


一、分區
指的就是將數據按照表中的某一個字段進行統一歸類,并存儲在表中的不同的位置,也就是說,一個分區就是一類,這一類的數據對應到hdfs存儲上就是對應一個目錄。
1.靜態分區
數據已經按某些字段分完區放在一塊,建表時直接指定分區即可。
create table entercountrypeople(id int,name string,cardNum string)
partitioned by (enter_date string,country string);
注意,這里的分區字段不能包含在表定義字段中,因為在向表中load數據的時候,需要手動指定該字段的值.
2.數據加載(指定分區):
load data inpath '/hadoop/guozy/data/enter_chinapeople' into table entercountrypeople partition (enter_date='2019-01-02',country='china');
此處自動創建分區目錄;
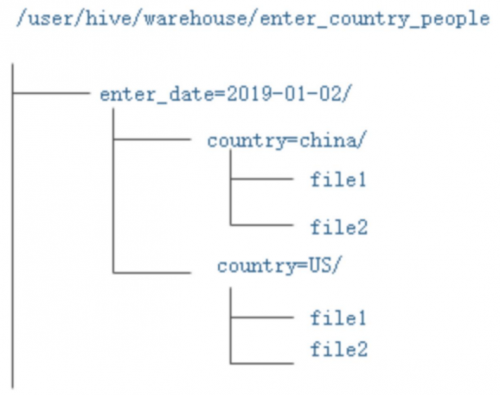
創建完后目錄結構:
其他創建分區目錄的方法:
1)alter table entercountrypeople add if not exists partition (enter_date='2019-01-03',country='US');
2)在相應的表目錄下創建分區目錄后,執行 msck repair table table_name;
2.動態分區
建表相同,主要是加載數據方式不同,動態分區是將大雜燴數據自動加載到不同分區目錄。
1)開啟非嚴格模式
2)要從另一張hive表查詢
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table entercountrypeople(user string,age int) partition(enterdate,country) select user,age,enterdate,country from entercountrypeople_bak;
二、分桶表
如果兩個表根據相同的字段進行分桶,則在對這兩個表進行關聯的時候可以使用map-side關聯高效實現
create table user_bucket(id int comment 'ID',name string comment '姓名',age int comment '年齡') comment '測試分桶' clustered by (id) sorted by (id) into 4 buckets row format delimited fields terminated by '\t';
指定根據id字段進行分桶,并且分為4個桶,并且每個桶內按照id字段升序排序,如果不加sorted by,則桶內不經過排序的,上述語句中為id,根據id進行hash之后在對分桶數量4進行取余來決定該數據存放在哪個桶中,因此每個桶都是整體數據的隨機抽樣。
數據載入:
我們需要借助一個中間表,先將數據load到中間表中,然后通過insert的方式來向分桶表中載入數據。
create table tmp_table (id int comment 'ID',name string comment '名字',age int comment '年齡') comment '測試分桶中間表' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
load data inpath '/hadoop/guoxb/data/user.txt' into table tmp_table;
insert into userbucket select * from tmptable;
上述的語句中,最終會在hdfs上生成四個文件,而不是四個目錄,如果當在次向該分桶表中insert數據后,會又增加4個文件,而不是在原來的文件上進行追加。
三、區別
1.hdfs目錄結構不同,分區是生成目錄,分桶是生成文件
2.分區表在加載數據的時候可以指定加載某一部分數據,有利于查詢
3.分桶在map-side join(另一種 reduce-side join)查詢時,可以直接從bucket(兩表分桶成倍數即可)中提取數據進行關聯操作,查詢高效。
更多關于“大數據培訓”的問題,歡迎咨詢千鋒教育在線名師。千鋒教育多年辦學,課程大綱緊跟企業需求,更科學更嚴謹,每年培養泛IT人才近2萬人。不論你是零基礎還是想提升,都可以找到適合的班型,千鋒教育隨時歡迎你來試聽。














 京公網安備 11010802030320號
京公網安備 11010802030320號