


推薦答案

Pandas是一個基于NumPy的Python數據分析庫,主要用于數據處理、數據分析和數據可視化。它提供了一些簡單易用的數據結構和數據分析工具,可以讓用戶快速地處理和分析數據。下面是Pandas常見的基本使用方法:

1.導入pandas庫

2.讀取數據:可以從多種數據源讀取數據,包括CSV文件、Excel文件、SQL數據庫等。
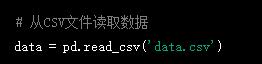
3.查看數據:可以使用head()、tail()等方法查看數據的前幾行或后幾行。

4.數據清洗:可以使用dropna()、fillna()等方法進行數據清洗。

5.數據排序:可以使用sort_values()方法對數據進行排序。

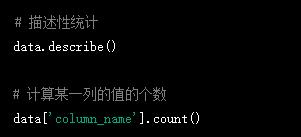
6.數據統計:可以使用describe()、count()等方法對數據進行統計。
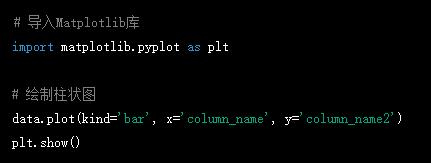
7.數據可視化:可以使用Matplotlib、Seaborn等庫進行數據可視化。
需要注意的是,Pandas還提供了很多高級的功能和方法,比如分組、聚合、透視表、合并等,可以根據具體需求進行使用。
其他答案
-

Pandas中的兩種主要數據類型是Series和DataFrame。Series是一維數組,可以包含各種類型的數據,例如數字、字符串、布爾值等等。DataFrame是由行和列組成的二維表格,可以存儲具有共同類型的數據,例如CSV文件讀取的數據。在使用Pandas進行數據分析時,常常需要使用數據讀取、數據清洗、數據變換、數據聚合以及數據可視化等基本操作。其中,讀取數據可以使用Pandas中的read_csv,read_excel等函數。清洗數據一般包括去除缺失數據、重復數據以及異常值等。數據變換包括數據類型轉換、提取新的特征等。數據聚合可以使用groupby函數實現。最后,數據可視化可以使用Pandas內置的plot函數展示數據趨勢和關系等。
-
pandas是一個用于數據分析的Python庫,它基于NumPy和matplotlib,提供了高效、靈活、易用的數據結構和函數。pandas常見的基本使用方法有:- 導入pandas模塊,一般使用`import pandas as pd`的語句。- 使用pandas的兩種主要數據結構:Series和DataFrame,分別表示一維和二維的數據。可以使用`pd.Series()`和`pd.DataFrame()`來創建這些數據結構,或者使用`pd.read_csv()`等函數來從文件中讀取數據。- 使用pandas的索引、切片、篩選、排序、分組、聚合等操作來對數據進行處理和分析。可以使用`[]`、`loc`、`iloc`等方法來訪問和修改數據,或者使用`sort_values()`、`groupby()`、`agg()`等函數來對數據進行排序、分組和聚合。- 使用pandas的統計、繪圖、缺失值處理、時間序列處理等功能來對數據進行進一步的分析和可視化。可以使用`describe()`、`plot()`、`fillna()`、`to_datetime()`等函數來對數據進行描述性統計、繪制圖表、填充缺失值、轉換為時間序列等。

















最新熱問




 京公網安備 11010802030320號
京公網安備 11010802030320號