,這就導致該表的查詢至少要2秒以上。所以我將sql改為了order by id,查詢就正常了,重啟項目,系統正常運行。
6.解決線程死鎖
至此,系統還是偶爾出現卡死現象(cpu爆表),只是頻率小了很多。這時我懷疑是有線程死鎖了,從而導致cpu爆表。我通過運維查找linux線程,終于發現確實有一個線程出現了死鎖,里面的信息顯示是c3p0的連接池線程。我又通過查找資料,發現使用c3p0作為數據庫連接池,經常會出現鏈接池卡死的問題,所以我趕緊將項目的連接池切換為durid,然后重啟項目,項目運行正常。
7.新增服務器節點
但系統在進件量較大時,依然有一定的幾率出現卡死現象,最好考慮是當時的項目環境采用的是單機部署,所以最后協調運維新增了兩個服務器節點,至此項目運行完全正常。
針對線上服務器故障的解決思路和過程,百澤老師給大家提供了以下幾個可靠建議:
系統框架太過于老舊時,可能會引發一系列的項目問題,所以適當升級項目的技術是有必要的;
一些大表一定要進行拆分,否則在高并發的環境中,數據庫的IO會遇到瓶頸;
減少一些不必要的日志輸出,日志輸出組件盡量是異步輸出的;
一些高頻率查詢的字段,盡量加上索引、組合索引,一些慢查詢的sql優化也很重要;
服務盡量單獨部署。


















 京公網安備 11010802030320號
京公網安備 11010802030320號