


1.MapReduce的join過程

miJoin(半連接)
(1):利用DistributedCache將小表分發到各個節點上,在Map過程的setup()函數里,讀取緩存里的文件,只將小表的連接鍵存儲在hashSet中。
(2):在map()函數執行時,對每一條數據進行判斷(包含小表數據),如果這條數據的連接鍵為空或者在hashSet里不存在,那么則認為這條數據無效,這條數據也不參與reduce的過程。
2. hive的SQL解析過程
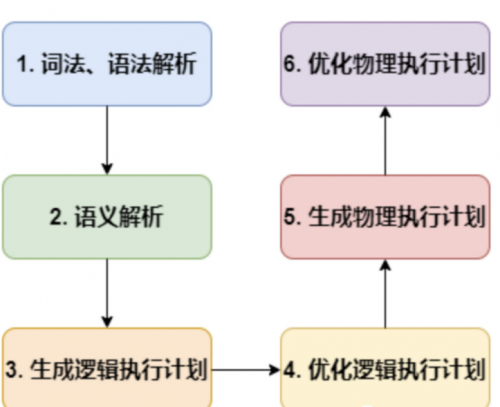
詞法、語法解析:Antlr 定義 SQL 的語法規則,完成 SQL 詞法,語法解析,將 SQL 轉化為抽象語法樹 AST Tree;
語義解析:遍歷 AST Tree(抽象語法樹,抽象語法結構的樹狀),抽象出查詢的基本組成單元 QueryBlock;
生成邏輯執行計劃:遍歷 QueryBlock,翻譯為執行操作樹 OperatorTree;
優化邏輯執行計劃:邏輯層優化器進行 OperatorTree 變換,合并 Operator,達到減少 MapReduce Job,減少數據傳輸及 shuffle 數據量。
更多關于“大數據培訓”的問題,歡迎咨詢千鋒教育在線名師。千鋒教育多年辦學,課程大綱緊跟企業需求,更科學更嚴謹,每年培養泛IT人才近2萬人。不論你是零基礎還是想提升,都可以找到適合的班型,千鋒教育隨時歡迎你來試聽。














 京公網安備 11010802030320號
京公網安備 11010802030320號